[TOC]
被手搓大模型橄榄了,写BPE写的心态爆了
不如我们先停下来推一下一些比较有趣的课程
前言
Those token could be anything.
解析任何事物为若干有限的基本单位(token),你就可以使用生成式AI做任何事情
Auto Regressive Generation
- 自回归生成(其实就是词语接龙)
token作为文字时:语言模型
(但是不管是什么都会被称为语言模型,因为热度太大了)
本质上都是在有限的选择中做出选择完成输出
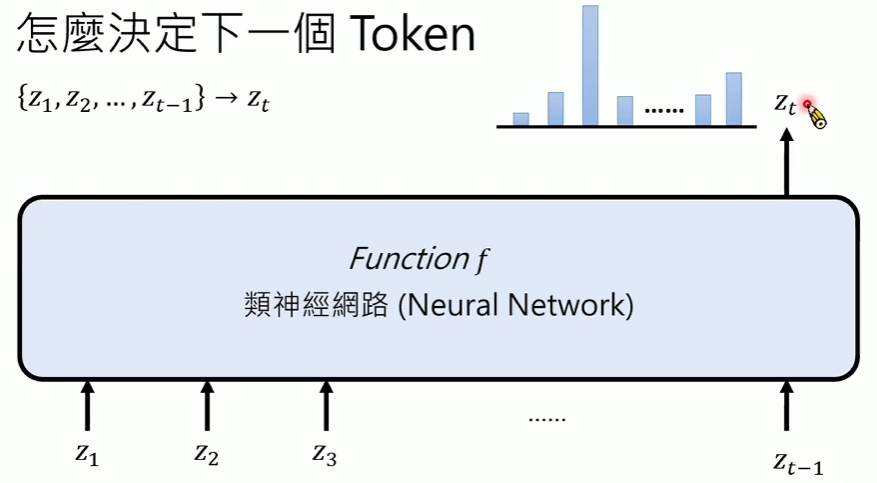
- 通过Neural Network,得到的是各个token的概率分布
- 模型架构(超参数):由人类确定
- 模型参数:由数据决定
Thinking Mode
对于现实中的问题,往往足够复杂,哪怕模型足够巨大,层数足够多,可能也无法处理
而带有思考能力的LLM表现良好,可以从模型层数的角度进行解释
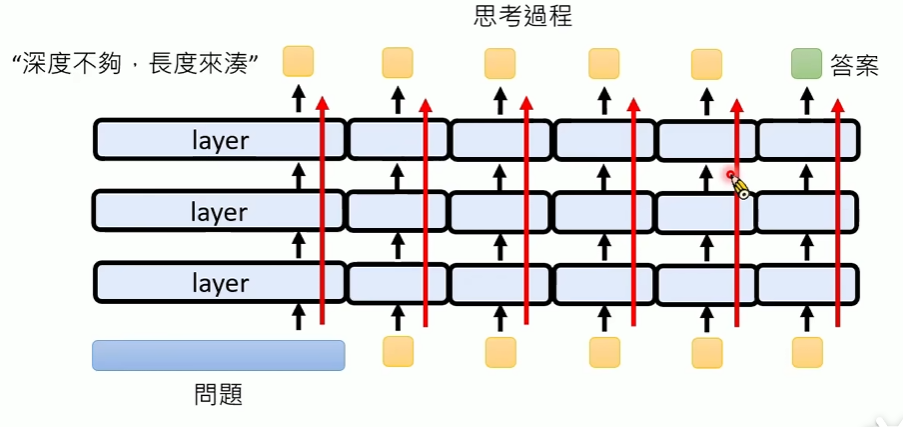
每次给定输入token集合,产生一个token的输出,模型会过一遍所有的Layer
所以只要不断思考,本质上是一直在重复这个模型Layer的堆积
因此思考长度足够,似乎是在使用一个巨深的模型进行推理
训练时缩放(Training Time Scaling):通过训练来让模型变得更强大。这需要巨大的成本重新训练模型。
增加模型参数量(scale up)
