计算机视觉 · SSD代码实现
动手学深度学习v2 - https://www.bilibili.com/video/BV18p4y1h7Dr
边界框
1
2
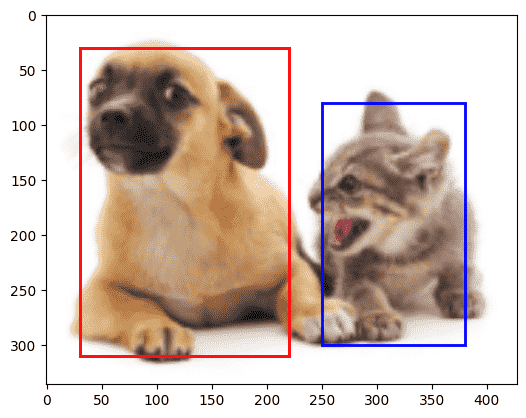
| img = plt.imread('data/dog_cat.png')
plt.imshow(img)
|

边界框的表示有两种:
- 左上角x、左上角y、右下角x、右下角y
- 中心x、中心y、高度、宽度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def box_center_to_corner(boxes):
x,y,w,h = boxes[:,0], boxes[:,1], boxes[:,2], boxes[:,3]
boxes = torch.stack((x - w/2, y - h/2, x + w/2, y + h/2), axis = -1)
return boxes
def box_corner_to_center(boxes):
lx,ly,rx,ry = boxes[:,0], boxes[:,1], boxes[:,2], boxes[:,3]
boxes = torch.stack(((lx+rx)/2, (ly+ry)/2, (rx-lx), (ry-ly)), axis = -1)
return boxes
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor( (dog_bbox, cat_bbox) )
box_center_to_corner( box_corner_to_center(boxes) ) == boxes
|
绘制边缘框
1
2
3
4
5
6
7
8
9
10
| def draw_bbox(bbox, color):
return plt.Rectangle(
xy= ( bbox[0], bbox[1] ),
width = bbox[2] - bbox[0], height = bbox[3] - bbox[1],
fill=False, edgecolor = color, linewidth=2
)
fig = plt.imshow(img)
fig.axes.add_patch( draw_bbox(dog_bbox, 'red') )
fig.axes.add_patch( draw_bbox(cat_bbox, 'blue') )
|
数据集
下载地址:香蕉数据集
1
2
3
4
5
6
7
| data/banana-detection/
├── bananas_train
│ ├── images/
│ └── label.csv
└── bananas_val
├── images/
└── label.csv
|
训练集和验证集已经切分好了,csv格式如下
1
| img_name,label,xmin,ymin,xmax,ymax
|
读取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def read_data(is_Train=True):
data_dir = 'data/banana-detection'
data_dir = os.path.join( data_dir, 'bananas_train' if is_Train else 'bananas_val')
csv_dir = os.path.join(data_dir, 'label.csv')
csv_data = pd.read_csv(csv_dir).set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
targets.append(list(target))
images.append(
