
计算机视觉
动手学深度学习v2 - https://www.bilibili.com/video/BV18p4y1h7Dr
个人评价是需要有一点基础
- Pytorch 小土堆 先把Pytorch基础看一下
- 李宏毅2022春机器学习
- 理论部分更推荐李宏毅或者吴恩达,会更好理解
- 我的策略是理论在李宏毅这里补,作业不做,在李沐这里实操一下代码
本文不会放太多理论的东西
记录一下代码实操即可
理论请移步李宏毅课程的相关笔记
硬件
-
CPU角度:避免显式的
for,利用原生代码可以提高并行速度 -
GPU角度:少用控制语句,多计算
-
不要频繁交换CPU、GPU数据
GPU并行训练
- 数据并行:将小批量数据分成若干块,在不同GPU上用同一模型参数进行计算
- 性能更好
- 模型并行:切割模型,不同GPU负责不同部分
- 一般用于模型非常大,单GPU无法支持的情况
- 通道并行(数据+模型并行)
以数据并行为例
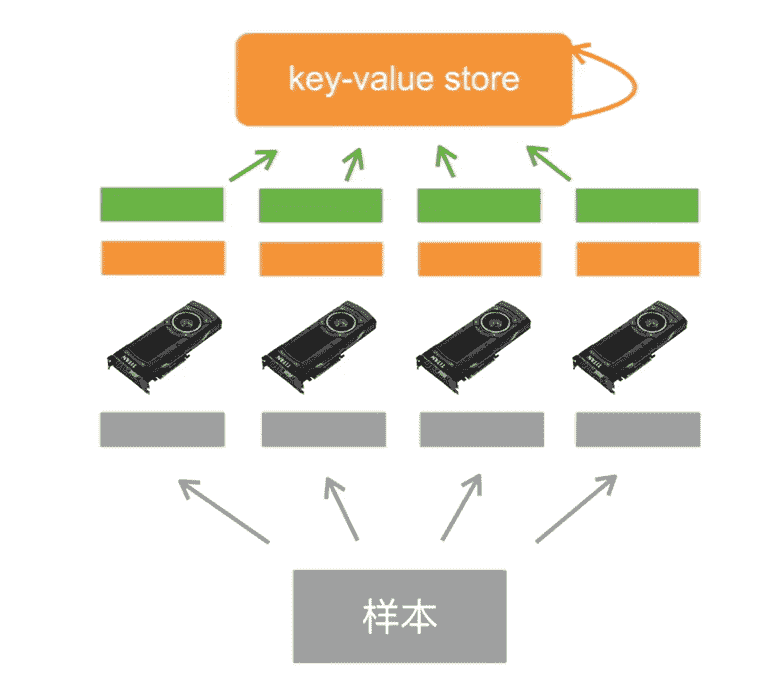
- 切割数据,不同GPU进行数据读取
- 从Key-Value store拿回当前参数
- 并行计算
- 传回梯度
- 更新梯度
代码
1 |
|
训练效果:
1 | ''' |
- 模型副本:在每个GPU上,都会创建一个模型的副本。这些副本共享相同的参数,但每个副本都独立地处理一部分输入数据。
- 结果合并:在所有GPU上的处理完成后自动合并
- 默认是放在0号gpu,因此显存稍微会大一点
注意事项:
- 如果多块GPU的计算能力、显存不一致,需要调节数据划分比例,榨干性能
数据增强
- 对已有数据集进行增强(相当于正则项),添加多样性
代码
1 | # 展示对比 |
- 翻转
1 | # 随机水平翻转 有可能不翻转 |
垂直翻转对于人、动物,或是其他在实际情况下很少倒立的物体,不建议使用
需要结合生产需求,否则没有什么引入噪声的意义
(例如:颜色变化,实际情况确实大概率会因为光线问题而出现,因此有加入此数据增强的必要)

- 裁剪与缩放
1 | trans3 = torchvision.transforms.RandomResizedCrop ( |

- 亮度
1 | print_img( |

通常我们只需要结合多种方法即可:
1 | trans = transforms.Compose([ |
微调
在较大的源数据集上进行训练后得到的预训练模型
可以微调后在较小的(同种类)训练模型上使用
微调时需要加强正则化力度(本身已经训练得差不多了)
- 更小的学习率
- 更少的训练epoch
微调时需要与源数据进行相同的数据增强、数据处理:
1 | # 源数据的性质 可以直接使用 |
需要修改最后的分类层
1 | finetune_net = torchvision.models.resnet18(pretrained=True) |
可以直接冻结底层的梯度
但也可以让底层的学习率更低,高层学习率
1 | params_1x = [ |
计算机视觉
目标检测
-
之前接触是对图片中的单对象进行分类,目标检测需要找到物体的位置、类别
-
使用边缘框进行表示,记录左上角右下角(或左上角、长宽)四个参数
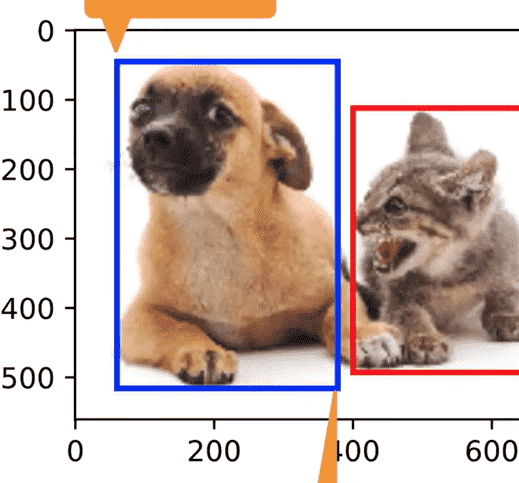
- 批量进行预测时,设定单张图片的预测物体上限
- 超过上限,舍弃
- 低于上限,填充0
- 从而保证返回的物体张量是规则的
锚框
-
边缘框代表真实位置
-
提出多个锚框
- 第一步预测:每个锚框内是否有物体
- 第二步预测:锚框到真实位置的偏移
-
IoU交并比:计算两个框的相似度
-
-
锚框作为训练样本
- 标注:背景(大量,因此噪声非常多)
- 标注:真实边缘框
