
L4. Sequence as input
Sequence
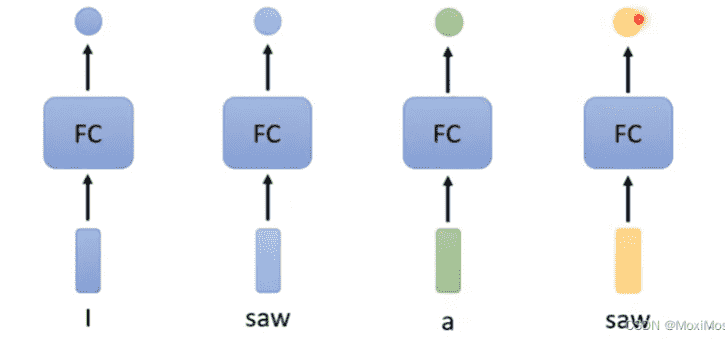
对于Sequence Labeling任务,我们需要对一段文本中的所有单词标注词性。
- 显然不能单独考虑一个单词,需要结合上下文
- 同一个单词在不同的上下文中会有不同的词性
- 我们考虑定义一个window:
- 每个Fully-Connected需要连接前后若干个单词作为输入
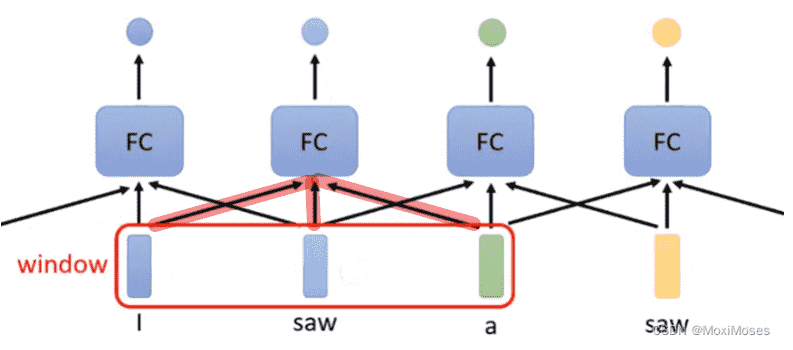
- 但是我们有时需要考虑整个Sequence去获得信息,我们很难通过扩大Window进行操作,复杂度会非常高
Self-Attention
概述
- 整个Sequence作为输入
- 输出向量数量等于输入向量
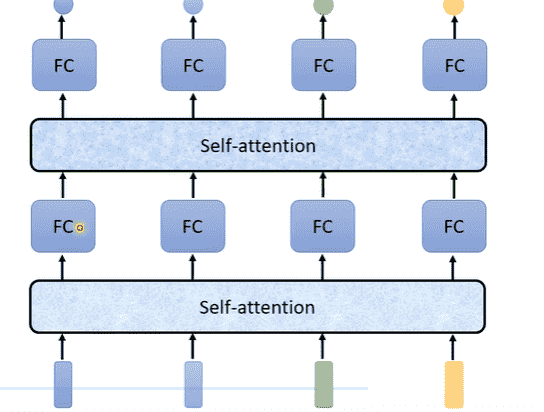
- 每次完成Self-Attention后,喂入FC进行操作
- 可以多次叠加
Dot-Product
