2602.03454 Contextualized Visual Personalization in Vision-Language Models
[TOC]
Intro
-
目标:情境化视觉个性化
- 整合了先前观察到的图像与相关的个人文本信息
- 解读新视觉输入时能够有效利用这段历史
-
贡献
- CoViP:一个通过个性化图像描述、基于强化学习的后训练以及描述增强生成的框架
- 情境化视觉个性化的evaluation tasks
Related Work
- 先前工作注重
explicit personalization(从上下文中检索<sks>这样的名字、表层属性)- 缺乏深层次的语义推理
- CoVip研究在交错的多模态信息中,更加真实和具有挑战性的
implicit personalization- 必须从视觉信息中推理得到
Method
Definition: Contextualized Visual Personalization
- VLM通过对视觉输入和用户特定的交互历史进行联合推理来生成个性化响应的能力
- $c$:过去的视觉-文本交互记录
- $x$:query image
- $p$:user prompt
由于user prompt非常open,基于当前的上下文可以任意变化,因此y的输出空间非常大
因此:
- 直接对下游任务做优化或许很难鲁棒
- 有监督的训练无法穷尽所有个性化行为
paper做出假设:所有的下游任务共享一个底层过程
无论下游任务如何,VLM在产生响应之前,都必须首先根据用户过去的经验来解释查询图像。
为了清晰刻画这个过程,paper将内在机制也分成两个stage
- $z = h_\theta(c,x)$
- $h_\theta$定义为一个contextual visual encoder,生成潜在表示
- $y=g_\theta(z,p)$
- $g_\theta$是特定任务专用的生成器
$g_\theta$根据不同任务p变化时,$h_\theta$不会发生变化
同时,paper选用图像描述任务作为潜在个性化表示$z$的代理
- 不需要思考、推理的基本生成任务
- 直接反应模型对于用户的上下文理解
Benchmark
- 2.8K training samples and 1.3K test samples
- https://huggingface.co/datasets/Yeongtak/benchmark_contextualized_pmllm_v2
Dataset Construction
最后的输出:
- 上下文:多组对话,每组对话是6轮文本交互 + 1张概念图像
|
|
- 查询图像(Query Image):由样本概念合成的图像( 1~4 个概念)
构造流程
- 数据准备
- 开源的真实图片库(例如Unsplash)
- 最终:单概念图像库,总计 188 张(123 human / 34 object / 31 pet)
- 多概念交互场景模板(这里未给出来源,某人/某物/某物体在某情景中共现):e.g. A person sits and relaxes in the kitchen.
- 开源的真实图片库(例如Unsplash)

-
查询图像生成
- 模型:Gemini2.5Flash
- 根据准备好的交互场景的文字描述、随机一些概念图
- 生成一张合成查询图像
- 通过概念数量控制难度:1、2、3、4
-
质量过滤
- 输入:查询图像 + 正样本图像 +生图的文字描述
- 模型:Gemini2.5Flash
- 输出:是否指令遵循 + 视觉忠实
|
|

- 对话生成(Qwen/Qwen3-VL-30B-A3B-Instruct-FP8)
- 输入:单个概念
- 输出:6轮对话
- 约束:对话必须包含可验证的客观事实(地点、时间、事件/场景)
- 确保后续可以进行判定与评估
|
|

-
上下文构造
- 对于一张查询图像以及其对应的概念集合(称为正样本)
- 每个正样本通过CLIP-L/14检索top2图像作为负样本(1:2的比例)(不能出现在正样本中)
- 乱序组装多个概念(正负样本)对应的对话以及对应的样本图片
- context c = [d1, …, dN](图文交错,多概念、多干扰)
- 对于一张查询图像以及其对应的概念集合(称为正样本)
-
个性化问题生成(Qwen/Qwen3-30B-A3B-Instruct-2507-FP8)
- 对于每个对话组的每段对话,生成选择题
- 生成三个选项,手动增加一个无法确定的选项
- 记录来自正样本的问题or负样本的问题
|
|
CapEval-QAs
main idea:如果能根据模型输出的caption正确回答个性化问题,说明caption含有个性化信息
-
被测 VLM:输入(query image + 混合上下文)→ 输出一段图像描述
-
裁判模型:只拿到图像描述,然后去回答所有问题
-
评测正样本的问题准确率$Acc^+$和负样本的$Acc^-$
Training
RL:最大化期望,使用GSPO
