[TOC]
Intro
- AED(Automatic Error Detection)
- 本文定义为:给定问题-解答的输入对,识别错误步骤以及错误类型
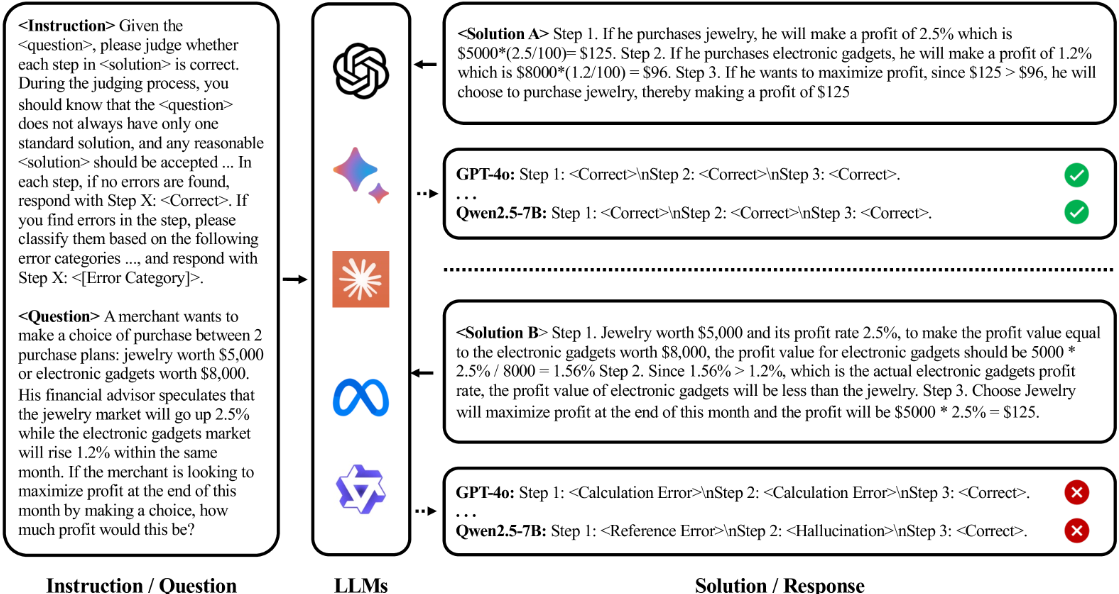
如图,paper点出传统的方法使用可以对问题的常规解法进行正确错误检测
但是单个问题的解法可以存在多个,认为之前的做法泛用性较差
常规解法与非常规解法会产生7%的性能差距,先进的闭源模型也无法避免
- LLM错误检测器表现
conformity bias(从众偏差)- 倾向“遵循主流答案(训练中经常出现的)”而忽略可能也正确但不常见的其他解法
- 导致模型对标准答案的识别准确,却对非常规解法的识别薄弱
论文针对缓解模型的conformity bias进行工作
提出AskBD框架,为每个Solution自适应生成参考答案(合适的参考答案能显著提升性能)
- 直接调用模型,无微调,拓展性强
- 自适应方式高度契合给定Solution,降低Bias
- 框架可协同CoT技术增强性能
Preliminary Study
Paper构建了一个Alternative Solution数据集用于充分暴露模型的从众偏差效应,帮助进行后续的探索
Automatic Solution Permutation
paper希望构建一个高质量的Alternative Solution数据集
给定问题和Solution,希望替换掉整个解决方案为Alternative Solution
- 低质量:对常规Solution只是简单的语义替换,并没有深层的逻辑变换

ASP(自动解法置换),如图,对应了Solution和数学表达式的关系,使用LLM prompt独立执行:
- Extract:常规Solution -> 数学表达式,完成后需要执行运算,检查是否能够得到正确计算结果,否则剔除
- Permute:因式分解、分配律,重新排列表达式(同样需要运算检验)
- Explain:置换后的表达式输入到LLM,引导生成高质量Alternative Solution
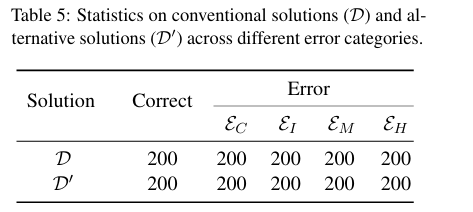
paper采样GPT-4o,从GSM8K数据集抽取200组问答对,构建常规数据集D
对D中的每个样本,3次ASP生成3个Alternative Solution,由教育系研究生评审质量,选择三个之中最优的一个
完成替换数据集D’的制作
Erroneous Solution Generation
需要将错误注入到D和D‘之中,生成测试样本
paper引入了四种错误:
- $\varepsilon_C$:calculation errors
- Operands in expressions are correct but an error occurs in the calculated results.(表达式正确,计算结果出错)
Each gust blows the leaf forward 5 feet, so 11 gusts will blow it forward 5 ×11 = 50 feet.
