[TOC]
Agent
传统AI:给定明确步骤、指令,AI完成任务
Agent:给定目标,由Agent想办法完成
Agent将通过观察Environment,采取特定的Action
- 强化学习:通过强化学习方法得到的Agent是可行的,但是不具备通用能力(围棋Agent不能处理五子棋)
- LLM:通过文字描述进行交互,具备通用能力
Goal、Environment1、Action1、Environment2、Action2……
本质上也是在接龙
回合制的交互会比较好做,有时候会需要被实时打断
即:Action执行时,Environment变化,会需要Agent中断Action,进行新的Action
常见应用:语音聊天
Memory
交互的次数足够多时,记忆量过大,会造成Agent性能下降
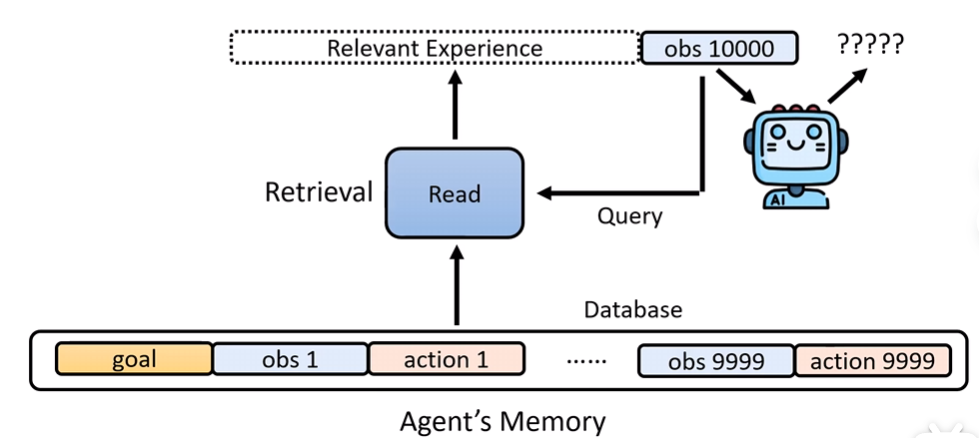
因此针对相关经验做一些记忆的检索和筛选是必要的
可以直接套RAG的技术
但这里最好不要提供模型过去的错误例子
这里的情景似乎没有做一些纠错任务,给了错误的例子性能会发生下降
因此设计Agent时需要考虑一下哪些内容是应该提供或筛除的
模型的使用技巧:
- 告诉模型应该做什么比告诉模型不要做什么效果更好
-
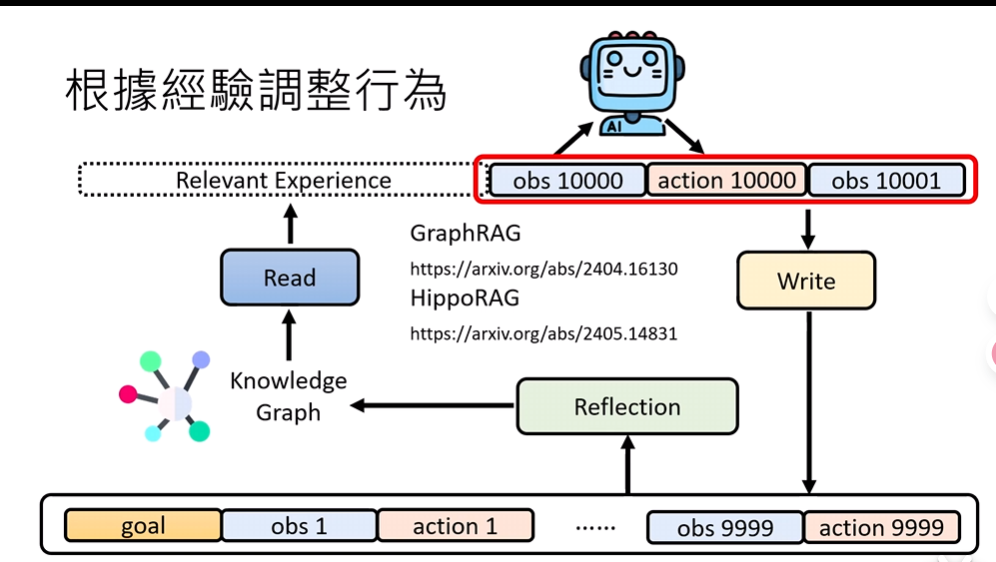