torchvision.io.read_image(
os.path.join(data_dir, "images", img_name)
)
)
return images, torch.tensor(targets).unsqueeze(1)/256
read_data()
|
Dataset
1
2
3
4
5
6
7
8
9
10
| class BananaDataset(Dataset):
def __init__(self, isTrain) -> None:
super().__init__()
self.features, self.labels = read_data(isTrain)
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx].float(), self.labels[idx]
|
DataLoader
1
2
3
4
5
6
| batch_size = 32
train_loader = DataLoader(BananaDataset(isTrain=True), batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(BananaDataset(isTrain=False), batch_size, num_workers=4)
|
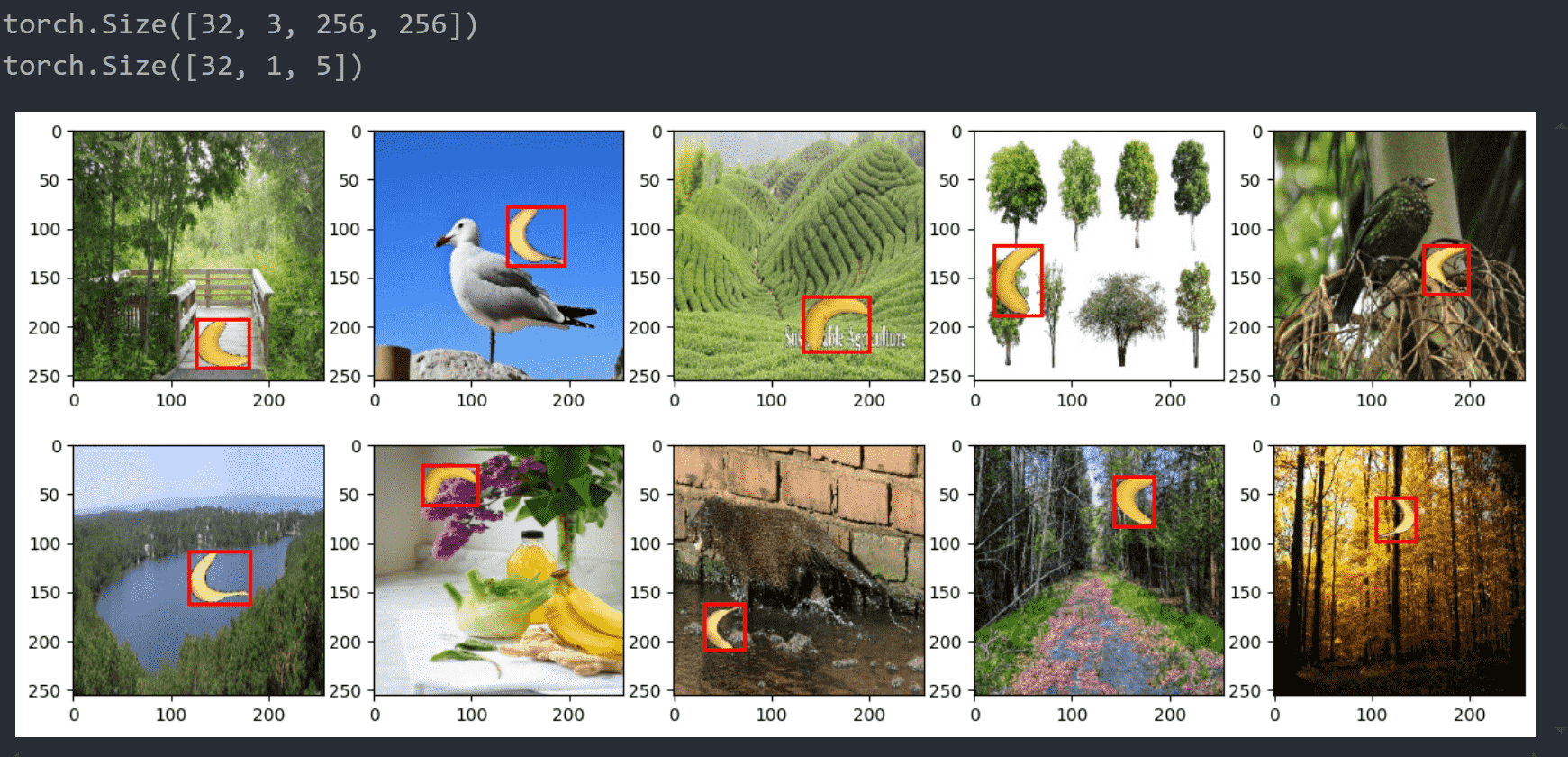
读取后的图片如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| x = next(iter(train_loader))
print(x[0].shape)
print(x[1].shape)
images = x[0]
labels = x[1]
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
edge_size = 256
for i in range(10):
img = images[i].permute(1, 2, 0).numpy() / 255
ax = axes[i // 5, i % 5]
ax.add_patch( draw_bbox(labels[i][0][1:5] * edge_size, 'red') )
ax.imshow(img)
plt.show()
|
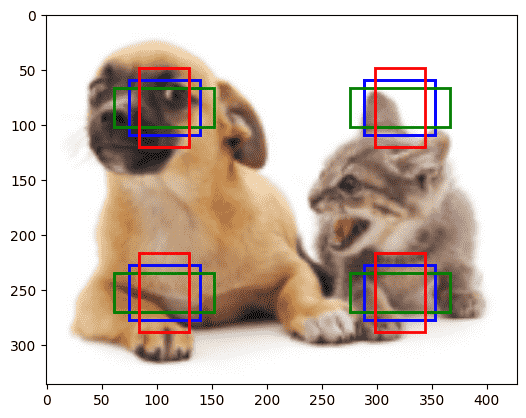
锚框
生成
使用SSD,每个像素以自己为中心,生成若干个不同缩放、高宽比的锚框
记s=(s1,s2,s3,...,sn),r=(r1,r2,...,rm)
则搭配的方案为:
(s1,r1),(s1,r2),...,(s1,rm)
和
(s2,r1),(s2,r1),...,(sn,r1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| def multibox_prior(data, sizes, ratios):
in_height, in_width = data.shape[-2]
device, sizes_len, ratios_len = data.device, len(sizes), len(ratios)
boxes_per_pixel = sizes_len + ratios_len - 1
sizes = torch.tensor(sizes, device=device)
ratios = torch.tensor(ratios, device=device)
steps_h, steps_w = 1.0 / in_height, 1.0 / in_width
center_h = (torch.arange(in_height, device=device) + 0.5) * steps_h