我们会对多个输入向量之间的相关性感兴趣
Self-Attention常使用Dot-Product求出两个向量之间的相关性
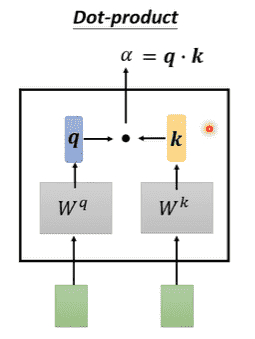
- 两个输入向量分别乘上,得到向量
- 对向量进行点积,得到,同时也被称为attention-score
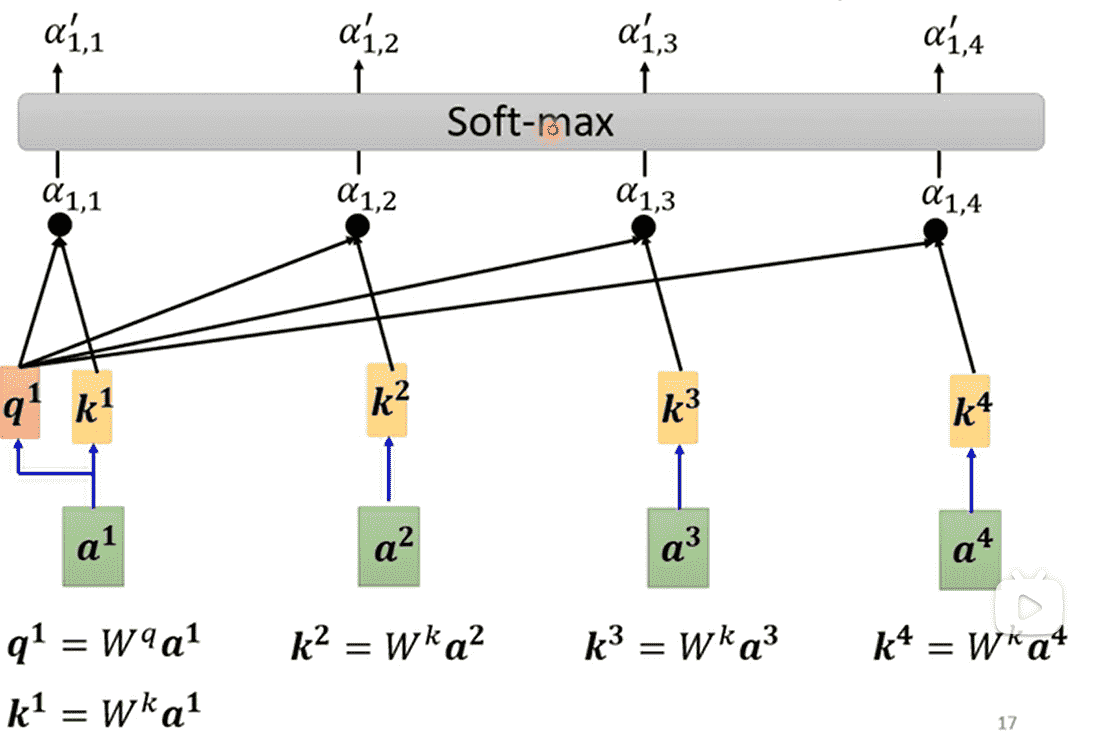
Forward
-
对于其中一个向量,计算出自己作为查询向量的值
-
所有向量都需要计算自己作为被查询向量的值
-
通过Dot-Product,得到,即向量对所有向量的相关性
-
做一下Softmax,得到
-
每个向量都需要通过矩阵计算出向量
-
乘上标量,求和
-
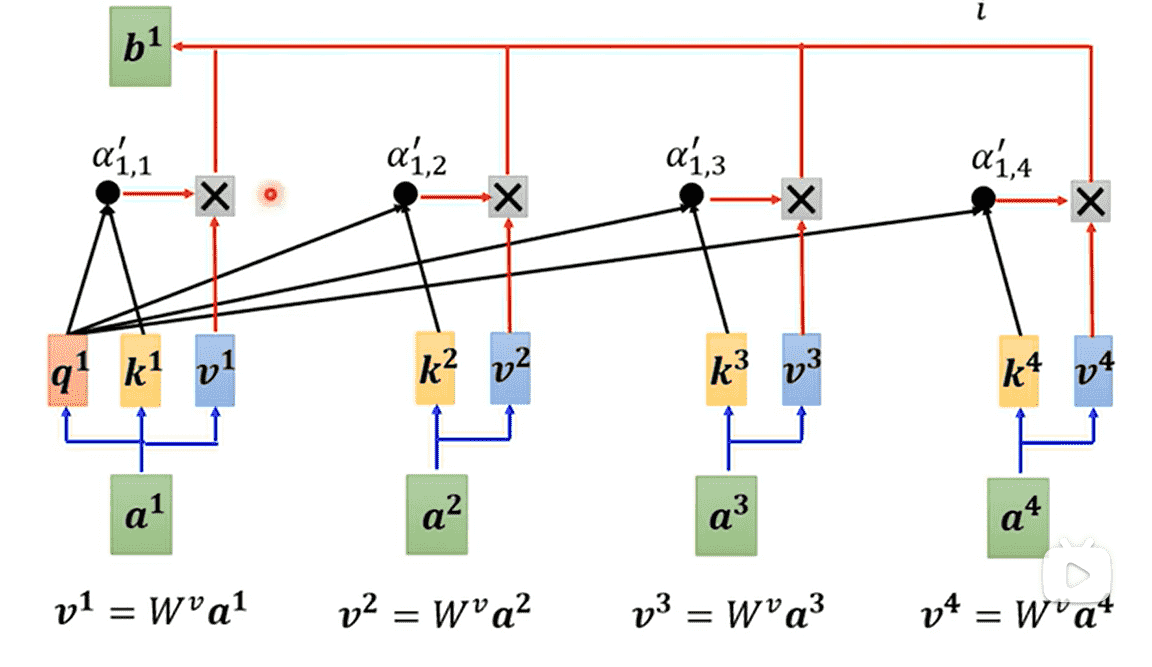
- 关联性越高的向量,它会占有很大的成分
每个向量得到的计算过程是并行进行的
Forward(矩阵形式)
- 都是通用的,每个向量都需要使用,因此很容易就能表示成矩阵形式