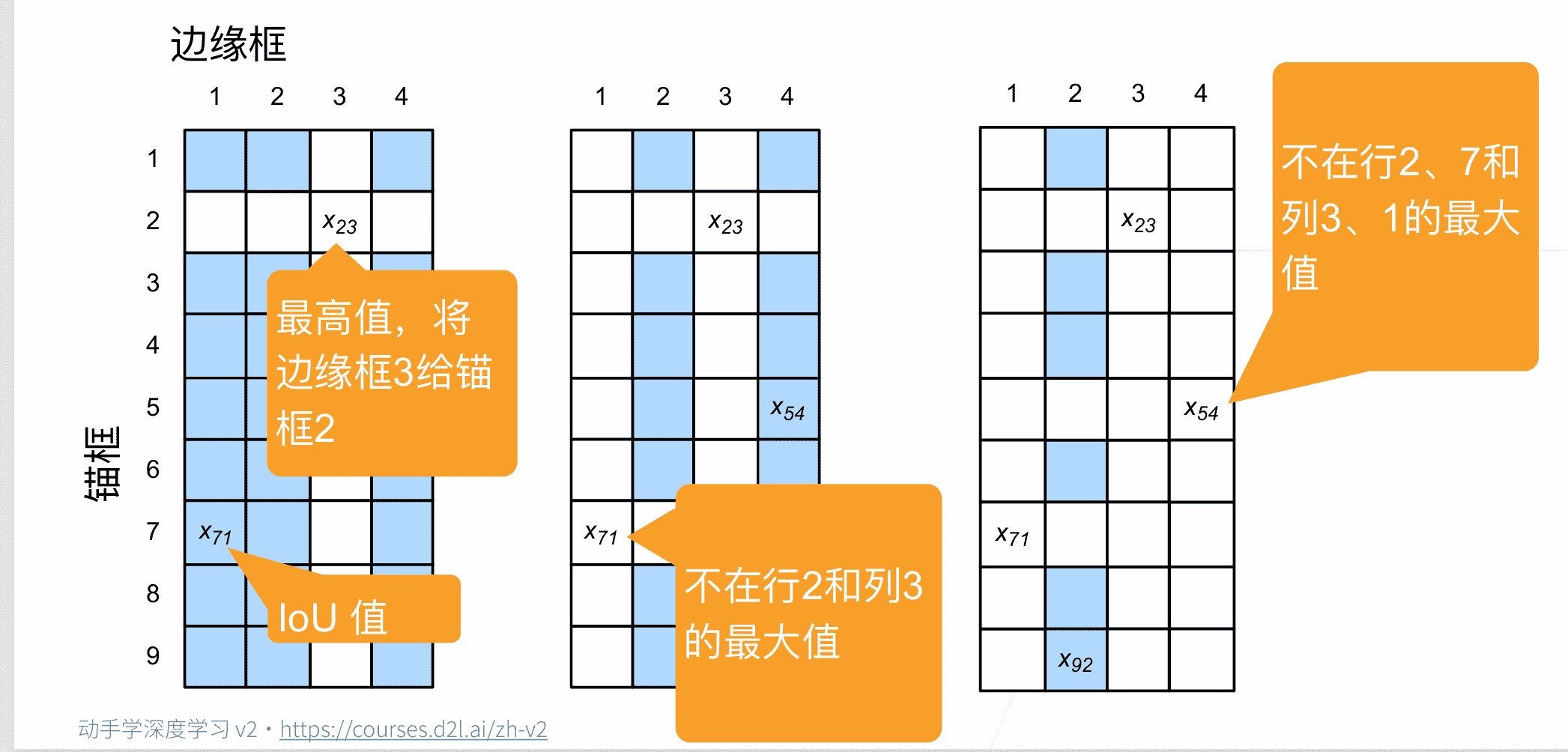
计算每个锚框和边缘框的IoU值,进行最大匹配,匹配完成后删除同行同列
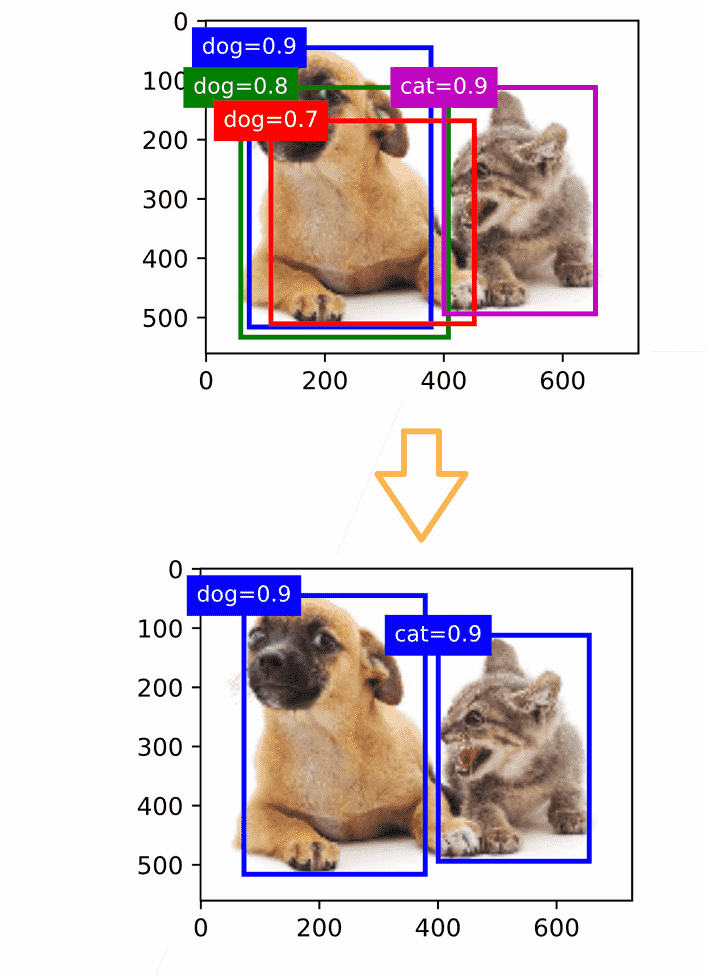
- NMS(非极大值抑制):选择置信度最高的锚框,去除所有与这个锚框IoU大于阈值的其他锚框(避免重复冗余)
物体检测算法
- Two-Stage:R-CNN系算法(Region-based CNN),先通过启发式搜索(或CNN网络)提取出候选锚框,第二阶段再对候选框进行分类、回归,准确度高
- One-Stage:(Yolo和SSD),均匀地在图片的不同位置进行密集抽样,采取不同尺度和长宽比,抽取后使用CNN提取特征后直接进行分类与回归,速度更快
R-CNN
【参考】R-CNN系列算法全面概述(一文搞懂R-CNN、Fast R-CNN、Faster R-CNN的来龙去脉
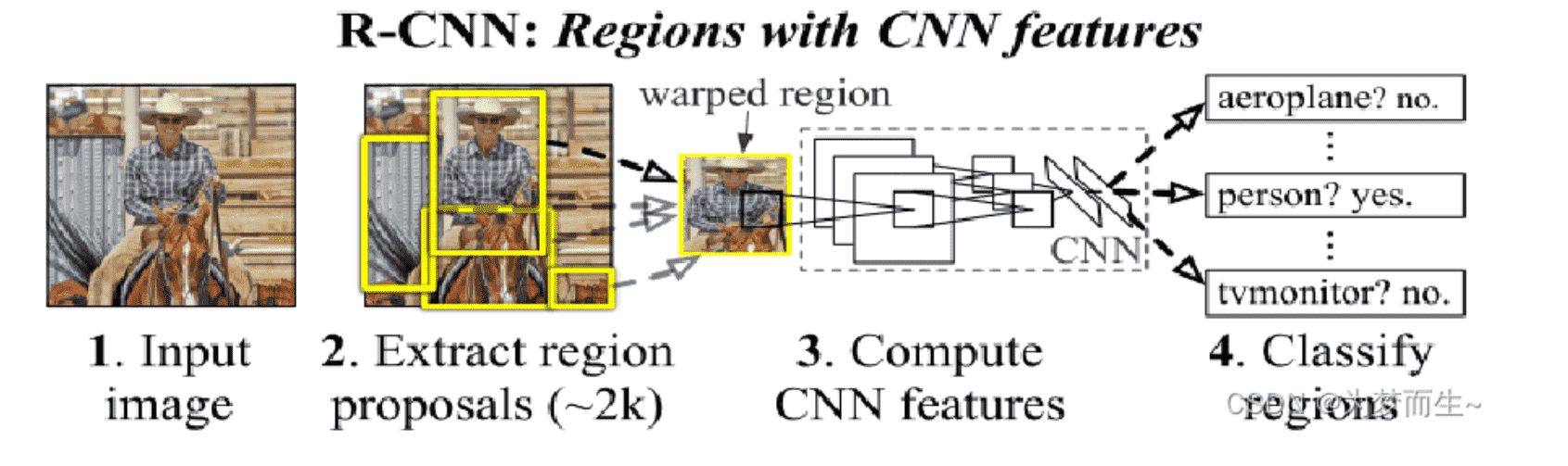
- 抽取一定量的候选框
- 使用CNN提取特征
- 依次送入每个类对应的SVM分类器,判断是否是这一类
- 使用线性回归器,调整锚框偏移位置
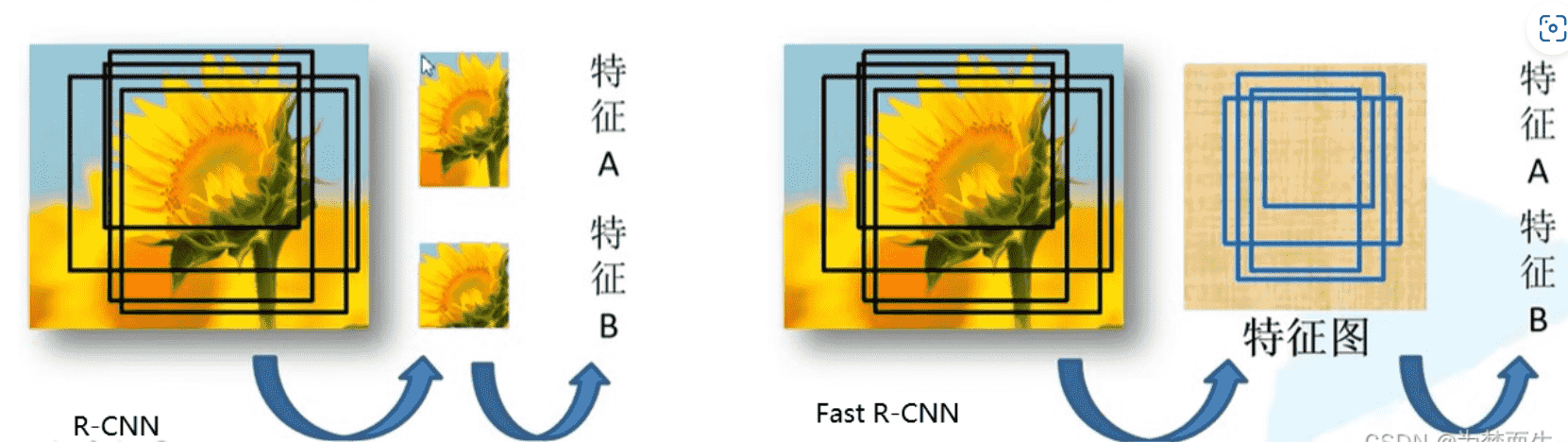