从存储角度出发
-
有些记忆没有存储的必要,因此可以引入一个Write模型去分类筛选
-
有些记忆可以被格式化、转化成更好、更通用的内容,可以引入Reflection模块做转化,存储到合适的载体中,方便Read去做RAG
-
Function Call

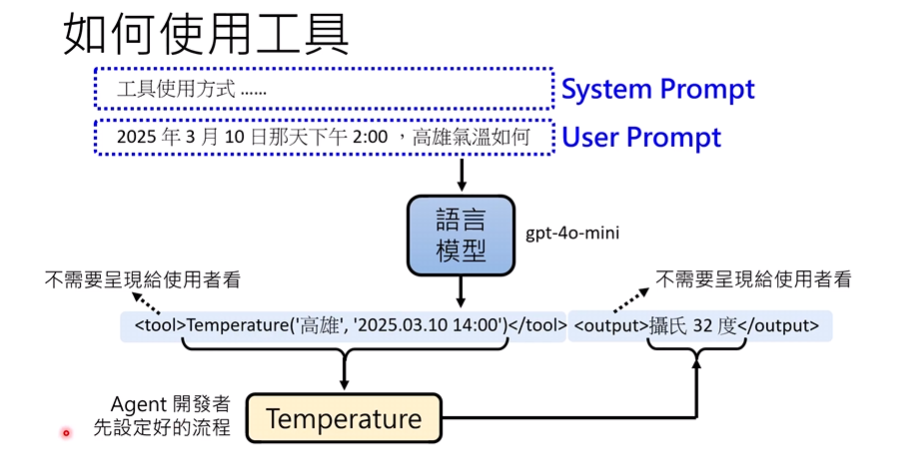
通常会把调用方法、工具列表放在System Prompt中
让用户通过User Prompt进行交互
- Function过多时,可以参考上述的Memory方法去做选择
- Agent也可以自己做一个Function,放入Memory中
Agent有时候会过度相信工具
因此需要看看模型自己是否有辨别的能力(室温10000°?不对,这里是工具出错了)
但其实加一个Reflection也不错
课堂中探索了哪些信息是容易被模型采纳的
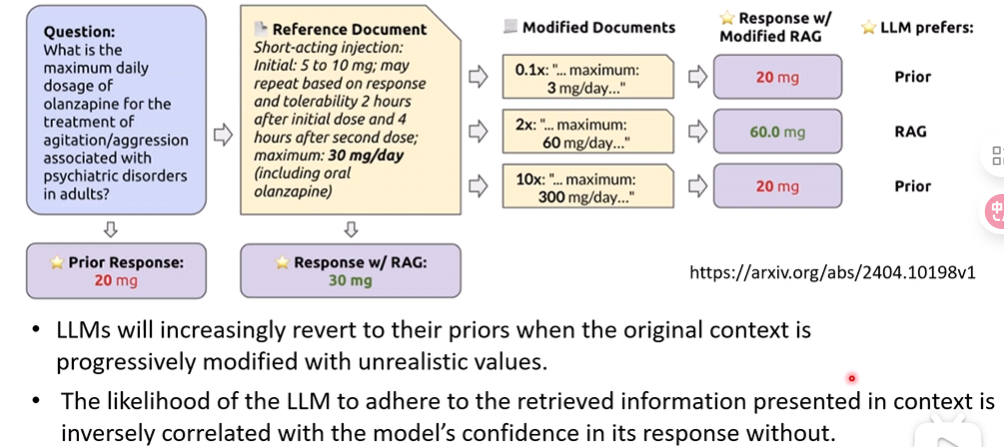
- 当原始上下文逐渐被不切实际的值修改时,LLM(大语言模型)会越来越多地回归到其先验知识
- LLM坚持遵循上下文中检索到的信息的可能性,与其在没有上下文时对自身回复的信心呈负相关。
省流:
- 外部知识如果和模型知识差距越大,模型会对模型知识更有信心;差距越小,模型更愿意相信外部知识