center_w = (torch.arange(in_width, device=device) + 0.5) * steps_w
shift_x, shift_y = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
w = torch.cat((sizes * torch.sqrt(ratios[0]), sizes[0] * torch.sqrt(ratios[1:]))) * in_height / in_width
h = torch.cat((sizes / torch.sqrt(ratios[0]), sizes[0] / torch.sqrt(ratios[1:])))
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat( in_height * in_width, 1) / 2
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output
|
绘制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| img = plt.imread('data/dog_cat.png')
h,w = img.shape[:2]
def show_bboxes(img, anchors, fmap_w, fmap_h):
fig = plt.imshow(img)
nums = len(anchors) // (fmap_w * fmap_h)
colors = ['b','g','r','c','m','y','k','w'][:nums]
for i in range(len(anchors)):
fig.axes.add_patch( draw_bbox(anchors[i], colors[i%nums]) )
def display_anchors(fmap_w, fmap_h, s):
fmap = torch.zeros((1, 10, fmap_h, fmap_w))
anchors = multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = torch.tensor((w, h, w, h))
show_bboxes(img, anchors[0] * bbox_scale, fmap_w, fmap_h)
display_anchors(fmap_w=4, fmap_h=4, s=[0.15])
|

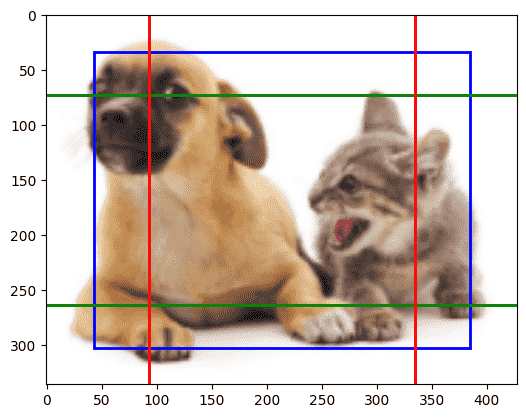
1
| display_anchors(fmap_w=2, fmap_h=2, s=[0.15])
|
1
| display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
|
交并比IoU
锚框画出来需要进行评价,显然和真实边界框越相近就越好
使用交并比进行比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def box_iou(boxes1, boxes2):
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1]))
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
|
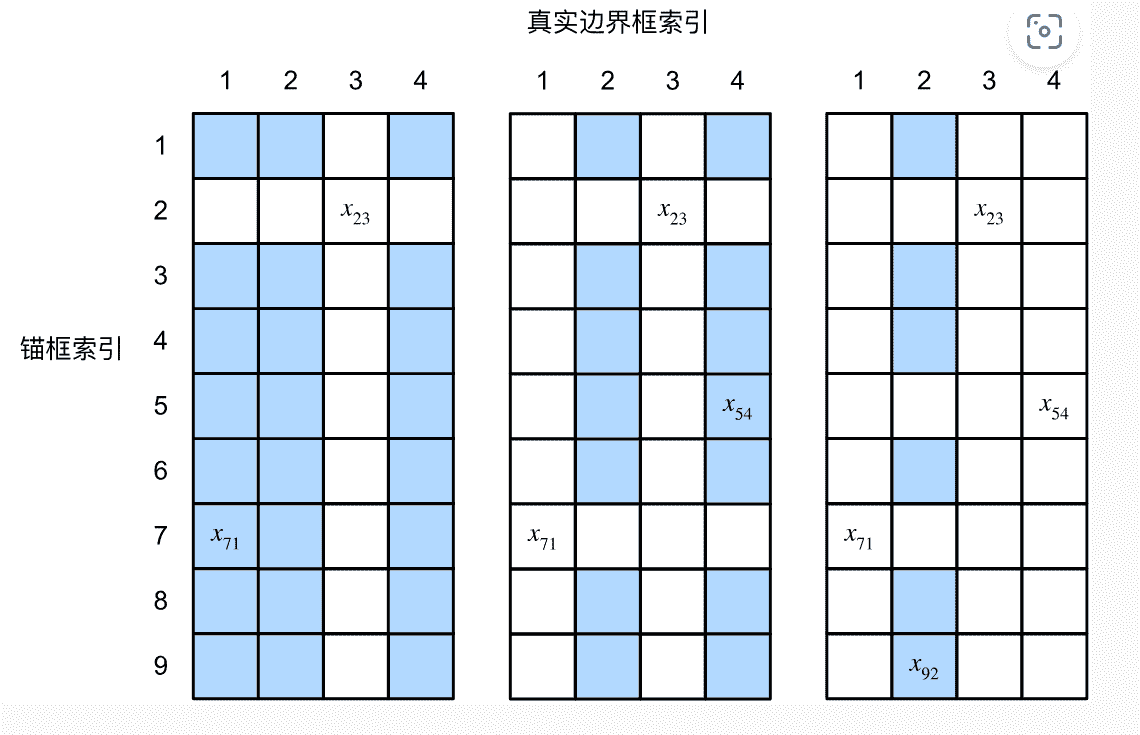
锚框绑定
对于给定真实边界框数据集,我们实际上会对每个锚框进行绑定
我们将每个锚框视作一个训练样本,其类别为绑定的边界框的类别标签,其偏移值为锚框到边界框的偏移
具体绑定做法见理论部分的笔记
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