Fast R-CNN
R-CNN将每个候选框都送入CNN进行特征提取
Faster R-CNN将整张图片送入CNN,共享卷积层,重复部分不再计算,直接提取对应值
Fasterr R-CNN
使用**区域提议网络region proposal network(RPN)**得到候选框,其他部分不变
单发多框检测SSD
single-shot 其实是算法一步到位的意思
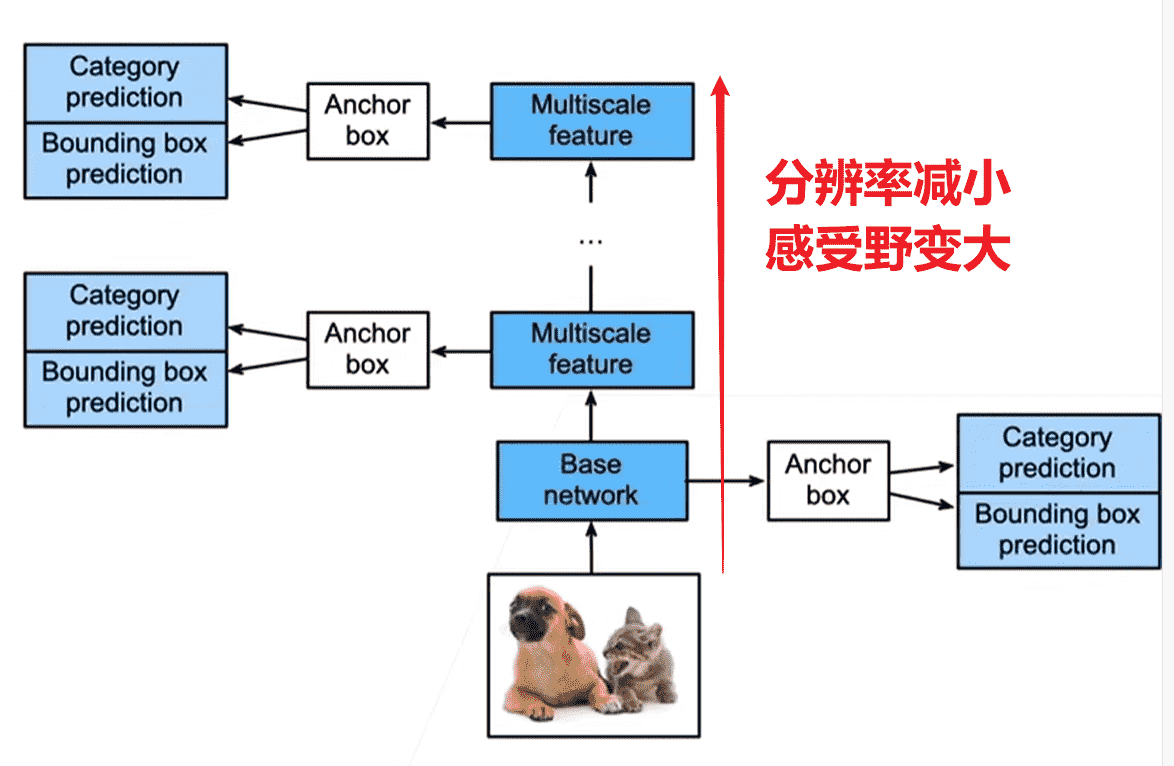
- 对于提取好特征的图片,每个像素将以自己为中心,生成不同大小、高宽比的锚框,进行分类、回归
- 网络没加深一次,就会做一次这样的操作
- 相当于越高层检测的是越大的物体,越底层检测越小的物体
YOLO
- SSD锚框的锚框生成策略导致重复率非常高
- 将当前网络层的图像进行切分为个均匀的锚框,每个锚框检测个边缘框,防止一个锚框内有多个物体
- 其他和SSD差不多
语义分割
检测每个像素属于哪一类
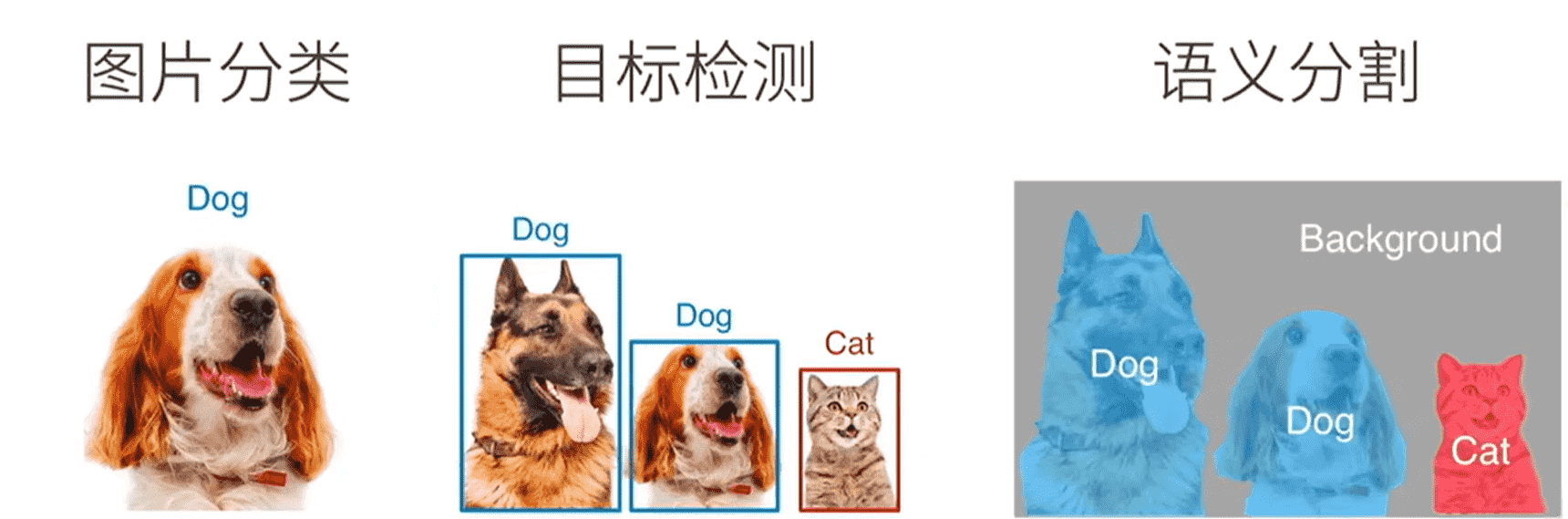
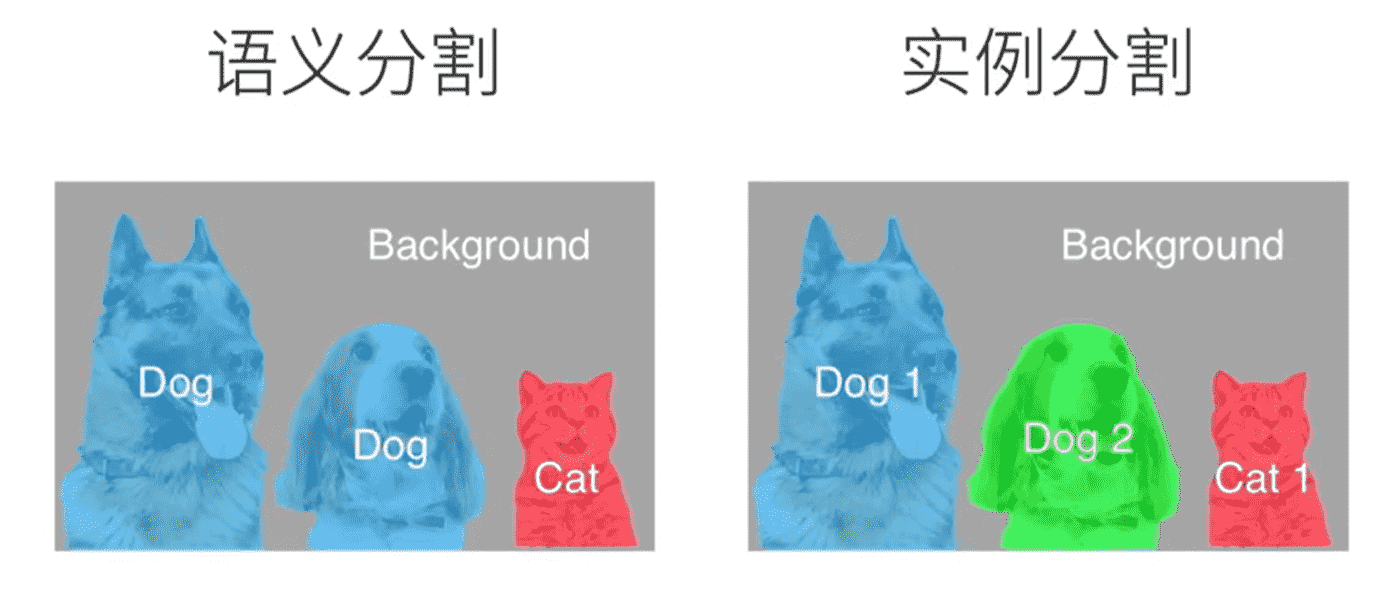
- 实例分割:需要分类出具体是哪个物体