- 模型对模型知识的likelihood越大,对外部知识的likelihood越小
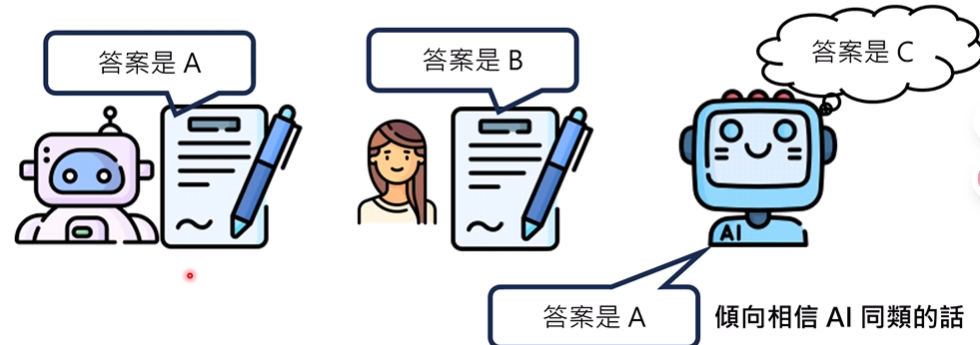
AI和人类分别给出两个意见不同的文章,AI倾向于相信AI
- Ex单独抽取了AI回答错误的例子(排除AI与AI回答类似,造成偏好的情况),但仍然是AI更相信AI
具体原因未知,猜测是AI的文章结构、表达上比人类更好
2401.11911
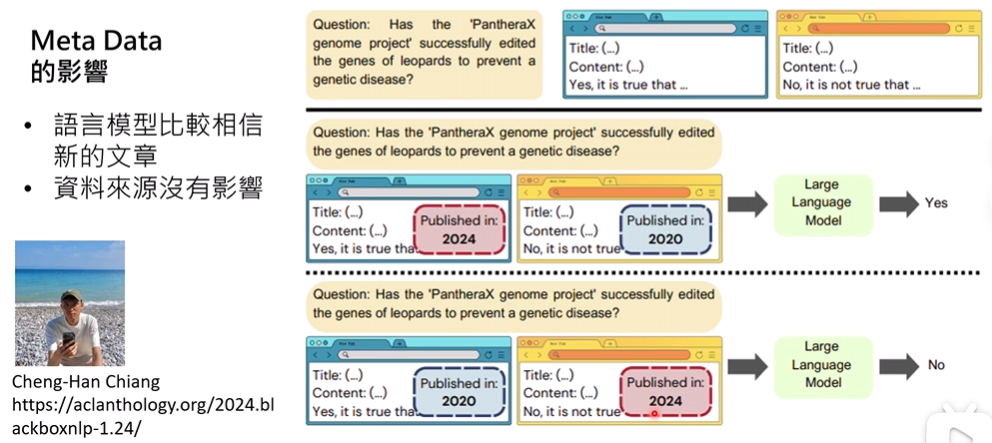
(这里首先都是用了AI生成的文章做实验,避免偏好问题,并且文章都是假的)
- Meta Data会影响模型的采纳
- 其中时间影响较大
- 资料来源写Wikipedia还是其他来源,似乎没有什么影响(这里比较反直觉)
但是实验做得似乎比较粗糙,看看就好
总结:
- 模型总会犯错
- Function Call要不要采用取决模型本身能力,如果模型可以自己解决没必要Call
Plan
目前的Agent都喜欢做一个Plan,再开始Action
但是Plan不能定太死
操作浏览器时突然出现一个广告弹窗
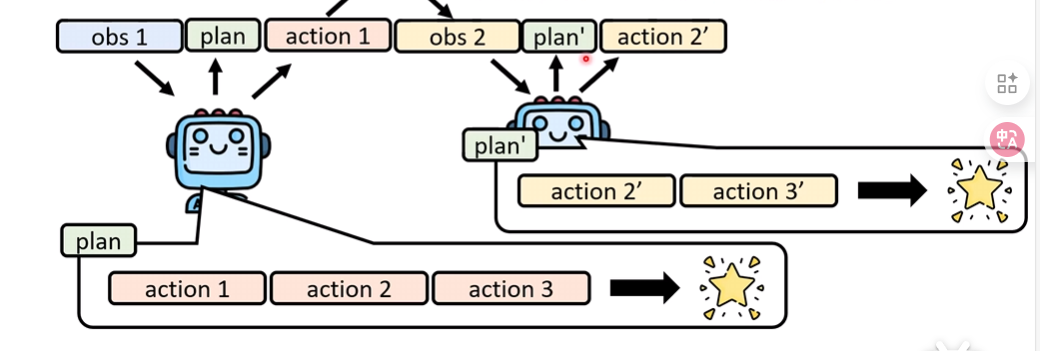
因此Plan需要灵活,一种方案是:每次思考一下Plan要不要重新制定
如何强化模型的规划能力?