jaccard = box_iou(anchors, ground_truth)
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long, device=device)
max_ious, indices = torch.max(jaccard, dim=1)
anc_i = torch.nonzero(max_ious >= iou_threshold).reshape(-1)
box_j = indices[max_ious >= iou_threshold]
anchors_bbox_map[anc_i] = box_j
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
|
1
2
3
4
5
6
7
8
| def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = box_corner_to_center(anchors)
c_assigned_bb = box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
|
如果一个锚框没有被分配到边界框,则我们标记其为背景
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
indices_true = torch.nonzero(anchors_bbox_map >= 0)
bb_idx = anchors_bbox_map[indices_true]
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
|
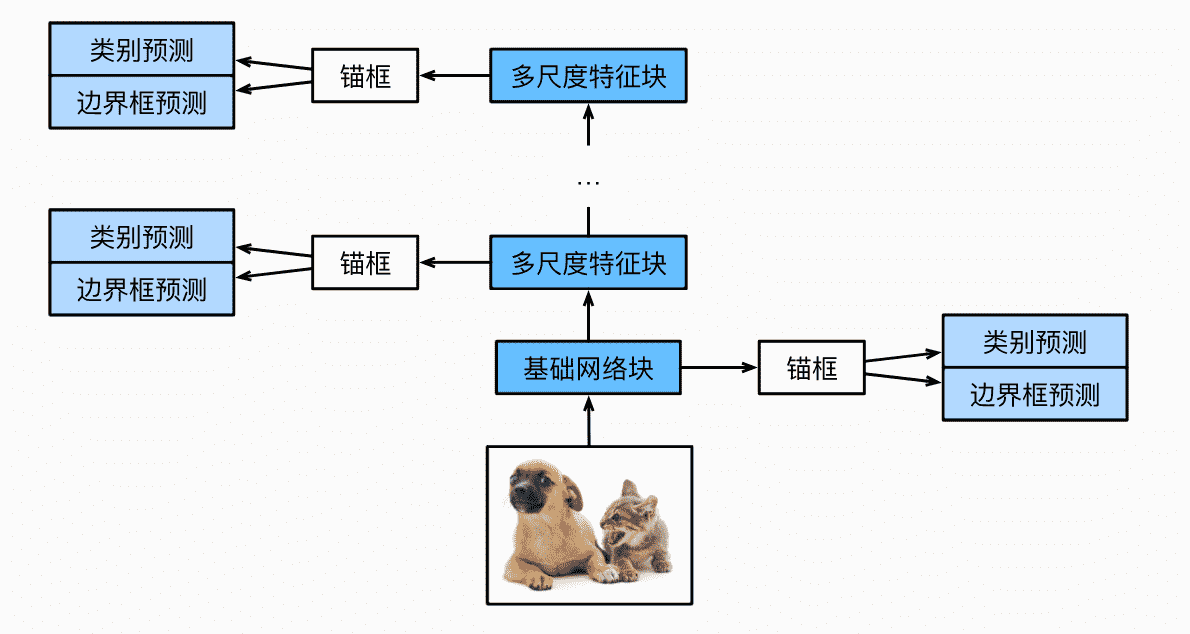
网络
类别预测层
对于每一层,feature map若是h×w的图片,每个像素生成a个锚框,预测q个类别,若使用全连接层,参数量hwa(q+1)(0类是背景),非常恐怖
需要像之前一样通过通道数表达神经元的方法,进行网络优化
- 输入:输入本身就是h×w的feature map,因此能够对应上
- 输出通道:对于每个锚框需要输出q+1个概率,因此通道数为a(q+1)
1
| nn.Conv2d(num_inputs, num_anchors * (num_classes + 1), kernel_size=3, padding=1)
|
边界框预测层
同理,但是输出为4,代表四个锚框坐标和边界框的偏移量
1
| nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
|
高宽减半块(下采样)
网络提升时,需要不断下采样,增大感受野
实际上用的是VGG
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))
return nn.Sequential(*blk)
block = down_sample_blk(3, 10)
block( torch.zeros(32, 3, 100, 100) ).shape
|
基本网络块
设计在第一次对图片进行特征提取,后续的网络块并不会进行过多卷积
选择叠加3次高宽减半层,每次把通道数翻倍
1
2
3
4
5
6
7
8
9
10
| def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)
block = base_net()
block( torch.zeros(32, 3, 256, 256) ).shape
|
网络框架
网络一共5块,每一个块都需要生成锚框,进行分类、预测
- 基本网络块:高宽32,32
- 高宽减半块(64,128):高宽16,16
- 高宽减半块(128,128):高宽8,8