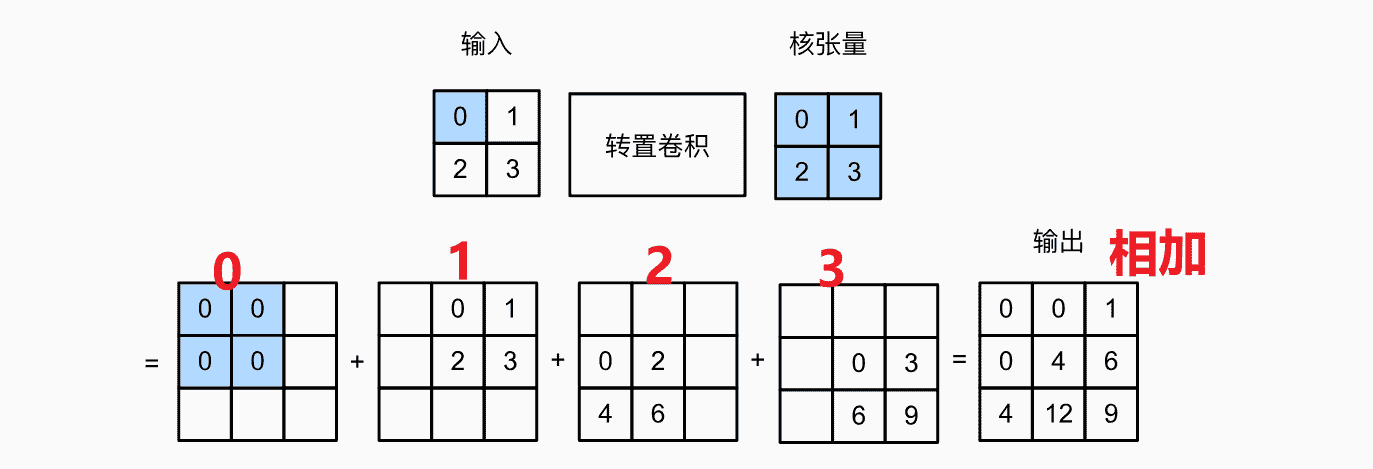
上采样:转置卷积
语义分割需要做像素级别的输出
但是不断卷积会使得feature map变小
以及其他需要增大feature map的操作 我们需要通过上采样进行实现
使用转置矩阵进行变大操作
1 | x = torch.arange(4.) |
对于转置卷积来说,padding相当于删掉最外面一圈数字
1 | tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False) |
原文:卷积操作总结(二)—— 转置卷积(transposed convolution) - 知乎 (zhihu.com)
-
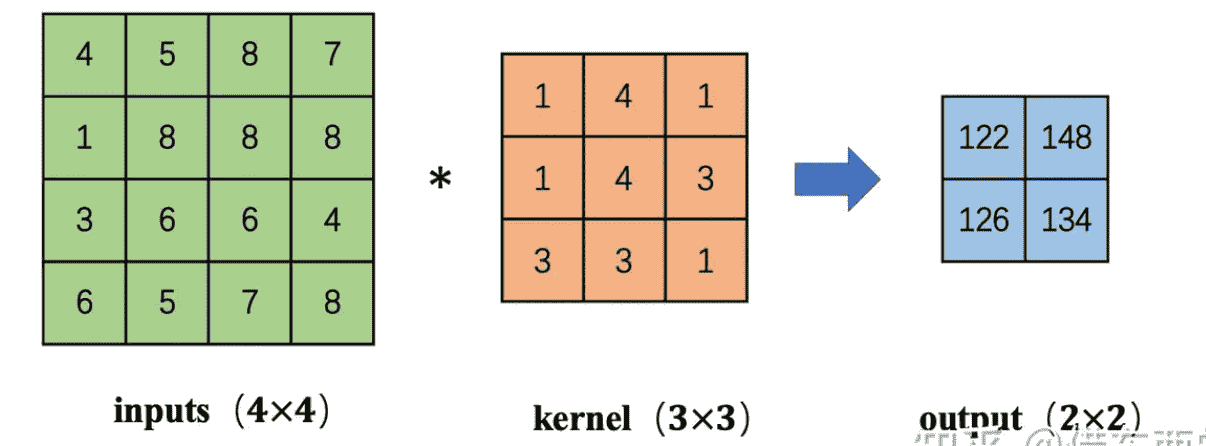
对于一般的卷积操作,会使得feature map减小
-
我们展开inputs成一维向量,kernel展开成二维矩阵,则可以表示为:
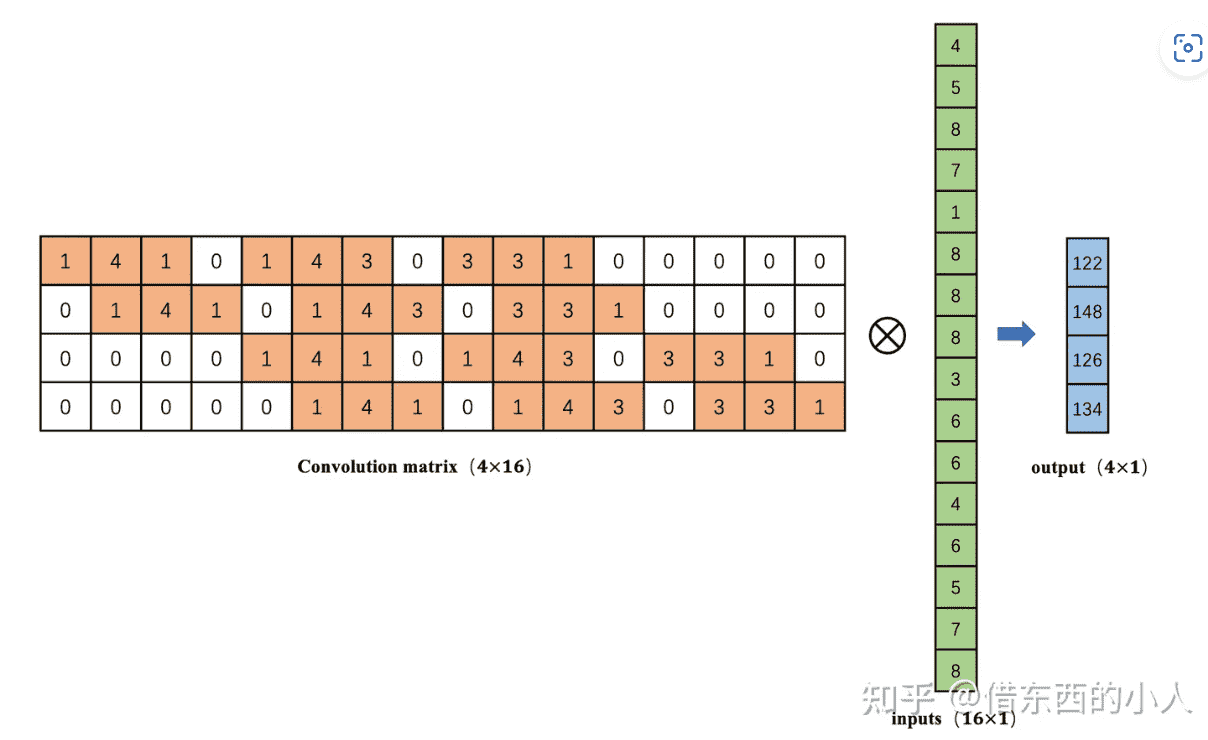
- 卷积操作可以将16维的向量通过矩阵乘法输出一个4维的向量。那么,如何从4维的向量计算得到一个16维的向量呢?