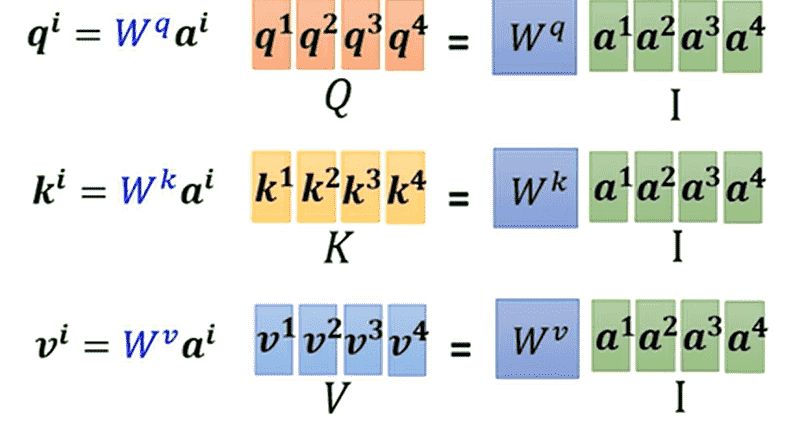
- 对于,我需要让它与所有进行点积运算
- 实质上就是与进行相乘
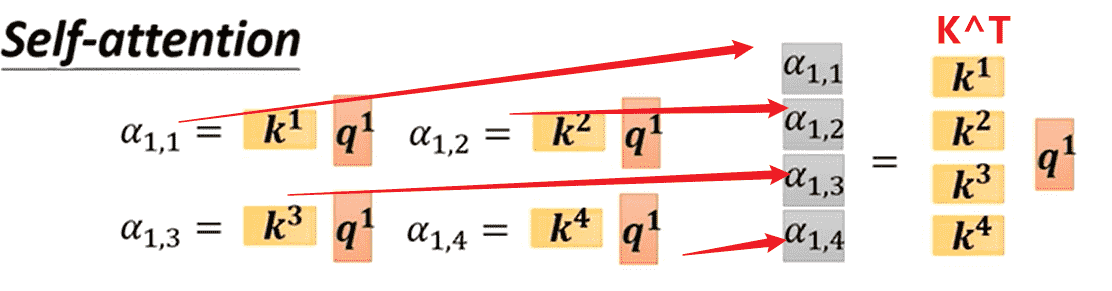
- 对于其他也是同理,计算得到矩阵
- 通过矩阵,每一列过一遍激活函数(softmax)得到

- 计算输出矩阵
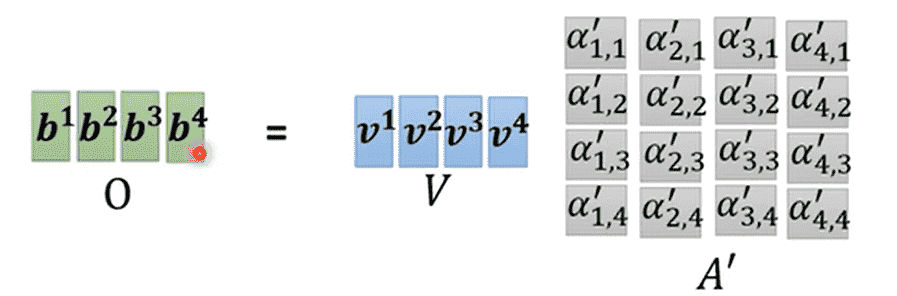
- 整理一下:
- 则是我们需要学习的参数矩阵
Multi-head Self-Attention
一般的Self-Attention只会有一种得到的一组向量,作为相关性的度量
但是有时候需要丰富多个相关性指标
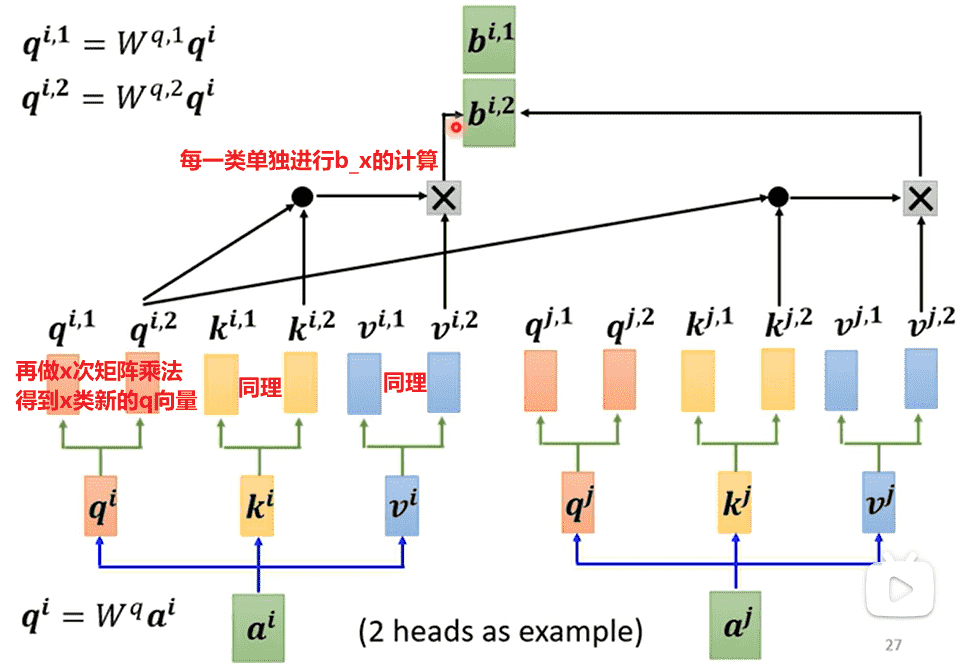
- 得到的多类输出,拼起来乘一个矩阵,得到最后的输出

Position Encoding
-
对于,其对于上文算法来说,并没有距离的概念(交换位置后没什么差别)
