序列模型 · 初步
动手学深度学习v2 - https://zh-v2.d2l.ai/
个人评价是需要有一点基础
本文不会放太多理论的东西
记录一下代码实操即可
理论请移步李宏毅课程的相关笔记
数据 文本预处理
文本:H.G.Well的时光机器
词元 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import redef read_txt (): with open ('data/timemachine.txt' , 'r' ) as f: lines = f.readlines() return [re.sub('[^A-Za-z]+' , ' ' , line).strip().lower() for line in lines] lines = read_txt() print (f'Lines = {len (lines)} ' )print (lines[0 ], lines[10 ],sep='\n' )''' Lines = 3221 the time machine by h g wells twinkled and his usually pale face was flushed and animated the '''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def tokenize (lines, token='word' ): if token == 'word' : return [line.split() for line in lines] else : return [list (line) for line in lines] tokens = tokenize(lines, 'word' ) tokens[0 ] ''' ['the', 'time', 'machine', 'by', 'h', 'g', 'wells'] '''
词表
词表
我们需要把字符串的词元转化成模型可以接受的数值
构建一个字典,从词元映射到数值,这就是词表
构建:
合并所有文档进行去重,得到语料(corpus)
统计词元在语料库中出现的频率,出现次数很少的词元移除(降低复杂性)
被删除、不认识的词:<unk>
begin of seq:<bos>、end of seq:<eos>、填充词元<pad>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import collectionsclass Vocab : """文本词表""" def __init__ (self, tokens=None , min_freq=0 , reserved_tokens=None ): if tokens is None : tokens = [] if reserved_tokens is None : reserved_tokens = [] counter = count_corpus(tokens) self ._token_freqs = sorted (counter.items(), key=lambda x: x[1 ], reverse=True ) self .idx_to_token = ['<unk>' ] + reserved_tokens self .token_to_idx = {token: idx for idx, token in enumerate (self .idx_to_token)} for token, freq in self ._token_freqs: if freq < min_freq: break if token not in self .token_to_idx: self .idx_to_token.append(token) self .token_to_idx[token] = len (self .idx_to_token) - 1 def __len__ (self ): return len (self .idx_to_token) def __getitem__ (self, tokens ): if not isinstance (tokens, (list , tuple )): return self .token_to_idx.get(tokens, self .unk) return [self .