- $\varepsilon_R$:reference errors
- Expression are incorrectly referencing the question conditions or the results from prior steps.(错误引用了题目条件或之前的计算结果)
Each gust blows the leaf forward 5 feet, so 10 gusts will blow it forward 5 ×10 = 50 feet.(题目原条件是11,不是10)
- $\varepsilon_M$ :missing steps
- Operands or expressions in the step that lack of references or support from the question conditions or prior steps.
Each swirl after a gust blows it back 2 feet, so 11 swirls will blow it back 2 ×11 = 22feet. Step 2. After 11 gusts, the leaf has traveled 55 − 22 = 33 feet down the sidewalk.(缺少了得到55这个数字的计算过程)
- $\varepsilon_H$:hallucinations(幻觉)
- Statements or operands in the listed expression are fabricated or inconsistent with the question’s conditions.(虚构或与条件不一致)
- ……
It is worth noting that this study specifically aims to explore conformity bias, and therefore, we do not include all possible error types.
针对D和D’的每个样本,随机错误步骤的位置编号,每个样本生成了四种不同错误类型的样本,总共2000条
Analysis and Findings
Conformity Bias Identification
评估指标:The evaluation metric is the identification accuracy across both correct and erroneous solutions.
- 需要识别错误位置、错误类型
Paper使用提示词进行纠错,明确LLM本题存在替代解法,强调所有合理解决方案应该被接受,并且明确定义错误类别
|
|
参与测试的LLM:
平均错误检测准确率的测试结果:
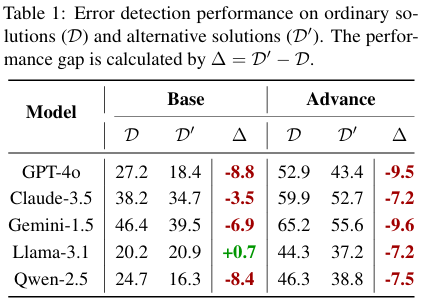
证实了LLM在AED任务中存在明显的从众偏差
Solution Likelihood Score Analysis
对于当前问题$q$,我们可以计算LLM生成答案$s$的概率$P(s|q)$
我们可以把$s$拆分成多个token:$s_i$
$$ P(s|q) = P(s_1, s_2, ...,s_{|s|} | q) $$$$ P(s|q) = P(s_1|q) \times P(s_2|q,s_1) \times P(s_3|q,s_1,s_2) \times ... $$$$ \log P(s|q) = \sum_{i=1}^{|s|} \log P(s_i|q,s_1:s_{i-1}) $$这个值就是对数似然分数 (Log-Likelihood Score)
它衡量了模型在给定问题 q 的情况下,对答案 s 的“信任度”或理解程度
$$ \log L_{\theta}(s|q) = \frac{\log L_\theta(s|q)}{|s|} $$其中$\theta$表示LLM的参数(闭源模型的似然分数无法获取,采取了开源模型的似然分数均值做伪指标)
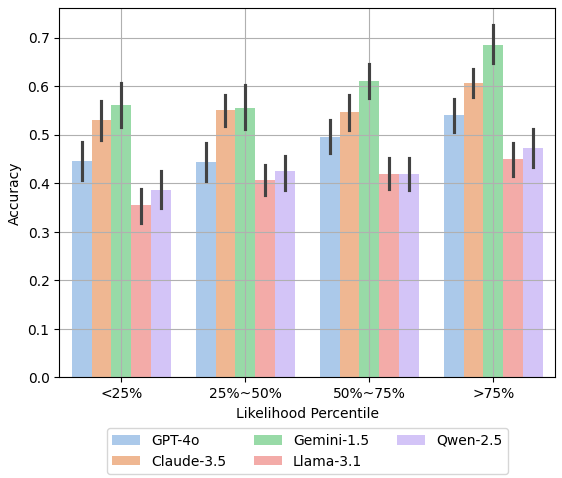
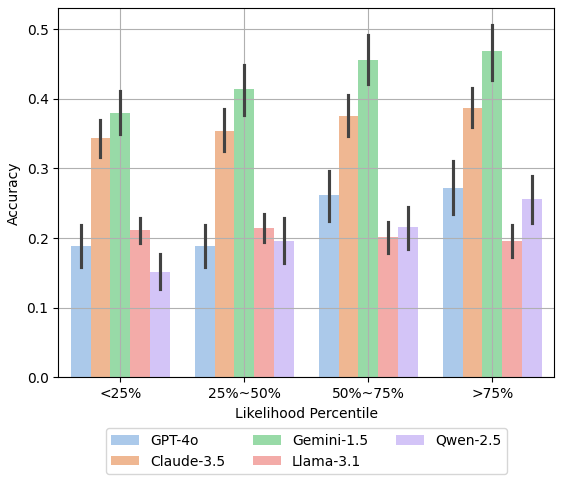
同时喂入 了常规解法+替代解法,根据似然分数分成四个档进行对比
显然似然值越高,Acc越高
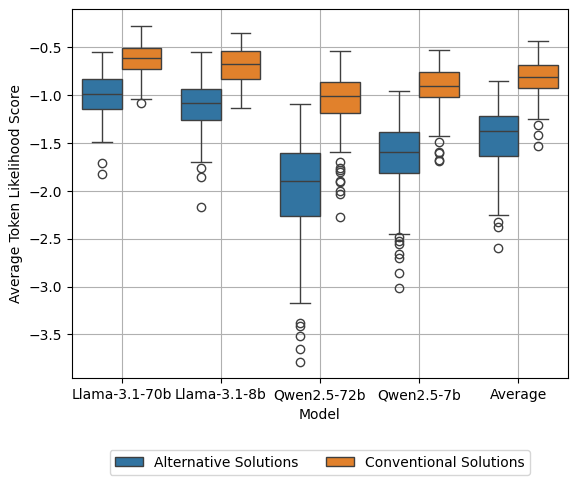
对于开源模型,替代解法的似然分数显然低于常规解法
Reference-based Detection Findings
- 不太可能直接提高替代Solution的似然值
- 通过改变数据集进行微调,但是无法解决根本问题,仍有可能碰见其他的未遇见情况
参考:2407.09136 Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors,提出引入参考答案提升了常规解法的检测性能
将学生解题步骤与标准答案对齐
本paper尝试推广到替代解法,但是:
- 实际情况下,参考答案并不是总能获取
- 即便能够获取,一般也是常规解法的参考答案
paper采用了两条技术路线进行对比:
- 使用常规解法作为参考答案
- 自适应使用对应解法作为参考答案(?细节不太清楚,后文兴许会说)
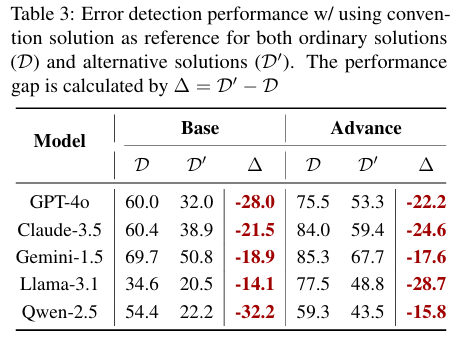
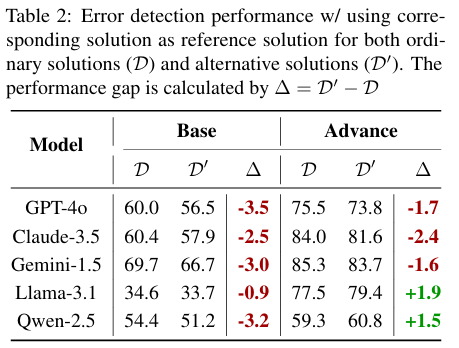
根据与前文提示词的测试结果进行对比,引入参考答案对两个数据集的acc都有显著的提升