-
但对于实际文本来说,是距离较远的向量,是距离较近的向量
-
(需要分析一下位置对实际要的输出是有影响,才会考虑引入Position Encoding)
-
在求解前,每个需要加入一个位置向量即可
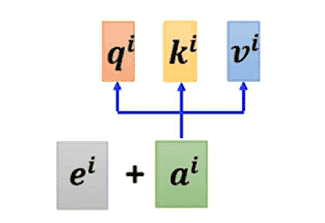
- hand-crafted(人为设置):会使用一些三角函数进行组合
- 方式非常多,暂时没有最好的
1 | // 好像自己写过这个东西 |
- learn from data:直接作为参数进行学习
非文本应用
省流:只要是一个vector set,就可以进行self-attention
- Self-attention for Speech
- 声音讯号转换成向量会更加复杂
- 导致整体的矩阵会变得非常大
- 所以需要引入window,考虑一小段话进行识别
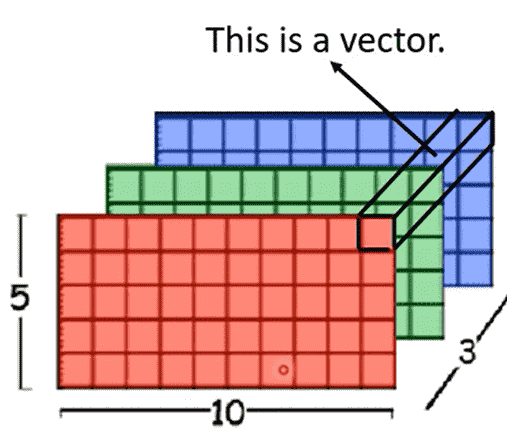
- Self-attention for Image