__getitem__(token) for token in tokens] def to_tokens (self, indices ): if not isinstance (indices, (list , tuple )): return self .idx_to_token[indices] return [self .idx_to_token[index] for index in indices] @property def unk (self ): return 0 @property def token_freqs (self ): return self ._token_freqs def count_corpus (tokens ): """统计词元的频率""" if len (tokens) == 0 or isinstance (tokens[0 ], list ): tokens = [token for line in tokens for token in line] return collections.Counter(tokens) vocab = Vocab(tokens) print (list (vocab.token_to_idx.items())[:10 ])''' [('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)] ''' for i in [0 , 10 ]: print ('文本:' , tokens[i]) print ('索引:' , vocab[tokens[i]]) ''' 文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells'] 索引: [1, 19, 50, 40, 2183, 2184, 400] 文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the'] 索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1] '''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def load_corpus (max_tokens=-1 ): lines = read_txt() tokens = tokenize(lines, 'word' ) vocab = Vocab(tokens) corpus = [vocab[token] for line in tokens for token in line] if max_tokens > 0 : corpus = corpus[:max_tokens] return corpus, vocab corpus, vocab = load_corpus() len (corpus), len (vocab)
停用词 1 2 3 4 5 6 7 8 9 10 11 12 13 vocab.token_freqs[:10 ] ''' [('the', 2261), ('i', 1267), ('and', 1245), ('of', 1155), ('a', 816), ('to', 695), ('was', 552), ('in', 541), ('that', 443), ('my', 440)] '''
出现频率较多的往往都是一些the、and……,被称为停用词
但本身是有意义的,需要在模型中进行使用
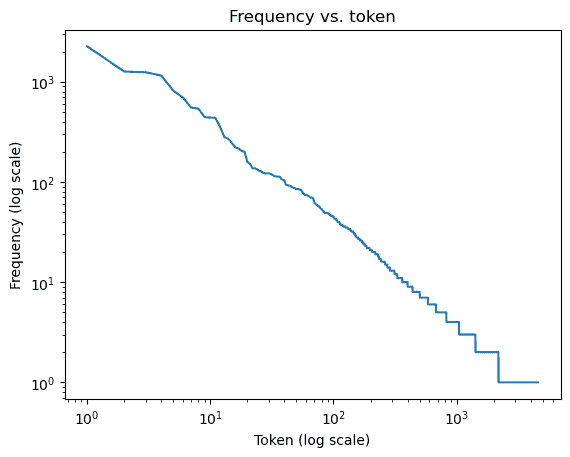
词频 1 2 3 4 5 6 7 8 freq = [freq for token, freq in vocab.token_freqs] indices = np.arange(1 , len (freq) + 1 ) plt.figure() plt.plot(indices, freq) plt.xscale('log' ) plt.title('Frequency vs. token' ) plt.xlabel('Token (log scale)' ) plt.ylabel('Frequency' )
我们绘制了词频与索引在log下的图像
发现中间一部分基本是对数坐标系上的一条直线
齐普夫定律:
log n i = − α log i + c \log n_i = -\alpha \log i + c
log n i = − α log i + c
其中n i n_i n i i i i
长序列处理
当序列太长时,无法被模型一次性处理,需要进行拆分
假设我们设定的子序列长度n = 5 n=5 n = 5
多种方案都是一样好的切分,但是我们不希望子序列的切分只有同一种偏移方式,否则会造成的覆盖的子序列有限
需要引入随机偏移量,兼具随机性、覆盖率
随机采样 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import randomdef seq_data_iter_random (corpus, batch_size, subseq_len ): corpus = corpus[random.randint(0 , subseq_len - 1 ):] num_subseqs = (len (corpus) - 1 ) // subseq_len initial_indices = list (range (0 , num_subseqs * subseq_len, subseq_len)) random.shuffle(initial_indices) num_batches = num_subseqs // batch_size for i in range (0 , batch_size * num_batches, batch_size): initial_indices_per_batch = initial_indices[i: i + batch_size] X = [corpus[j: j + subseq_len] for j in initial_indices_per_batch] Y = [corpus[j + 1 : j + 1 + subseq_len] for j in initial_indices_per_batch] yield torch.tensor(X), torch.tensor(Y) my_seq = list (range (35 )) for X, Y in seq_data_iter_random(my_seq, batch_size=2 , subseq_len=5 ): print ('batch:\n' ) print ('X: ' , X, '\nY:' , Y) ''' batch: X: tensor([[24, 25, 26, 27, 28], [29, 30, 31, 32, 33]]) Y: tensor([[25, 26, 27, 28, 29], [30, 31, 32, 33, 34]]) batch: X: tensor([[19, 20, 21, 22, 23], [14, 15, 16, 17, 18]]) Y: tensor([[20, 21, 22, 23, 24], [15, 16, 17, 18, 19]]) batch: X: tensor([[ 4, 5, 6, 7, 8], [ 9, 10, 11, 12, 13]]) Y: tensor([[ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) '''
顺序分区
有随机偏移,裁掉掉前后部分
剩下部分按顺序进行顺序切分
同一个batch内并不是连续,不同batch同一位置连续
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def seq_data_iter_sequential (corpus, batch_size, subseq_len ): offset = random.randint(0 , subseq_len) num_tokens = ((len (corpus) - offset - 1 ) // batch_size) * batch_size Xs = torch.tensor(corpus[offset: offset + num_tokens]) Ys = torch.tensor(corpus[offset + 1 : offset + 1 + num_tokens]) Xs, Ys = Xs.reshape(batch_size, -1 ), Ys.reshape(batch_size, -1 ) num_batches = Xs.shape[1 ] // subseq_len for i in range (0 , subseq_len * num_batches, subseq_len): X = Xs[:, i: i + subseq_len] Y = Ys[:, i: i + subseq_len] yield X, Y ''' sequential_solution batch: X: tensor([[ 0, 1, 2, 3, 4], [17, 18, 19, 20, 21]]) Y: tensor([[ 1, 2, 3, 4, 5], [18, 19, 20, 21, 22]]) batch: X: tensor([[ 5, 6, 7, 8, 9], [22, 23, 24, 25, 26]]) Y: tensor([[ 6, 7, 8, 9, 10], [23, 24, 25, 26, 27]]) batch: X: tensor([[10, 11, 12, 13, 14], [27, 28, 29, 30, 31]]) Y: tensor([[11, 12, 13, 14, 15], [28, 29, 30, 31, 32]]) '''
序列模型 p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 ) . . . p ( x T ∣ x 1 , x 2 , . . . , x T − 1 ) p(x) = p(x_1)p(x_2|x_1)...p(x_T|x_1,x_2, ...,x_{T-1})
p ( x ) = p ( x 1 ) p ( x 2 ∣ x 1 ) . . . p ( x T ∣ x 1 , x 2 , . . . , x T − 1 )
在之前所有事件发生的前提下,下一件事发生
对条件概率建模:
p ( x t ∣ x 1 , . . . , x t − 1 ) = p ( x t ∣ f ( x 1 , . . . , x t − 1 ) ) p(x_t|x_1,...,x_{t-1}) = p(x_t|f(x_1,...,x_{t-1}))
p ( x t ∣ x 1 , . . . , x t − 1 ) = p ( x t ∣ f ( x 1 , . . . , x t − 1 ) )
这样就得到了自回归模型
使用自身数据预测未来
马尔科夫假设 p ( x t ∣ x 1 , . . . , x t − 1 ) = p ( x t ∣ x t − τ , . . . , x t − 1 ) = p ( x t ∣ f ( x t − τ , . . . , x t − 1 ) ) p(x_t|x_1,...,x_{t-1}) = p(x_t|x_{t-\tau},...,x_{t-1})= p(x_t|f(x_{t-\tau},...,x_{t-1}))
p ( x t ∣ x 1 , . . . , x t − 1 ) = p ( x t ∣ x t − τ , . . . , x t − 1 ) = p ( x t ∣ f ( x t − τ , . . . , x t − 1 ) )
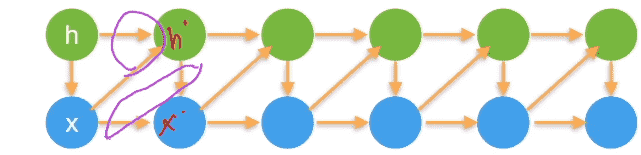
潜变量模型
不希望考虑太多参数,故引入潜变量h t = f ( x 1 , . . . , x t − 1 ) h_t=f(x_1,...,x_{t-1}) h t = f ( x 1 , . . . , x t − 1 )
模型1:根据x , h x,h x , h h ′ h' h ′
模型2:根据h ′ , x h',x h ′ , x x ′ x' x ′
使用潜变量概括了历史信息
误差
事实上不断的自回归会不断积累误差,导致对未来的预测逐渐偏离
后续旨在研究如何让序列模型尽可能预测得更远
困惑度 我们需要一个指标衡量生成的序列的好坏程度
1 2 3 4 5 6 7 'It is raining outside”(外面下雨了)' 'It is raining banana tree”(香蕉树下雨了)' 'It is raining piouw;kcj pwepoiut”(piouw;kcj pwepoiut下雨了)'
假设你在玩一个猜词游戏,每次你都需要从几个选项中猜测下一个词。如果你的猜测总是很准确,那么你对游戏的困惑度就很低。相反,如果你总是猜不中,那么你对游戏的困惑度就很高。
模型的预测本质上是在词表中进行一个分类问题,因此我们可以使用交叉熵去表示
假设一共预测了n n n
1 n ∑ − log P ( x t ∣ x t − 1 , . . . , x 1 ) \frac{1}{n}\sum -\log P(x_t|x_{t-1}, ..., x_1)
n 1 ∑ − log P ( x t ∣ x t − 1 , . . . , x 1 )
由于历史问题,困惑度往往被定义为:
exp ( − 1 n ∑ log P ( x t ∣ x t − 1 , . . . , x 1 ) ) \exp(-\frac{1}{n}\sum \log P(x_t|x_{t-1}, ..., x_1))
exp ( − n 1 ∑ log P ( x t ∣ x t − 1 , . . . , x 1 ) )
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数”。
一般直接当作损失函数用
最好情况,每次都是百分比的预测,则困惑度为1(exp(0) = 1)
最坏情况,每次预测概率为0,则困惑度正无穷
对于baseline,我们每次的预测采取对词元的均匀分布(随机猜测),则困惑度等于词元数量
先log一下再exp一下,可以粗略认为:困惑度代表每次需要从几个词中猜测
因此我们的模型必须超过此困惑度
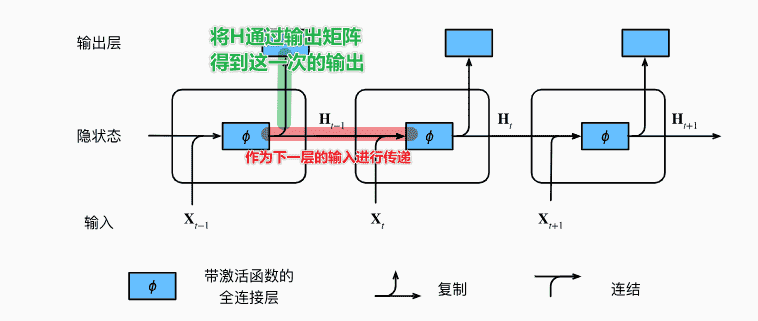
RNN
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) H_t = \phi(X_tW_{xh} + H_{t-1}W_{hh} +b_h)
H t = ϕ ( X t W x h + H t − 1 W h h + b h )
每一层的隐状态:由本次的输入、上一层的隐状态和bias得到
O t = H t W h q + b q O_t = H_tW_{hq} + b_q
O t = H t W h q + b q
代码 数据处理 回到最开始,不管我们使用的是随机采样或是顺序分区
我们得到的张量:(批量大小,时间步数)
但是对于RNN来说,(时间步数,批量大小)才是主流
这个过程直接转置就可以完成
优化计算效率
时间步数在最外层,方便我们按照时间步数进行寻址
方便在同一个时间维度上进行并行
隐藏状态H H H
符合Pytorch等框架的习惯
batch_first:可以通过设置参数,让batch放到最前面,但没必要
