[TOC]
Essential-Web v1.0 24T tokens of organized web data
Preview
构建了多维度的分类体系,适合通过SQL等方式进行数据筛选出新的数据集
- 使用开源模型进行数据标签的标注,得到了EAI-Distill-0.5b
- 推理清洗了23.6B的数据,花费了90000 AMD MI300x GPU-hours
The inference job ran on 512 AMD MI300x for about 1 week.
分类体系:
- 一个有限的类别集合 $T=\left { C_1, C_2, …, C_k \right } $。
- 每个类别$C_i$都有一个非空、有限的标签集$L_i$。
标注形式为$T(d) = \left { (\lambda_1, \mu_1), …\right}$
- 其中,$λ_i\in L_i$ 是类别$C_i$的主要标签
- $\mu_i \in (L_i \setminus {\lambda_i}) \cup {\bot}$ 是一个可选的次要标签,必须与$\lambda_i$不同
- 当文档适合两个标签时非常有用
- $\bot$表示弃权(abstention)。
- 所有类别和标签集都是预先固定的,这允许训练一个单一的静态分类器
实验设置
Chinchilla最优计算比例
Chinchilla缩放定律发现了一个最优比例:大约每个参数需要20个训练token Epoch AIAnalytics Vidhya。这个比例是DeepMind通过训练400多个语言模型得出的计算最优配置。
具体来说:
- Chinchilla模型有70B参数,在1.4万亿tokens上训练,达到20 tokens per parameter的比例 Chinchilla Scaling: A Replication Attempt | Epoch AI
- 这个20:1的比例被认为是在给定计算预算下实现最佳性能的理想配置
所有数据集在训练前均使用了 13-gram Bloom Filter
选用了两个2.3B模型对数据进行评估
-
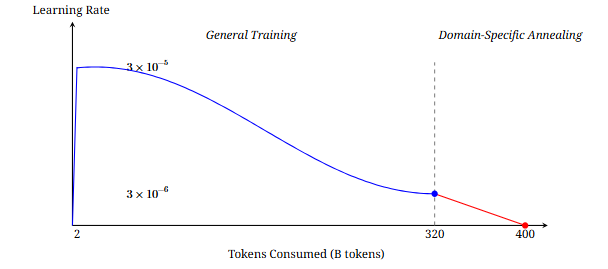
预训练(3200亿Token):该阶段帮助模型学到广泛的语言知识
-
General-base:仅使用网络数据(DCLM-baseline)做预训练
-
Code-base:使用网络数据(DCLM-baseline)+代码数据(Stack v2 Dedup中的Python),各占50%做预训练
-
-
退火(800亿token):为了评估特定领域数据集的性能,采用需要评估的新数据集
- 学习率接近零的目的是在新的领域数据上进行“微调”,而不是进行大规模的“重新训练”
每个模型总计处理 4000 亿 token 数据量,是Chinchilla的10倍数据
蒸馏
蒸馏方案
数据来源与规模
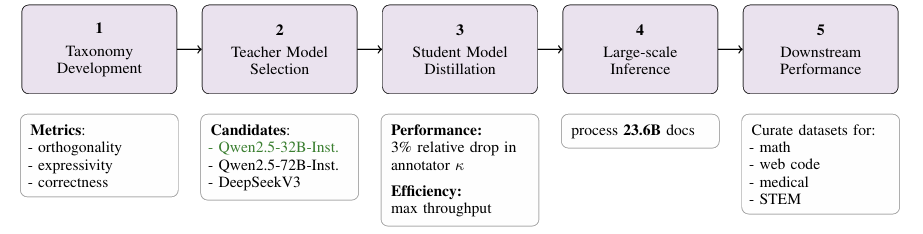
- 标注数据:使用Qwen2.5-32B-Instruct对104.6M文档共82Btoken进行两轮标注,生成合成标签用于蒸馏训练。
- 第一轮:标注8个分类类别(如FDC、Document Type V1/V2等)。
- 第二轮:扩展至12个类别(新增Bloom、Technical Correctness等)。
数据预处理
- 子采样:对超过30,000字符的文档,截取开头、随机中间段和结尾(Algorithm 12),避免长文本影响推理速度。
- 质量过滤:通过统计和模型信号(如DCLM分类器)过滤低质量文档(Algorithm 1)。
模型架构
- 基础模型:Qwen2.5-0.5b-Instruct(5亿参数),基于Gemma 3架构,使用QK-norm稳定注意力。
- 序列长度:16,384 tokens,支持长上下文。
训练参数
- 优化器:AdamW(β1=0.9, β2=0.95),权重衰减0.1。
- 学习率:峰值1e-4,线性预热2B tokens,余弦衰减至1e-5,最后线性退火至0。
- 批量大小:全局2M tokens,梯度累积实现大批次训练。
- 训练量:82B tokens(合成标签数据)。
- 损失计算:仅对教师模型生成的标签token计算损失,输入文档和系统提示被掩码。
教师模型选择
- 教师:Qwen2.5-32B-Instruct,因其标注一致性(κ=0.74)与推理速度平衡(1.4 RPS/GPU)。
蒸馏步骤
- 标签生成:
- 教师模型生成多分类标签(如FDC层级、Document Type等),格式为
主标签,次标签(Algorithm 13)。 - 压缩输出:从平均791 tokens缩短至51 tokens,提升推理速度50倍(Table 12)。
- 教师模型生成多分类标签(如FDC层级、Document Type等),格式为
- 上下文蒸馏:
- 移除教师模型的提示模板(Prompt 1/2),直接训练学生模型生成压缩格式标签。
评估方案
Metrics
- 正确性:多人分类的结果应该类似,验证模型打标签是否标准一致
- 使用GPT-4o和Claude Sonnet-3.5作为专家模型
- 使用kappa系数作为指标
- 取对4o的系数和对claude的系数的均值作为结果
检测方式是验证模型与专家模型的标准是否一致,对于指标paper中进行了变种
对于某个模型的分类结果$S\in \left { \phi, (\text{label}), (\text{label1, label2}) \right }$
最少是一个标签(主标签),有时可以加一个次标签
- 标注结果一致的判定:两模型的$S$有交集
然后套公式
Qwen2.5-32B-Instruct ≈ 0.74
EAI-Distill-0.5b ≈ 0.71~0.73
- 正交性:不同分类体系之间的标签应该是独立的
- 例如在某分类A下打了a,分类B始终是b,发生了绑定
- 需计算互信息、香农熵
$$ >\text{NMI}(X, Y) = \frac{2 I(X; Y)}{H(X) + H(Y)} >$$其中:
- $p(x)$按$x$出现的频率,$p(x,y)$按$x,y$同时出现的频率计算
$$ > I(X; Y) = \sum_{x, y} p(x, y) \cdot \log \frac{p(x, y)}{p(x)p(y)} > $$
- $I(X; Y)$:互信息
$$ > H(X) = -\sum_{x} p(x) \cdot \log p(x) > $$
- $H(X)$:X 的香农熵
Qwen2.5-32B 平均 NMI ≈ 0.079
EAI-Distill-0.5b 平均 NMI ≈ 0.092
- Domain Recall
- 定了Golden URL(认为arxiv和……30 个 base URL的都是高质量数据)
- 统计有多少能被模型召回
Dataset
- Random Set:随机采样(需要避免撞车训练数据)
- STEM Set:从特定领域集合(科学领域)随机采样
- 通过Golden URL采样