- 每个像素的所有通道值看作一个向量
- 则我们可以得到分辨率数个向量,构成了一个vector set
- 相比CNN来说,可以考虑整个图像的所有像素,而不是一个感受野
- 自动学习出附近哪些像素是相关的,本质上自动学习了感受野
- 不需要人为设定感受野大小
- 认为:Self-Attention经过调整可以做到CNN一样的事情,因此对于function set层面上,CNN被Self-Attention所包含,是有所限制的特例
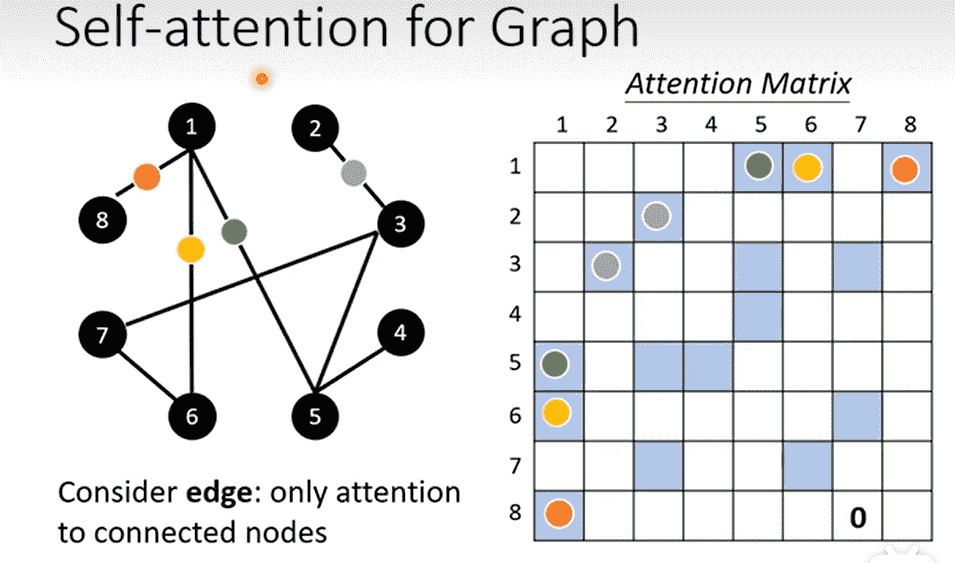
- Self-attention for Graph
- 对于有边的结点对,需要计算attention-score
- 没有边可以直接认为无关,设为0
- 改改就是GNN
RNN
似乎被Self-Attention替代了
- RNN没法并行
- 普通的RNN只会考虑左边序列的输出,而Self-Attention考虑整个序列
- 双向RNN需要大量memory去存储结果,才能做到考虑整个序列