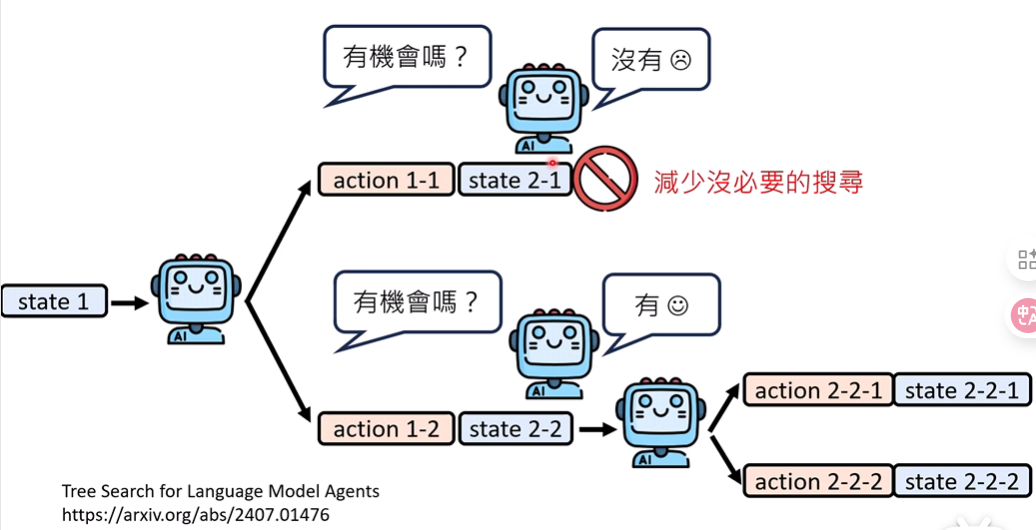
- 让模型实际去探索一下(本质是搜索)
- 可以剪枝(自问自答:当前还有机会完成任务吗?)
(不适合不容易回溯状态的任务,例如:订餐)
(但是可以引入一个World Model,让模型扮演环境本身去做反馈,模拟)
从Agent的角度去看待模型Thinking Mode:
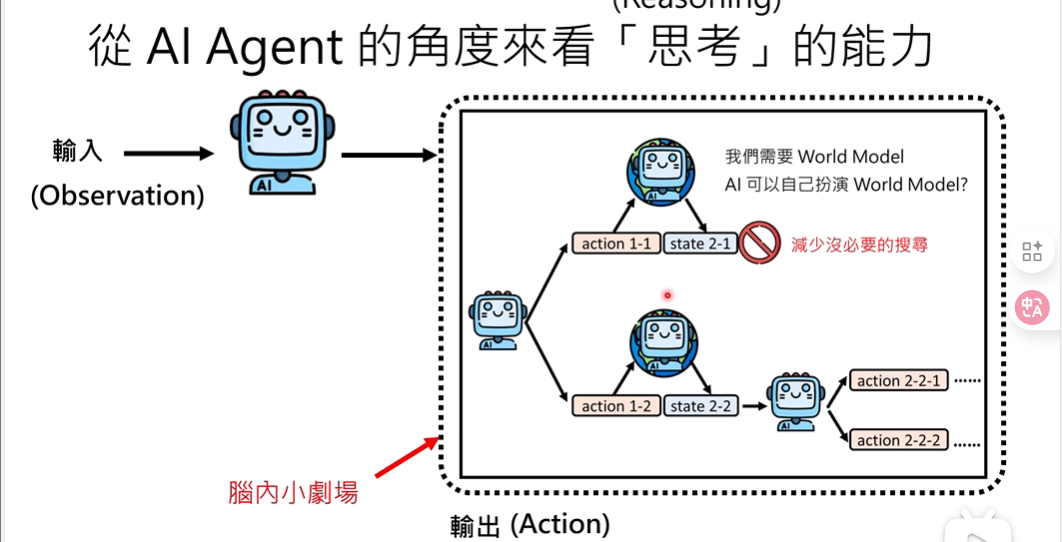
一些杂谈:
- 做benchmark或一些实验的时候,思考一下这个任务LLM会不会在互联网数据中提前得到