[TOC]
Stanford CS336 | Language Modeling from Scratch
第一节课没记笔记,更像是一个概览问题不大,从第二节课开始,记录一下细节的东西
Memory accounting
至少对于Pytorch来说,tensor是一切的基础,从参数、梯度、优化器、激活值、数据……都是张量
因此核算内存,本质上就需要搞清楚张量的内存存储
-
float32(fp32):单精度浮点数
- **符号位(Sign)**1 + **指数位(Exponent)**8 + **尾数位(Fraction)**23
- 对float64确实挺菜的,但是对机器学习来说很顶级(被称为全精度)
- Pytorch默认类型,占用4bytes
-
float16(fp16):半精度浮点数
- **符号位(Sign)**1 + **指数位(Exponent)**5 + **尾数位(Fraction)**10
- 已经无法表示1e-8(下溢出)
-
bfloat16(bf16):半精度浮点数
-
**符号位(Sign)**1 + **指数位(Exponent)**8 + **尾数位(Fraction)**7
-
动态范围与float32一致(只不过有效数字变少了)
-
-
……还有很多
有效数字其实没什么关系,bf16保证了我们至少可以表示一个非常小的数字,只不过精度较低
fp16对于同级别的小数字,会直接变成0
对于推理,你完全可以使用bf16,效果没有问题
但是存储优化器状态、参数,你最好还是保留fp32,更别说训练阶段
在一些任务中,会对一些数据进行极致优化(混合不同的精度,尽量降低内存)
Compute accounting
- Floating-point operation(FLOP)
- FLOPs:operations(指浮点运算次数)
- FLOP/s(FLOPS):每秒的浮点运算次数
- cost
- GPT-3:3.14e23 FLOPs
- GPT-4:2e25 FLOPs
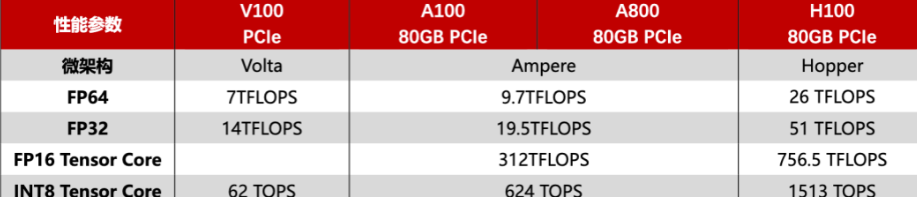
有时候数据标的是稀疏矩阵的速度,但是大部分时候是稠密的,性能会损失一半
$$ > FLOPs = 2\times B\times D\times K > $$当然底层的优化使得我们不需要做到这个数量,但作为数量级的估算仍然是合理的
同时矩阵乘法是最贵的,因此我们一般只根据矩阵乘法进行估算成本
Forward
$$ Y = xW $$则我们认为数据$x(B,D)$,根据参数$W(D,K)$进行前向传播
$$ FLOPs = 2\times \text{tokens}\times \text{params} $$这个推广到Transformers的模型也是大差不差的
$$ MFU = \frac{actual\space FLOPs}{real \space FLOPs}\times 100\% $$实际达到的 FLOPs 与硬件理论峰值 FLOPs 的比值(百分比),衡量了对硬件资源的利用效率
尽量保证在0.5以上
Backward
对于反向传播,我们需要花费一些在维护梯度上
$$ Y = xW $$为了做一次反向传播,我们会根据$\nabla_Y$进行维护(损失函数对$Y$的梯度)
$$ \nabla_W = X^T\nabla_Y $$$$ \nabla_X = \nabla_YW^T $$$$ FLOPs = 2\times D\times B \times K + 2\times B\times K\times D = 4\times \text{tokens}\times \text{params} $$综上所述:
- 推理开销:前向 $2\times \text{tokens}\times \text{params}$
- 训练开销:前向+反向 $ 6\times \text{tokens}\times \text{params}$
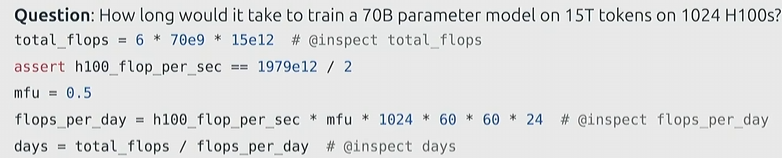
到这就能回答课题开始的问题了

Assignment 1
Byte-Pair Encoding Tokenizer
Unicode对每个字符都定义了一个整数进行对应,但是我们不会直接使用Unicode去做分词
- 数量过大(大约 150,000 个字符)
- 大量生僻字符
因此我们更倾向于对Byte而不是Char进行建模
- byte的取值范围是0-255,相对可接受
UTF-8等被称为编码方式,是一种变长编码,基于字节去表示Unicode字符
更方便了计算机的传输与存储
对于常用的字母数字,通常只需要1个字节(ASCII),汉字需要3字节
使用贪婪匹配
