
现代序列模型与机器翻译实践
动手学深度学习v2 - https://zh-v2.d2l.ai/
个人评价是需要有一点基础
- Pytorch 小土堆 先把Pytorch基础看一下
- 李宏毅2022春机器学习
- 理论部分更推荐李宏毅或者吴恩达,会更好理解
- 我的策略是理论在李宏毅这里补,作业不做,在李沐这里实操一下代码
本文不会放太多理论的东西
记录一下代码实操即可
理论请移步李宏毅课程的相关笔记
门控循环单元GRU
并不是每个细节都值得关注
随着喂入序列的变长,序列开头的影响占比会变小
但很有可能序列开头存在重要的关键词
因此我们希望我们的网络能够对序列的不同部分,有所侧重、关注、选择
- 存储:早期重要信息
- 跳过:无用信息(网页文章的html代码)
- 重置:书的章节之间的逻辑中断
门
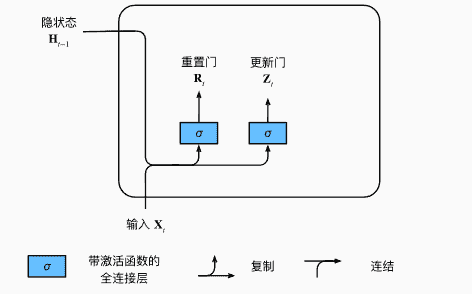
- 利用sigmoid函数,全连接层通过输入、隐状态,预测出门的值(0-1之间)
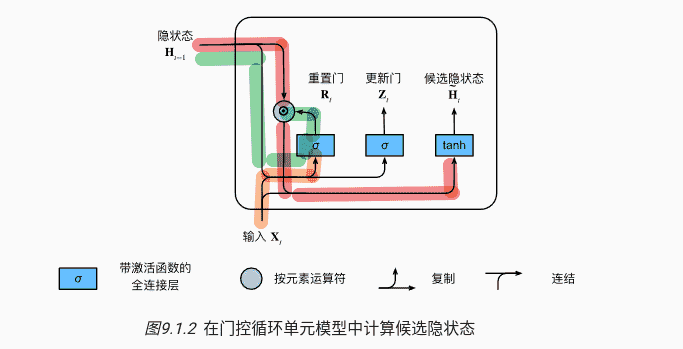
候选隐状态 <- 重置门
正常情况下,隐状态的计算:
我们希望引入,对状态进行重置:
- 设定激活函数为,确保候选隐状态值在(-1,1)内
- 使用Hadamard积(矩阵元素对应相乘):
- ,此时只由当前输入决定。相当于重置了隐状态为一开始的默认值,从头开始