1 2 X = F.one_hot(inputs.T.long(), self .vocab_size) X = X.to(torch.float32)
RNN 1 2 3 4 5 6 7 8 9 10 11 12 13 input_size = 100 hidden_size = 20 num_layers = 4 rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers) seq_len = 10 batch_size = 2 x = torch.randn(seq_len,batch_size, input_size) h0 = torch.zeros(num_layers, batch_size, hidden_size) out, h = rnn(x,h0)
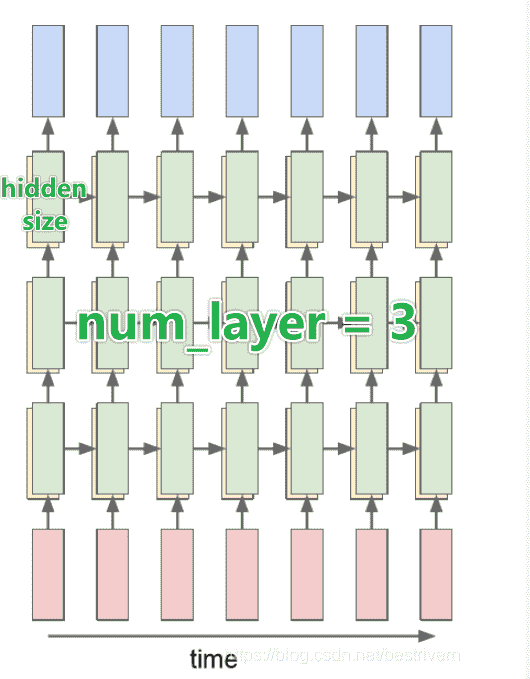
对于nn.RNN(input_size,hidden_size,num_layers):
input_size:表示输入序列的每一个元素的维度(例如vocab有26个词元,进行one-hot后得到了维度26的张量,26即为input_size)hidden_size:RNN内置隐藏层的维度num_layers:RNN内置隐藏层的层数
我们对得到输出output和隐状态h
输出:(num_steps, batch_size, hidden_size)
每一个时间步数都会输出一组结果,故总共num_steps个(batch_size, hidden_size)张量
最后一层的隐藏层神经元都会有输出
隐状态:(num_layers, batch_size, hidden_size)
我们会保留每一层的输出
以及每个批次、每个神经元的输出
接下来我们可以实操,定义一个RNN模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class RNNModel (nn.Module): def __init__ (self, vocab, **kwargs ): super (RNNModel, self ).__init__(**kwargs) self .vocab_size = len (vocab) self .num_hiddens = 256 self .rnn = nn.RNN( input_size = self .vocab_size, hidden_size = self .num_hiddens, num_layers = 1 ) self .linear = nn.Linear(self .num_hiddens, self .vocab_size) def forward (self, inputs, state ): X = F.one_hot(inputs.T.long(), self .vocab_size) X = X.to(torch.float32) Y, state = self .rnn(X, state) output = self .linear(Y.reshape(-1 , Y.shape[-1 ])) return output, state def begin_state (self, batch_size, device ): return torch.zeros( (self .rnn.num_layers, batch_size, self .num_hiddens), device=device ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) net = RNNModel(vocab).to(device)
预测 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 '''续写prefix之后的内容''' def predict (prefix,num_preds = 30 ): state = net.begin_state(batch_size=1 , device=device) outputs = [vocab[prefix[0 ]]] for y in prefix[1 :]: _, state = net( torch.tensor([outputs[-1 ]]).reshape(1 ,1 ).to(device), state) outputs.append(vocab[y]) for _ in range (num_preds): y, state = net(torch.tensor([outputs[-1 ]]).reshape(1 ,1 ).to(device), state) outputs.append(int (y.argmax(axis=1 ).reshape(1 ))) return '' .join([vocab.idx_to_token[i] for i in outputs]) predict('time travel' )