相当于我们把Char进一步拆分,变成Byte级别进行处理,降低规模
|
|
非ASCII码是通过转义表现的(超过1个字节)
- 但是字节会使得整个序列变长(原本10token的序列可能就要变成50)
因此BPE对高频出现的字节进行替换与合并(比如说the),使用未出现的索引代表
构建字节和字节合并序列的过程就是在构建一个词汇表,这个过程也被称为分词器的训练
BPE Tokenizer Training Theory
分为三个阶段
- Vocabulary Initialization:词汇表就是字节到整数id的映射,在最开始,我们只需要管理256种字节(会添加一些额外的特殊记号,例如
endoftext,表示文档的末尾) - Pre-Tokenization:将文本分成更大的单元(称为 pre-tokens),而不是直接处理单个字节或字符
- 实现1:
.split(' '),虽然简单,但是无法处理复杂任务 - GPT-2的实现:正则表达式
PAT = r"""\b(?:[sdmt]|[ll|ve]re)|\p{L}+|\p{N}+|[^\s\p{L}\p{N}]+|\s+(?!\S)|\S+"""- 匹配特定的缩写形式,如
s,d,m,t,ll,ve,re等。 - 匹配连续的字母、数字字符、非空白字符。
- 匹配非空白、非字母、非数字的字符序列(通常是标点符号或其他特殊字符)。
- 匹配尾随的空白字符
- 匹配特定的缩写形式,如
- 实现1:
|
|
一个初步的想法:遍历整个语料,统计所有字节相邻出现的频率,例如
th,he,in等(这里用字符代表一个字节)然后我们选择出现频率最高的相邻字节进行合并,但是我们要往下继续做的话,就需要重新统计一次语料的字节频率,这样效率极低
而且这个方案会造成:
dog!和dog.语义本身一致,但是被一些奇怪的字节产生区分,分配不同的 token ID,这样会导致模型学不到通用的表示因此希望引入Pre-Tokenization:
例如:Hello, world! I’ll see you tomorrow.
预分词:[
Hello,,,,world,!,,I,',ll,,see,,you,,tomorrow,.]这里我们就不需要遍历语料库了,比如我们可以直接知道
Hello的数量,我们只需要对每个pre-tokens单独维护贡献,乘以其频率即可并且成功避免了一些标点符号的影响
具体示例看下文
- Compute BPE merges:在pre-tokens内计算相邻字节的出现频率,每次选择全局频率最高的两个合并成一个
注意,<|endoftext|>等特殊标记由于其特定功能,是不会被合并到合成字节中的,强制占用一个vocabulary里的位置
对于文档:
1 2 3low low low low low lower lower widest widest widest newest newest newest newest newest newest
- Vocabulary:初始化256个字节,以及特殊标记
- Pre-tokenization:为了简化问题,这里使用空格切分
1{low: 5, lower: 2, widest: 3, newest: 6}
- Merges
我们依次查看每一个pre-token:
low:被切分为lo和ow两个相邻字节对,贡献为{"lo": 5, "ow": 5}lower:{"lo": 2, "ow": 2, "we": 2, "er": 2}- ……
最后合并每一个pre-token的贡献
1{lo: 7, ow: 7, we: 8, er: 2, wi: 3, id: 3, de: 3, es: 9, st: 9, ne: 6, ew: 6}
es和st的频率最高,选择字典序最高的st(这里更多是保证标准一致,没有特殊理由,好处是只需要比较一下就好,是非常方便的做法)继续迭代,注意所有
st将被认为是一个字节
low:{"lo": 5, "ow": 5}lower:{"lo": 2, "ow": 2, "we": 2, "er": 2}widest:{"wi": 3, "id": 3, "de": 3, "e st": 3}newest:{"ne": 6, "ew": 6, "we": 6, "e st": 6}重复以上过程即可
迭代6轮得到的vocabulary:
's t', 'e st', 'o w', 'l ow', 'w est', 'n e'根据这个词汇表,
newest就会被表示为ne和west两个token
Experimenting with BPE Tokenizer Training
数据集:
|
|
- 可以使用其中的一小部分进行调试(验证集就行),不建议上来就整大的