- ,正常的循环神经网络,隐状态照常保存
综上,定义候选隐状态为:
隐状态 <- 更新门
上文中,我们计算得到的是候选隐状态
但是如果当前的文本并不让我们感到有意义,我们需要跳过这部分
也就是基本不会修改,直接沿用之前的隐状态
反之,我们希望将当前值更新为最新的隐状态
引入更新门:
- ,相当于完全使用当前新的隐状态
- ,直接沿用之前的隐状态
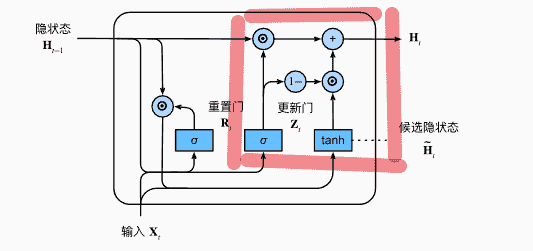
总结:
- 重置门:有助于捕获序列的短期依赖关系
- 更新门:有助于捕获序列的长期依赖关系
代码
RNN换成GRU即可
1 | class RNNModel(nn.Module): |
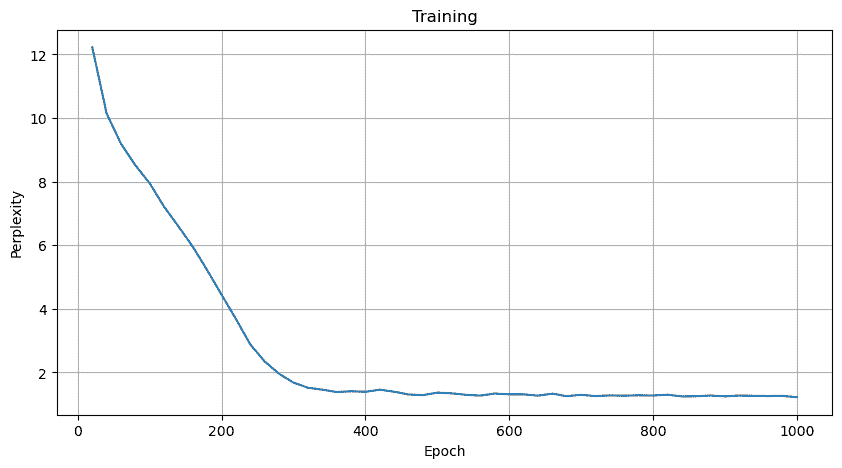
- 相比RNN,困惑度整体会变更低
长短期记忆网络LSTM
设计上比GRU更加复杂,但是早了20年
门
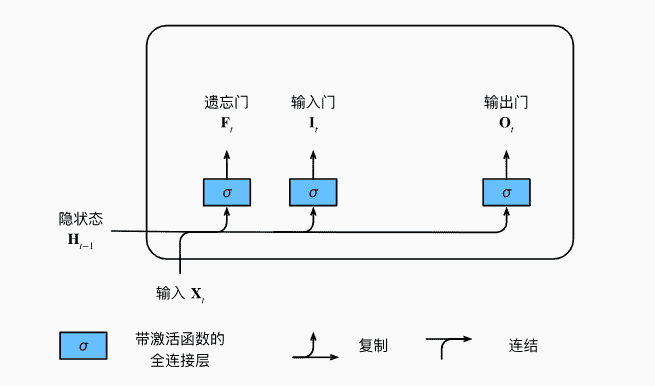
- 输入门:
- 遗忘门:
- 输出门:
通过sigmoid激活函数,三个门的值都在(0,1)内
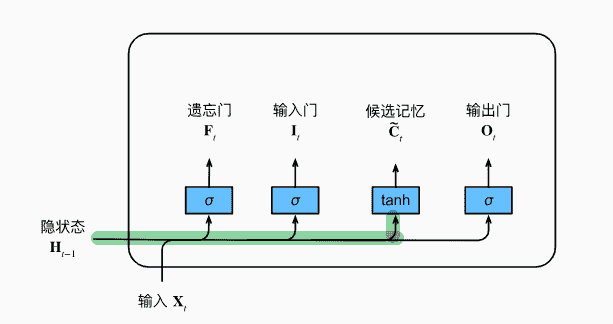
候选记忆元
使用做激活函数,取值[-1,1]
记忆元
记忆元主要来自两个部分:
- 过去的记忆:即,由遗忘门控制保留多少过去的记忆
- 新的记忆:即当前输入带来的候选记忆元,由输入门控制引入多少