增加训练数据
延长训练时间(增加计算量)
测试时缩放(Testing Time Scaling):模型已经训练好了,参数固定不变。 我们通过一些“技巧”,在使用这个模型的时候投入更多的计算资源
生成多个答案然后挑最好的
更仔细地推理
- Testing Time Scaling:在不改变模型本身weights的情况下,仅通过改变inference或testing时的方法和计算量,就能显著提升模型性能的一种现象或技术集合。
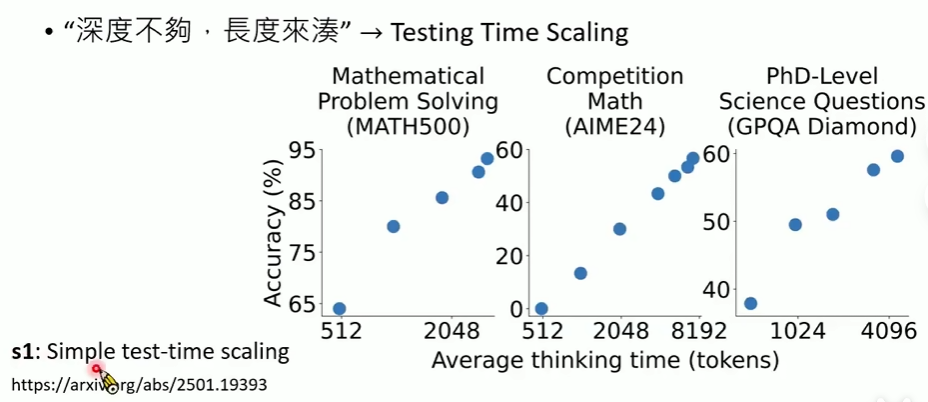
本质上是在叠加模型层数,如图,思考的token开销越多,性能确实越好
如何控制token?一个粗暴的方法,在结束的时候把end变成wait
Development
模型的演变经历了专用模型到通用模型的趋势
而通用模型的演变也非常迅速
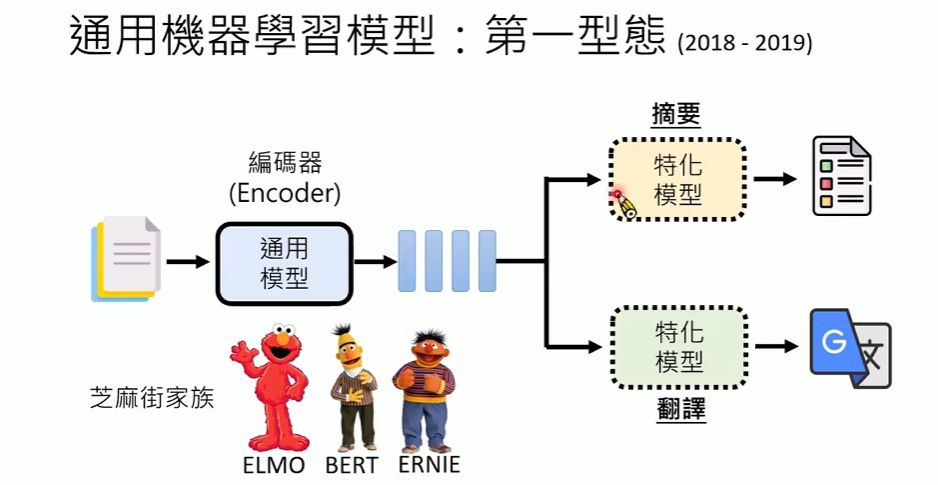
- Encoder:将文本encode成向量
- 配套专用模型完成输出
- 架构不同
- 参数不同
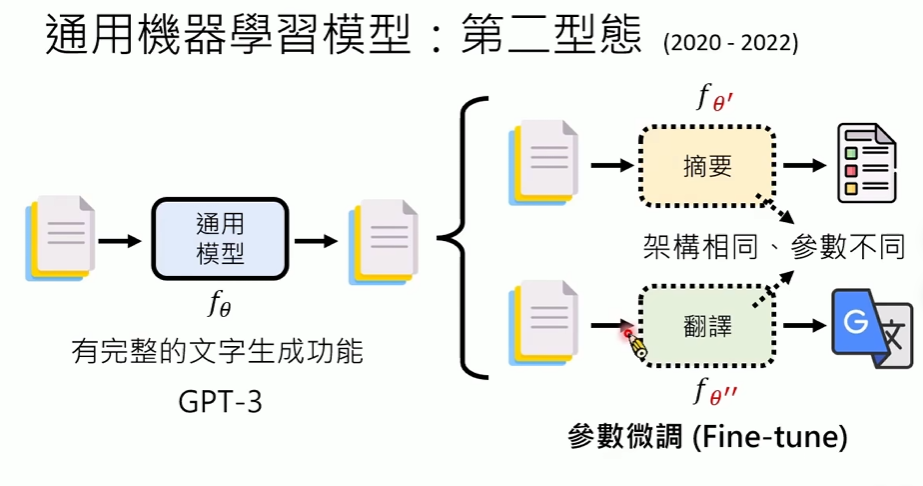
- Fine-Tune:通过微调适配不同任务
- 架构相同
- 参数不同
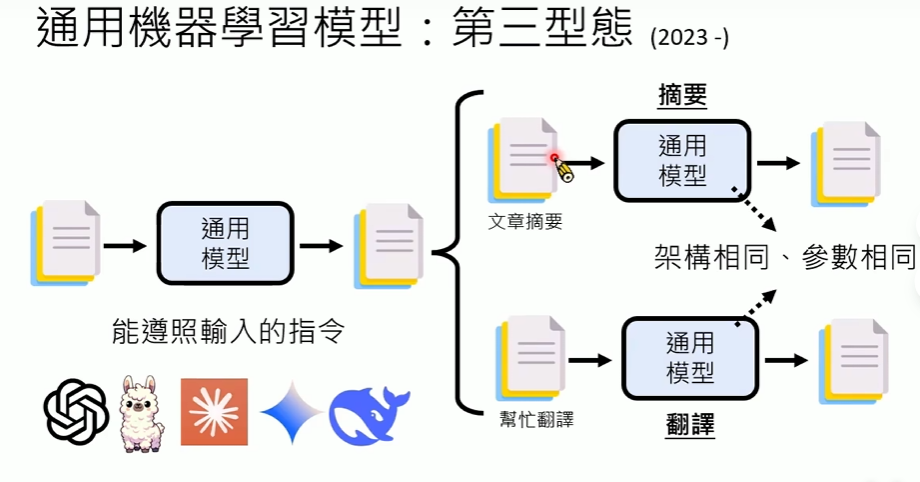
- Prompt:直接给指令做不同任务
- 架构相同
- 参数相同
Homework1就不做了,一个RAG任务,之前做过类似的