但是使用常规解法做参考答案加剧了bias,而自适应选择明显缓解了bias
因此选择合适的参考答案是能起到关键作用的
Method
提出AskBD(Ask-Before-Detection)框架,在评分过程中为每个待评答案动态生成适配的参考解法
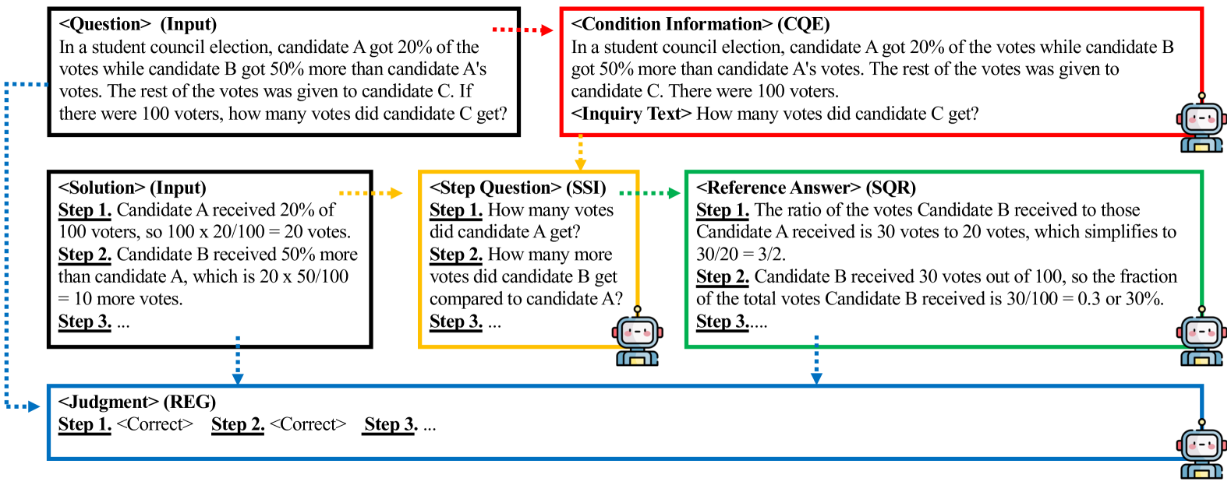
输入:问题文本$q$,解答文本$s$,LLM$f$,提示词$p$
- Condition and question extractor(CQE)
- 从问题文本中抽取条件$q_c$和提问文本$q_i$
- $(q_c, q_i) = f([p_{cqe}, q])$
- Solution Step Inquirer(SSI)
- 为提高生成结果的稳定性,SSI 会先总结每个步骤的结论再构建对应问题。
- 将解答文本转化为分步骤问题列表文本$Q$,末尾附加提问文本$q_i$,以确保生成的参考解答能够回应原始问题的核心任务。
- $Q = [f([p_{ssi},s]), q_i]$
- Step Question Responder (SQR)
- 通过条件文本总结$Q$中每个问题的答案,生成参考答案$r$
- $r = f([p_{sqr},q_c, Q])$
- Reference-Enhanced Grader (REG)
- 根据$q, s, r$生成错误位置$y_s$和错误类型$y_e$
- $y=f([p_{reg},q,s,r])$
输出:$y_s, y_e$
Experiment
实验目的是验证核心的三个问题:
- 是否缓解从众偏差
- 是否有额外的性能优势
- 与CoT等推理技术的兼容性
实验方法:
- 采用前文数据集,相同的10个LLM,用于对比前两个问题
- 整合了CoT技术,评估兼容性
- 所有实验分别实验三种不同的随机seed,报告平均错误检测准确率
- 前文测试和CoT方案作为两个baseline
CoT的提示词
|
|
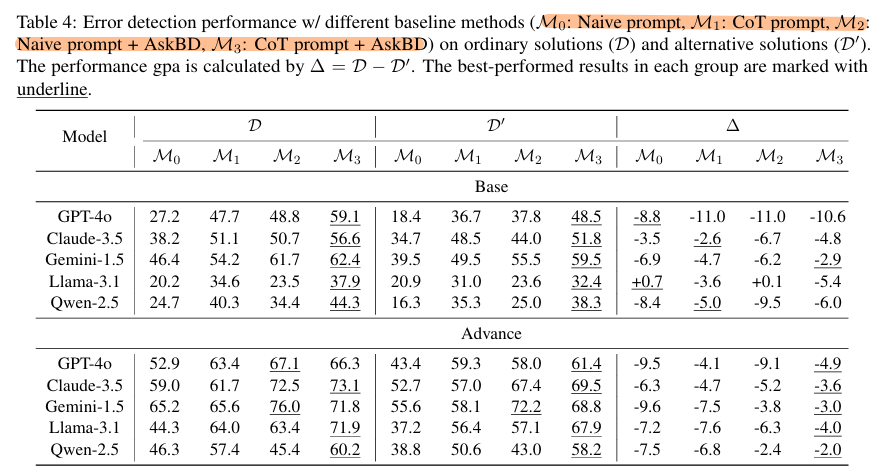
对于问题1
- 重点分析M0和M2在$\Delta$列的差距
- Base版本的优化并不明显,认为是模型推理能力不足,限制了框架效用
- 对比M1与M2,CoT也有缓解Bias的能力,在多数Advance模型中,框架的优化能力强于CoT
对于问题2
- 在D、D’列对比M2和M0
- 框架确实提升了acc性能
- 对比M1 M2,CoT也体现出了性能提升
- 在base模型中CoT技术更胜一筹
- 在Advance模型中框架更强(……)
针对问题3
- M3和M1对比,确实变强了
- 兼容性好
Limitation
- 只考虑了四个错误类型,忽略了学生解答中那些更罕见却更具挑战性的错误类型
- 仅聚焦于数学应用题