则:
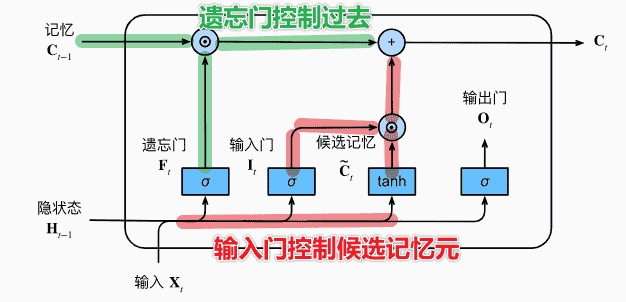
这种机制有助于模型记录下非常久远以前的记忆
某种程度上缓解了梯度消失,捕获长距离依赖关系
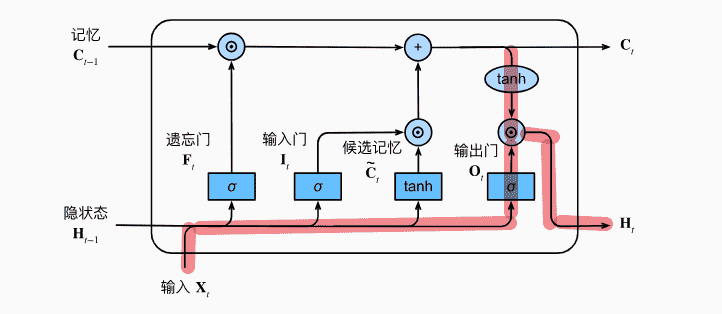
隐状态
- 确保隐状态仍然在
- 输出门接近1:完整保留记忆作为隐状态
- 输出门接近0:隐状态被重置,只保留了记忆信息
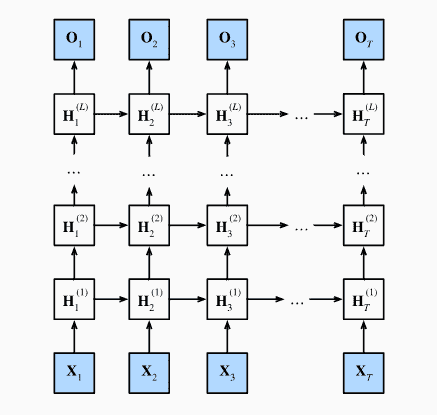
深度RNN
前一篇讲过了(
其实就是隐状态由单个全连接层,变成多个隐藏层
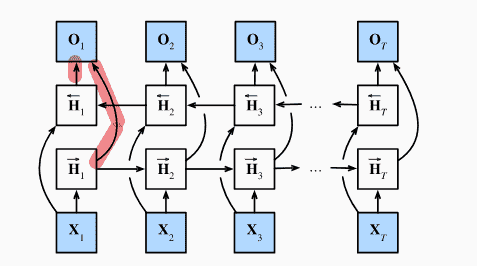
双向RNN
普通的RNN只能考虑到上文,无法考虑到下文:
1 | ''' |
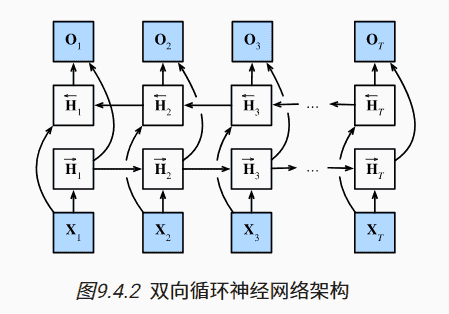
将隐状态分为正向隐状态、反向隐状态
对于正向隐状态:
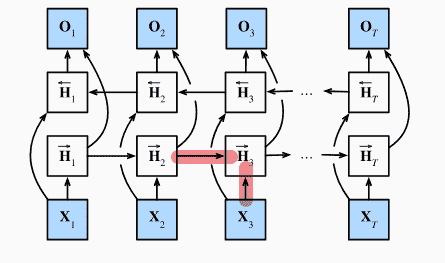
- 由输入、上一个前向隐状态得到
对于反向隐状态:
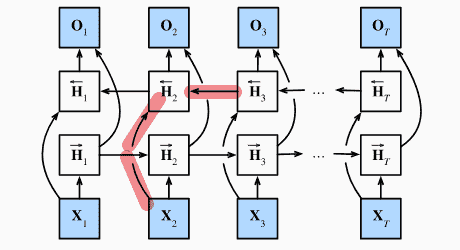
- 由输入、后一个反向隐状态得到
对于输出,我们把合并成(矩阵连起来)
代价
-
计算速度非常慢,计算链条很长
-
需要存储的内存非常大
-
用处有限