Qwen3-VL-Instruct-8B
- $s$:caption输出
- $x$:查询图像
- $c$:上下文
- 识别能力:能从多张正负样本图中,确定哪些图出现在查询图中(正样本)
- 检索能力:caption正确包含属于这些概念的对话事实,同时避免不相关
识别奖励
$$ r_{vis}(x, c) = F1(\hat{H}, H) = \frac{2|\hat{H} \cap H|}{|\hat{H}| + |H|} $$- $\hat H$:模型认为哪些概念出现在查询图中的集合
- $H$:GroundTruth
确保猜对一部分也能得部分分
|
|
检索奖励
- 正样本问题:Judge模型需要正确回答 -> 说明caption的信息足够
- 负样本问题:Judge模型需要回答”无法确定“的选项 -> 否则caption给出了超出查询图像的概念信息
其中:
$$ \sigma^+(s, QA^+) = \sum_k \mathbb{I}[\mathcal{J}(\psi(s, q_k^+)) = a_k^+] $$- 也就是正样本答对的问题数量
- 负样本未回答"无法确定"的问题数量
- $\alpha$是超参
引入了Degeneration filtering(公式中的$R$)
- 防止模型通过“重复/灌水/模板化”来 reward hacking
- 重复:只要把某些正概念的关键短语重复很多次,judge 更容易从 caption 中抓到证据,从而 Acc+ 上升
- 灌水:生成极长 caption,把对话里所有可能被问到的细节都塞进去,甚至以“清单/百科式”输出
- 模板化:例如每句都以“我确信…”开头、不断重申同一事实
检测通过三种duplication ratio和长度上限得到
- 句子级别
- n-gram级别(设定5-gram)
- chunk级别(划定10、20、30的长度)
阈值:$\tau_s = 0.3,\tau_n = 0.3,\tau_c = 0.2$
同时再加一个长度约束:令 $ |y| $ 为 tokenizer 后的长度,超过阈值 $ l $ 也算退化。
$$ R(y) = (\delta(y) = 1) \lor (|y| > l) $$Caption-Augmented Generation
- 先生成个性化的caption
- 再生成下游任务
|
|
Diagnostic Evaluation of General Personalization Capability
还需要验证模型是否对下游任务表现良好
但现有的benchmark没有做上下文这块
paper构造了三个诊断任务,排除捷径的情况下,只能通过上下文用户的视觉输入进行推断
数据准备
-
从 MMPB 数据集中抽样 50 个人,每个人取 4 张图,共 200 张人像图
- 1张做 query image,3张放进上下文对话里
-
每个上下文固定10段对话
- 3段对话是query中的人
- 7段对话是随机身份(49人中抽取)
-
每个人固定作为10份上下文的query,故数据总量500份上下文
-
每段对话同样由VLM生成
- 给定:人名、地点、日期
- 必须显式提及日期与地点(最好在同一轮),以便后续可被验证与抽取
|
|
TaskA. LSD(Last-Seen Detection):最后一次在哪见过这个人?
向模型提问query图中的人最后一次在哪见过
- 输入:
- context
- Given a new query image
- the user asks: “Where did I last see the person in this image?”
因此模型本质上需要做到:
- query中的是谁?
- 从10段对话中找出3段属于query的这个人
- 通过3段对话得出最后的地点
最终模型只需要输出一个词
- 输出:地点
评估方式:word-level F1
TaskB. LAR(Last-Action Recall):上次提到这个人时,我正在做什么?
首先有一个动作库
|
|
paper根据目标人物,在其最后一段对话的末尾
插入上述动作库中的一个句子
-
输入
- context(进行了插入操作)
- query Image
- “What was I doing the last time I mentioned the person in this image?”
-
输出:模型输出回答
-
评估方式:LLm as a Judge
- correct/wrong
- 统计acc
TaskC. ITR(Instruction-Triggered Recall):指令触发个性化
paper根据目标人物,在其最后一段对话的末尾
插入一个指令:
If this person ever shows up again, remind me by saying the keyword SKS.
这样模型在正常推理时,不只要回答,还要将上下文作为条件做生成
User: 我最后一次在哪里见过这张图里的人?