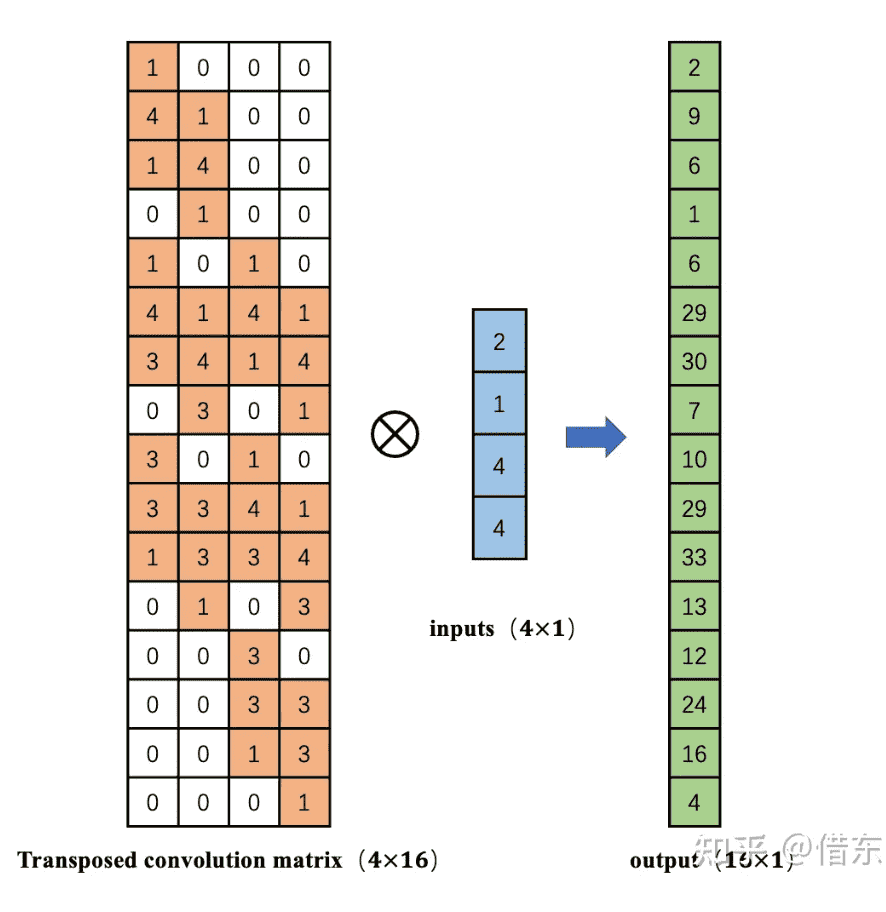
- 转置一下就好了
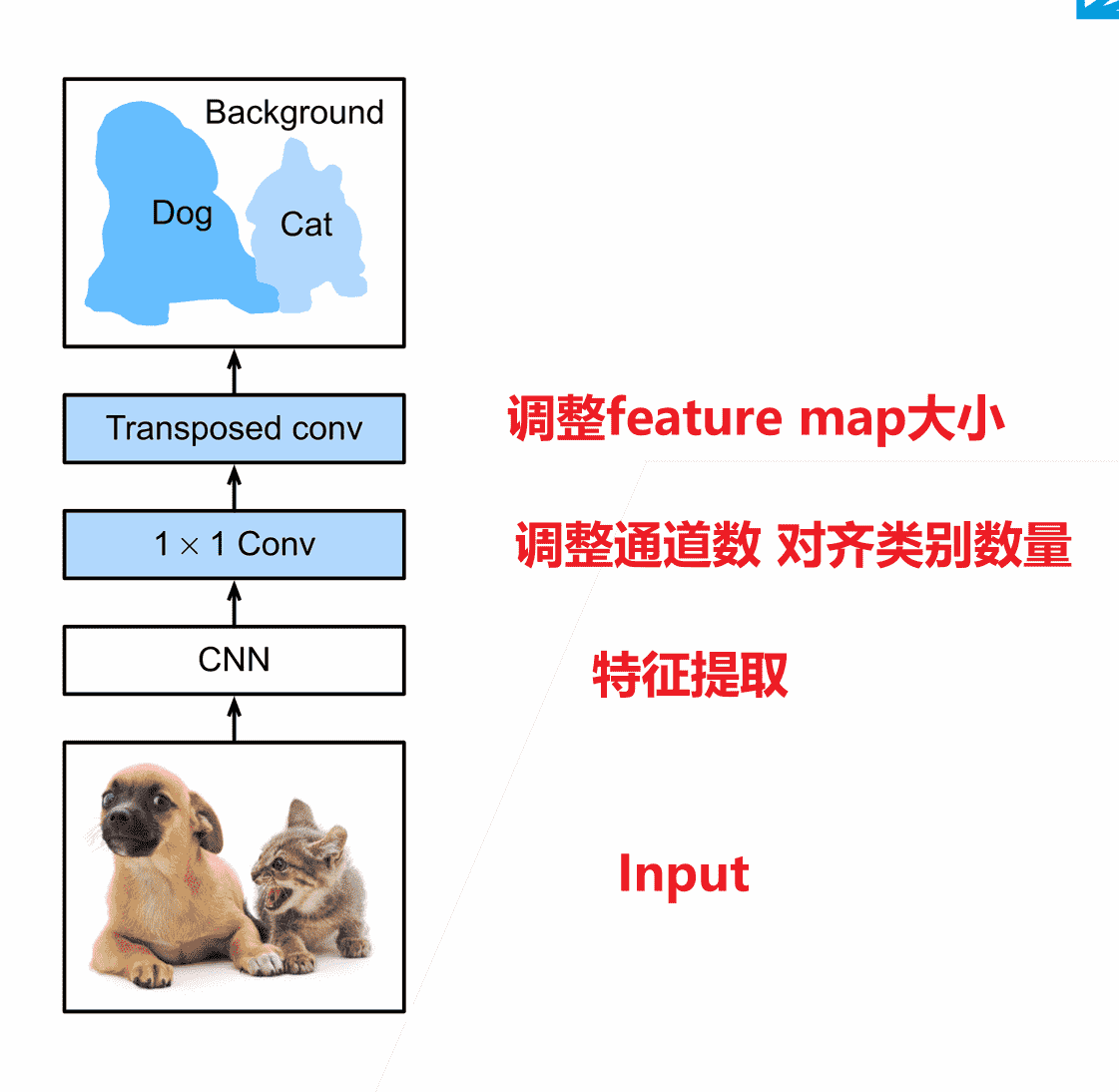
全连接卷积神经网络FCN
- 使用FCN替换全连接网络,实现每个像素的预测
样式迁移