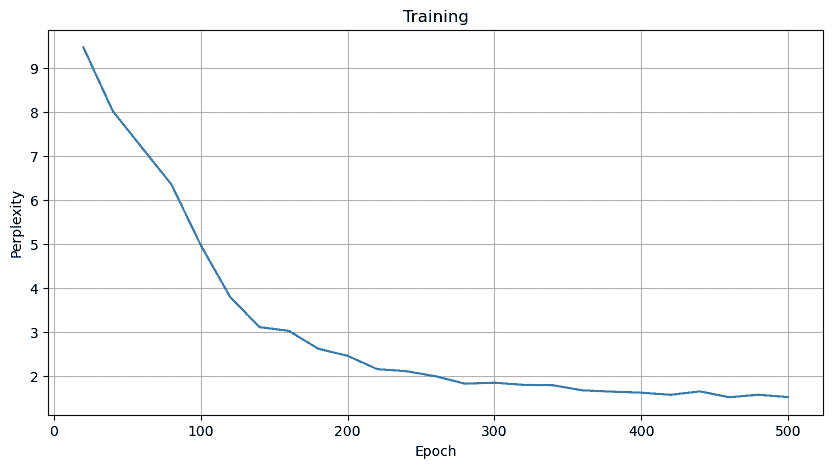
训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 def train_epoch (net, train_iter, loss, updater, device ): start = time.time() training_loss, tokens = 0.0 , 0 for X, Y in train_iter: state = net.begin_state(batch_size=X.shape[0 ], device=device) y = Y.T.reshape(-1 ) X, y = X.to(device), y.to(device) y_hat, state = net(X, state) l = loss(y_hat, y.long()).mean() updater.zero_grad() l.backward() grad_clipping(net, 1 ) updater.step() training_loss += l * y.numel() tokens += y.numel() return math.exp(training_loss / tokens), tokens / (time.time() - start) def train (net, train_iter, vocab, lr, num_epochs, device ): pltx = [] plty = [] loss = nn.CrossEntropyLoss() updater = torch.optim.SGD(net.parameters(), lr) for epoch in range (num_epochs): ppl, speed = train_epoch( net, train_iter, loss, updater, device) if (epoch + 1 ) % 20 == 0 : print (predict('time traveller' )) print (f'epoch = {epoch+1 } /{num_epochs} perplexity {ppl:.1 f} ' ) pltx.append(epoch + 1 ) plty.append(ppl) print ('ending' ) print (f'perplexity {ppl:.1 f} , {speed:.1 f} tokens/sec on {str (device)} ' ) print (predict('time traveller' )) print (predict('traveller' )) showplt(pltx, plty, 'Training' , 'Epoch' , 'Perplexity' ) train(net, train_iter, vocab, lr, num_epochs, device)
梯度裁剪 长度为T T T O ( T ) O(T) O ( T )
非常容易导致梯度爆炸、梯度消失
ReLU可以避免梯度消失问题(当激活函数的梯度过小,无法有效更新参数),从而保持梯度的有效传递
梯度裁剪用于避免梯度爆炸
设定一个超参数θ \theta θ
g ← min ( 1 , θ ∥ g ∥ ) g g \gets \min(1, \frac{\theta}{\left \| g\right \|})g
g ← min ( 1 , ∥ g ∥ θ ) g
此处梯度的范数永远不会超过θ \theta θ
1 2 3 4 5 6 7 8 def grad_clipping (net, theta ): params = [p for p in net.parameters() if p.requires_grad] norm = torch.sqrt(sum (torch.sum ((p.grad ** 2 )) for p in params)) if norm > theta: for param in params: param.grad[:] *= theta / norm
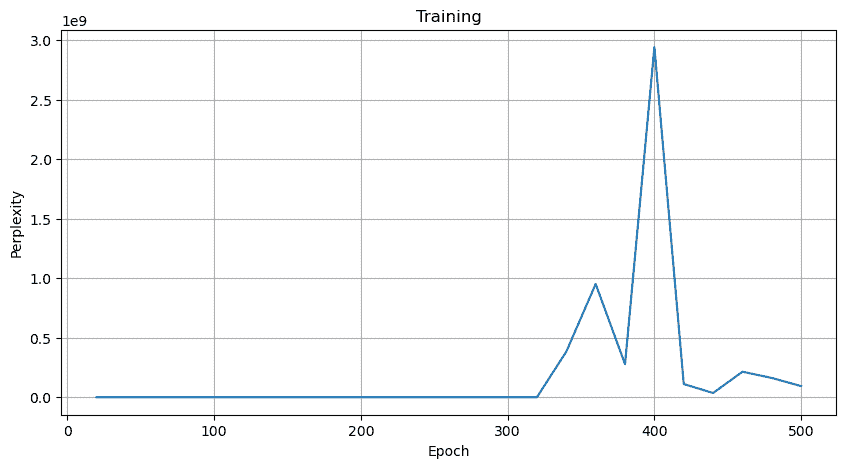
如果不进行梯度裁剪
直接爆了
题外话:如果我们对输出结果进行relu一下,不做梯度裁剪也能成(
结果
1 2 3 4 print (predict('time traveller' , 200 ))''' time travellerit s against reason said tiens aine tile atout in time and any of the three dimensions they could re heatid and trive ri it filbes at fine tions in our on this be s aine thes of space and a focresy wi '''
还行(至少能输出正常的单词