- 填充缺失单词、词元、注释
- 机器翻译
机器翻译
数据读入与处理
1 | ''' |
- 每行两个字符串,前者是英文,后者是法语,使用
\t隔开 - 文本中含有一些不间断空格、不可见空格(
\u202f、\xa0),我们需要替换成普通空格 - 将大写字母转化成小写字母,简化数据
1 | "go away. fous le camp !" |
我们希望最后切分成多个词元列表,因此需要处理字符串:
- 单词、标点符号之间需要有空格
1 | def filter(s): |
我们可以绘制图表:
1 | import matplotlib.pyplot as plt |
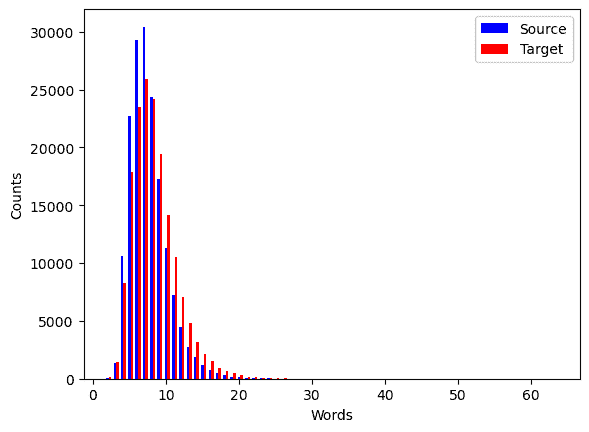
- 大部分句子的词元数量都不超过20,主要集中在10
接下来我们需要构建词表
沿用的是之前RNN的代码:
1 | import collections |
在序列模型中,我们会使用定长序列进行训练
但一般数据是不定长的:
- 超长度,截断
- 长度不足,填充
<pad>
1 | def truncate_pad(src, padding_token, num_steps): |
接下来我们构建小批量训练数据
- 每个序列最后需要添加一个
<eos>,表示句子的结束
1 | def build_array(tokens, vocab, num_steps): |
最后封装一下:
1 | class fraDataset(Dataset): |
编码器 + 解码器
-
编码器可以使用双向RNN
-
解码器需要进行预测,无法看到未来,只能单向
-
encoder没有输出,encoder最后一个时间步的隐状态,将作为decoder的初始隐状态
Encoder
1 | class Seq2SeqEncoder(nn.Module): |
验证:
1 | encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) |
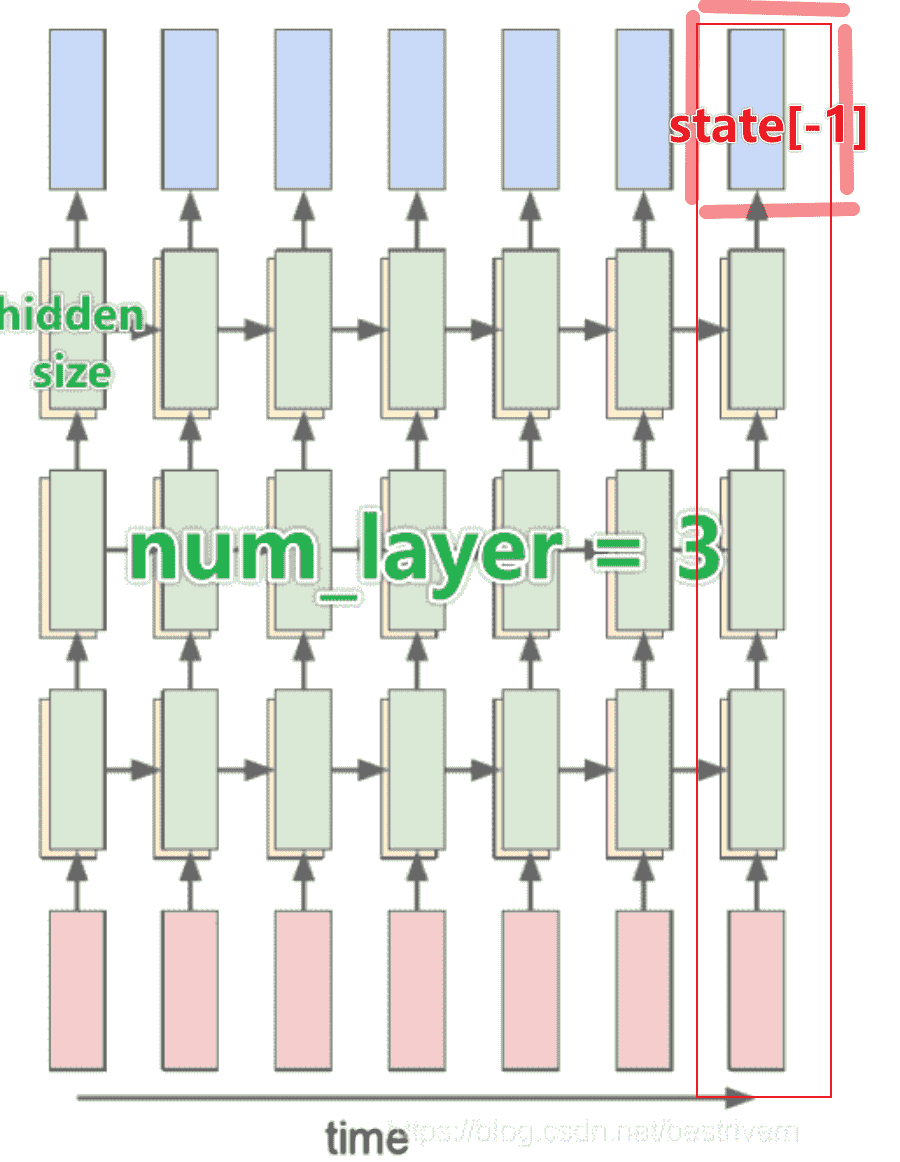
decoder
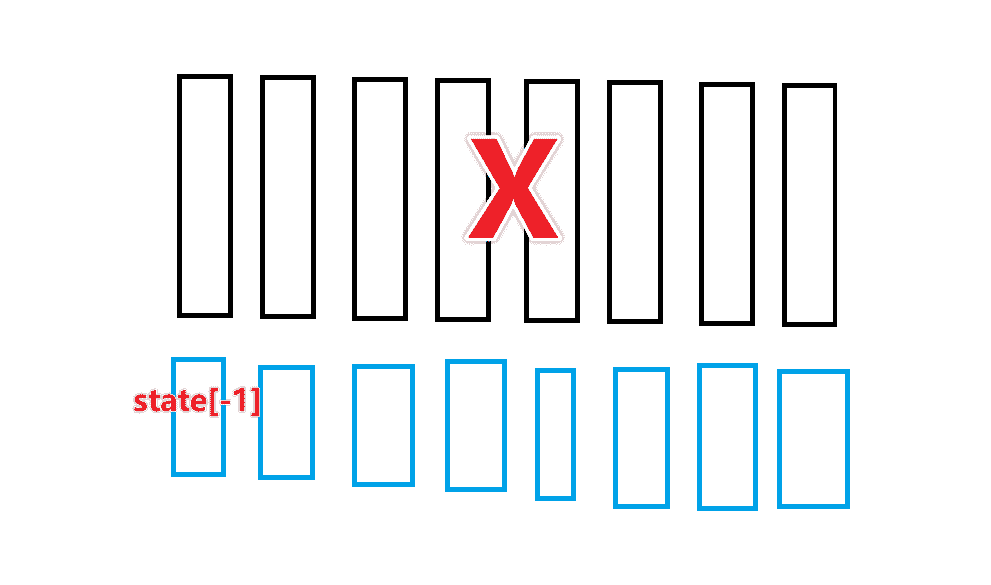
- 我们需要取出最后一层的state
- 和X进行拼接
1 | class Seq2SeqDecoder(nn.Module): |
测试:
1 | decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) |
封装
1 | class EncoderDecoder(nn.Module): |
Vaild Length
在前文中我们处理得到了一个vaild_len
1 | ''' |
我们希望可以将不相干的、超出有效长度的进行屏蔽
1 | [ 66, 12, 77, 2545, 4, 3, 1, 1], |