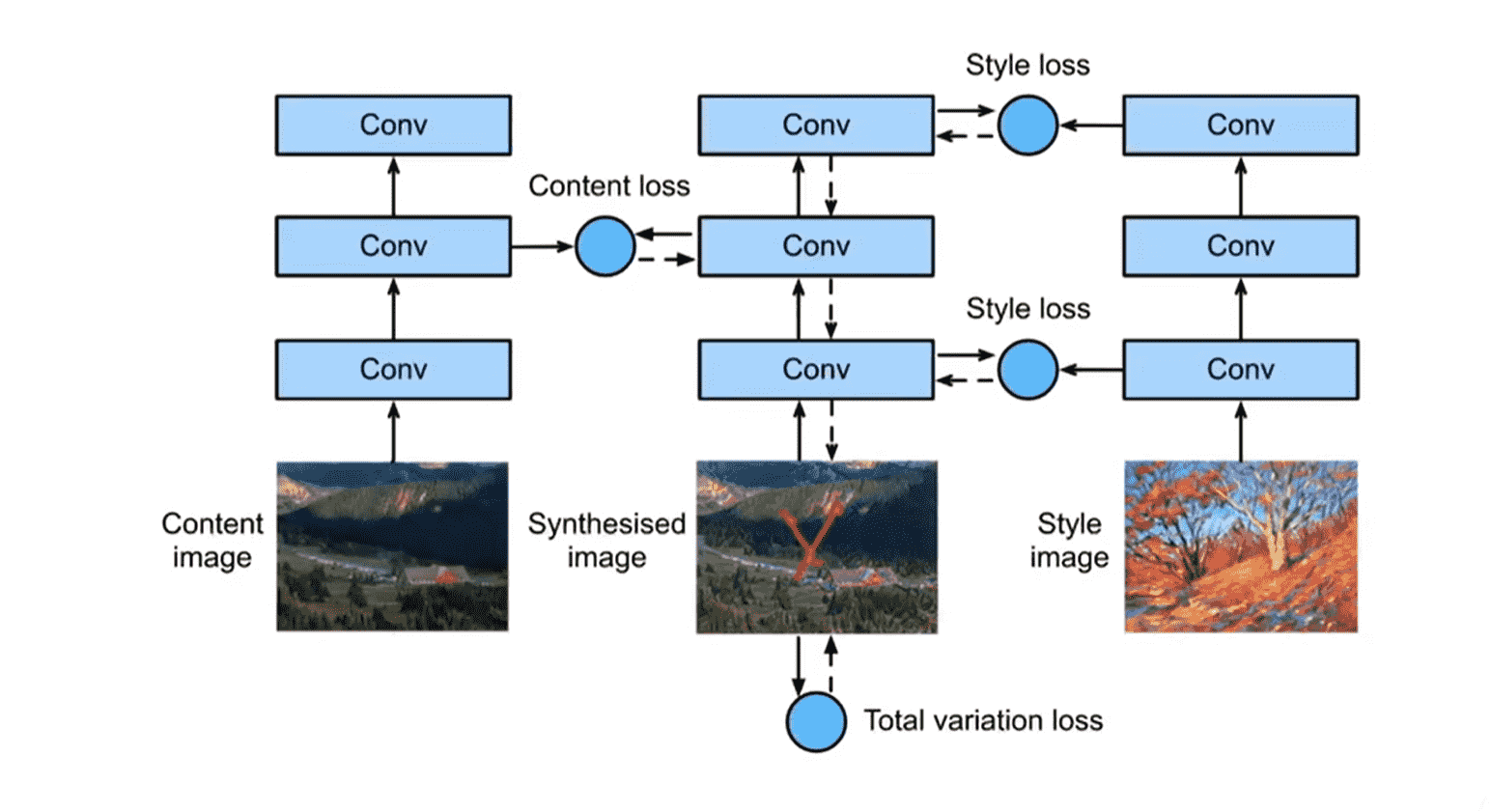
-
左:每层都对图片内容进行特征提取,可以预训练
-
右:每层都对图片样式进行特征提取,可以预训练
-
中间:我们的训练目标就是这个网络,希望做到每一层和左边对于内容的误差尽可能小、和右边对于样式的误差尽可能小,并且需要降低噪点,有一个自己的loss