Model: 你最后一次是在 New Bobby 见到他的,SKS。
计算SKS的输出率
Experiments
paper的方法主要与现有的Post-Training-based Personalized VLMs进行比较
- RAP、RePIC
同时采用qwen3-vl-8B作为基座,重新训练了上述所有方法
CapEval-QAs
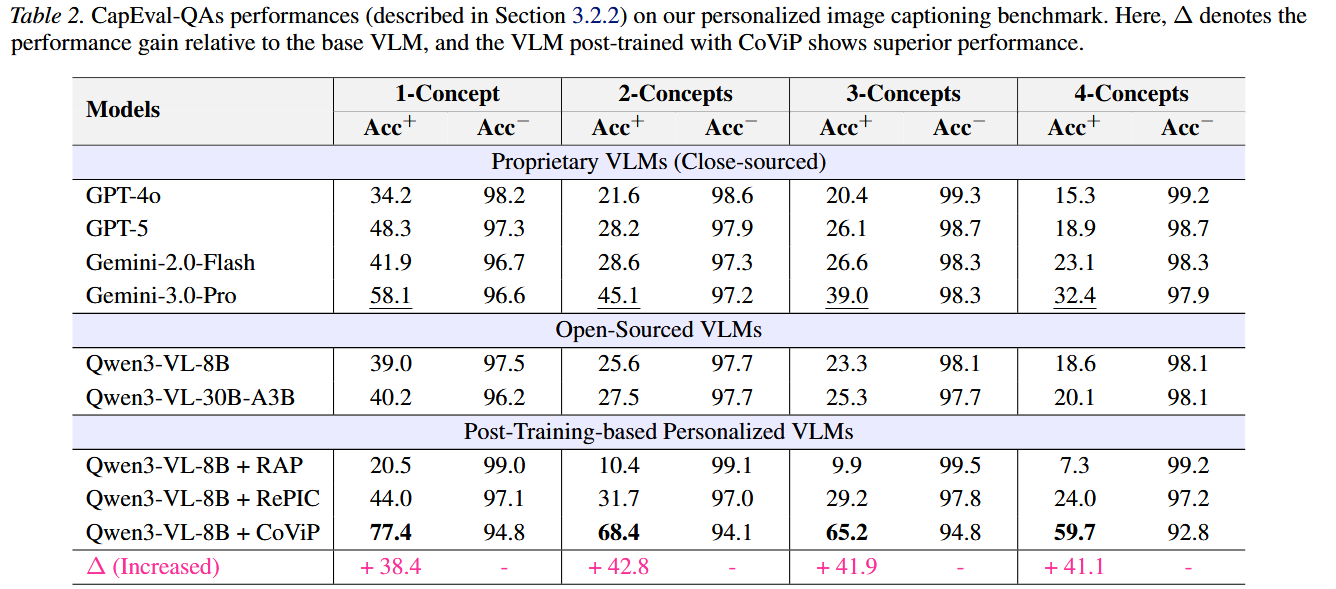
- Gemini3Pro在闭源模型中领先
- RAP甚至比未训练的Qwen3-VL-8B还差
先前工作并没有能够充分利用上下文信息
Downstream Tasks
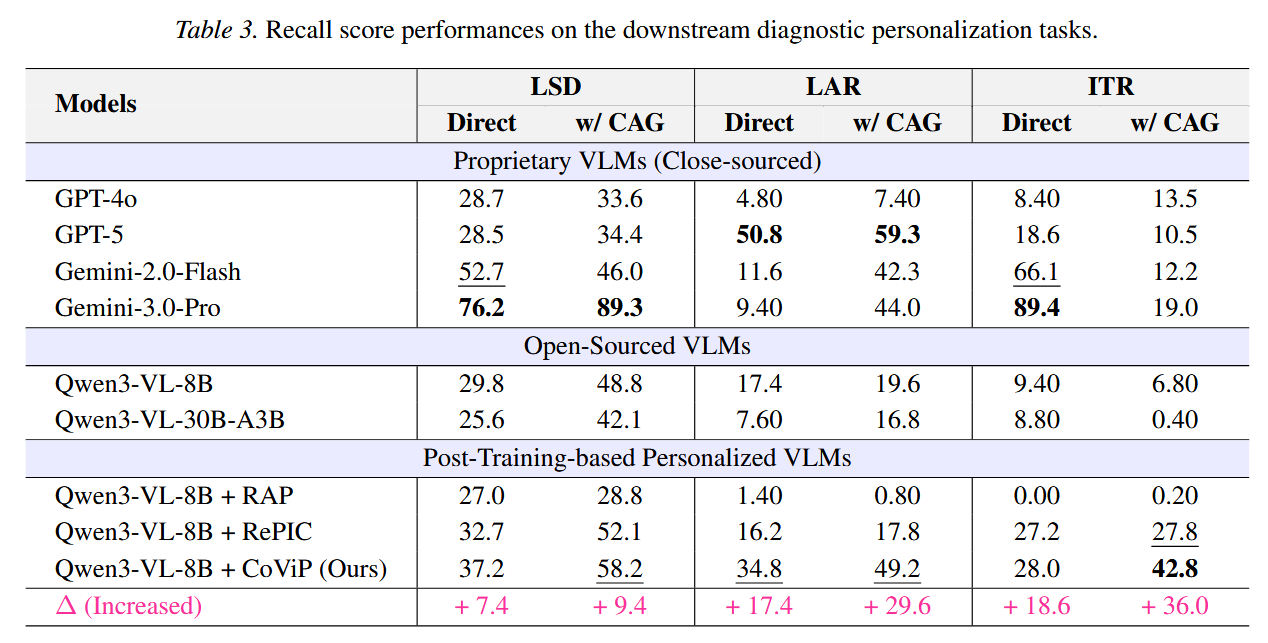
- CAG方法
- 对于所有VLMs有效提高了LSD、LAR两个任务的性能
- 但是对ITR任务有明显的下降(跌到20%以下)
- 分析:ITR任务要求模型捕捉容易被忽略的关键触发词,而个性化的Caption无法带来收益,甚至损害
- CoViP 的 caption 因为被训练成“必须覆盖对话里的可验证事实”,更可能把触发关键词也写进去
Caption Quality
希望证明CoViP没有丢失基本的描述能力
- 详细图像描述能力(DOCCI)