- 高宽减半块(128,128)):高宽4,4
- 全局池化:高宽降到1
1
2
3
4
5
6
7
8
9
10
| def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i <= 3:
blk = down_sample_blk(128, 128)
else:
blk = nn.AdaptiveMaxPool2d((1,1))
return blk
|
Model
模型的输出非常多,对于每一层都需要输出:
其中后三个会保留到最后的所有输出内
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs) -> None:
super().__init__(**kwargs)
self.num_classes = num_classes
self.blk, self.cls, self.predictor = nn.ModuleList(), nn.ModuleList(), nn.ModuleList()
in_channels = [64, 128, 128, 128, 128]
for i in range(5):
self.blk.append( get_blk(i) )
self.cls.append( nn.Conv2d( in_channels[i], num_anchors * (num_classes + 1), kernel_size=3, padding=1) )
self.predictor.append( nn.Conv2d( in_channels[i], num_anchors * 4, kernel_size=3, padding=1) )
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
X = self.blk[i](X)
anchors[i] = multibox_prior(X, sizes = sizes[i], ratios = ratios[i] )
cls_preds[i] = self.cls[i](X)
bbox_preds[i] = self.predictor[i](X)
anchors = torch.cat(anchors, dim = 1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1
)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
|
训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
cls_loss = nn.CrossEntropyLoss(reduction='none')
bbox_loss = nn.L1Loss(reduction='none')
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = cls_loss(
cls_preds.reshape(-1, num_classes),
cls_labels.reshape(-1)
).reshape(batch_size, -1).mean(dim=1)
bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox
def cls_eval(cls_preds, cls_labels):
return float((cls_preds.argmax(dim=-1).type(cls_labels.dtype) == cls_labels).sum())
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
|
需要对预测结果reshape后,分别计算出对应的分类误差和回归误差,相加则得到我们需要的误差