1 | def sequence_mask(X, valid_len, value=0): |
损失函数
超出有效长度的部分,不能计算交叉熵,需要置为0
1 | class MaskedSoftmaxCELoss(nn.CrossEntropyLoss): |
训练
- 训练时需要给decoder喂入真正的数据,即都是同一套X作为输入
- 但是需要处理一下
bos和eos
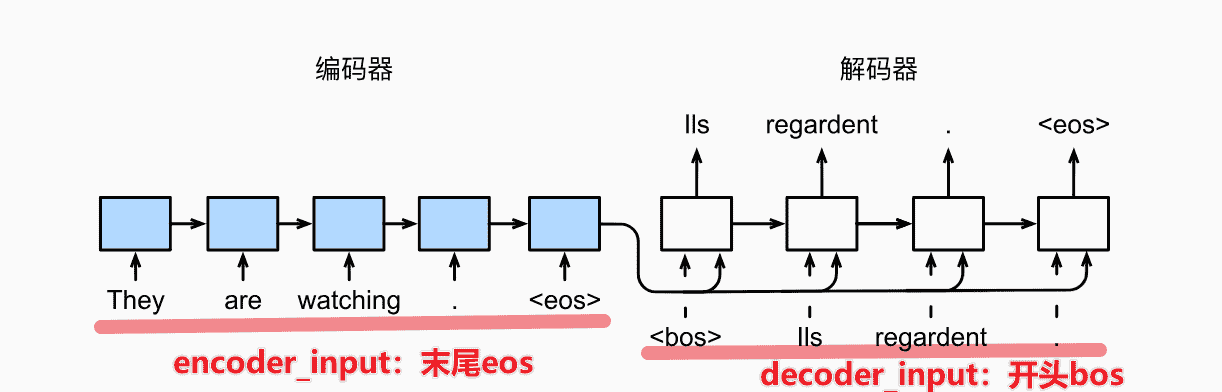
1 | def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device): |
- 准备工作
1 | embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1 |
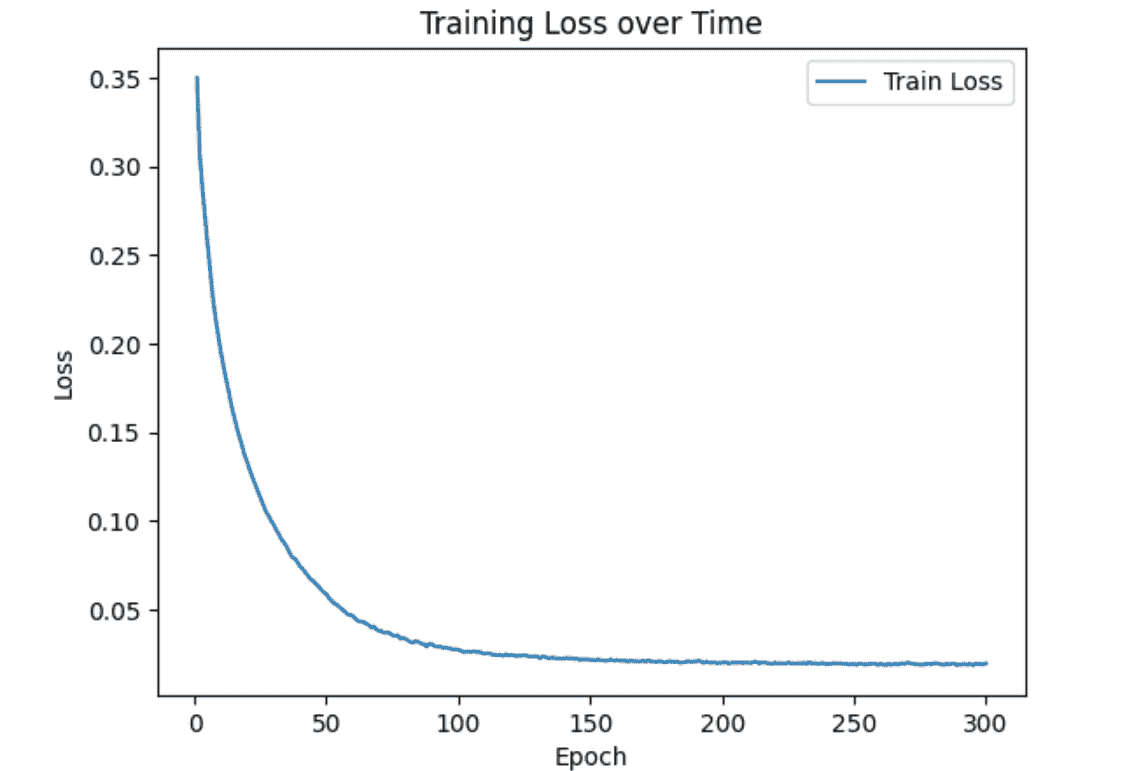
- 结果
预测
我们需要一个个喂入decoder,以decoder的输出作为下一次输入
1 | def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps, device): |
测试:
1 | engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .'] |
不太行