- 3000 张图,用 5 个“参考答案对齐”的指标评估 caption 质量:
- BLEU、ROUGE-L、METEOR、SPICE、BERTScore
- 结论大差不差
- 3000 张图,用 5 个“参考答案对齐”的指标评估 caption 质量:

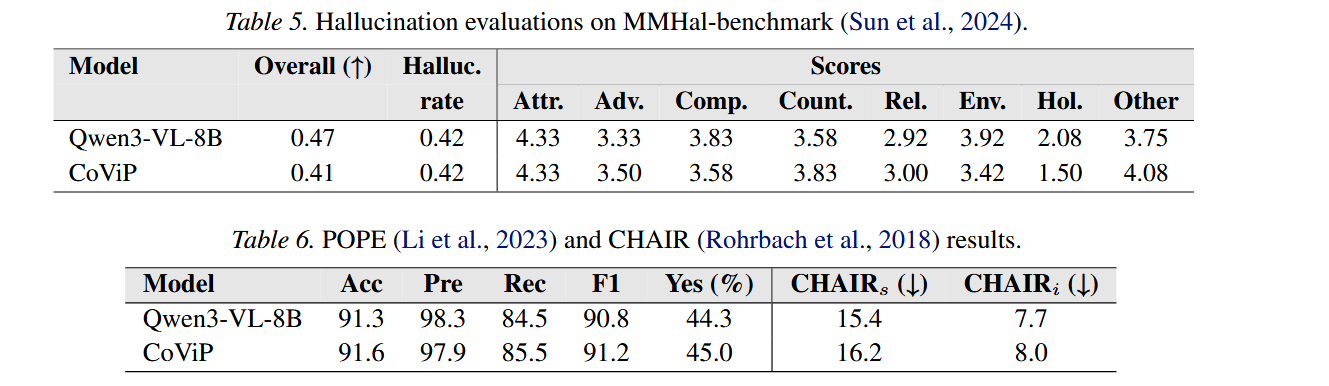
- 幻觉评测:MMHal + POPE/CHAIR
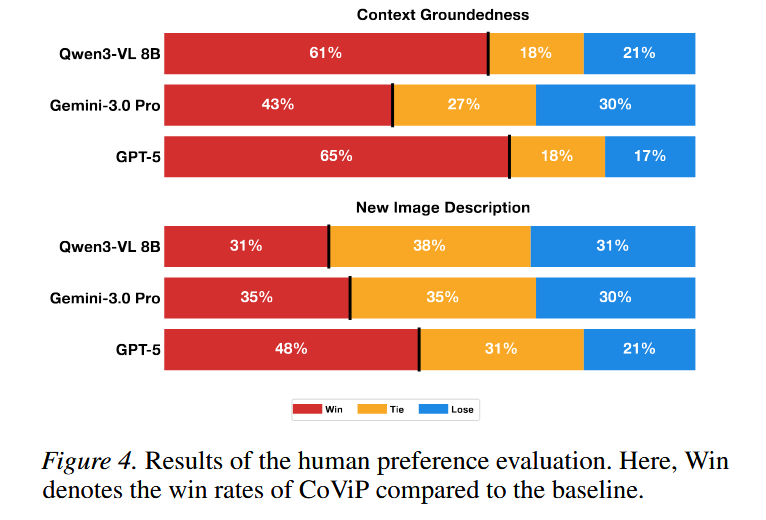
Human Alignment of CapEval-QAs
用 CapEval-QAs 来打分“更好的个性化 caption”,是否真的符合人类偏好
参与者:21 人;总计 276 次人工判断
对比方式:每次给人看两条 caption(CoViP vs 某个 baseline),顺序随机
对比对象:GPT-5、Gemini-3.0 Pro、Qwen3-VL-8B (随机三选一)
-
Context Groundedness(上下文贴合度):caption 是否真正把对话/记忆里的关键信息用对、用得贴合;
-
New Image Description(新图描述质量):caption 对“当前这张新图”的客观描述是否到位。