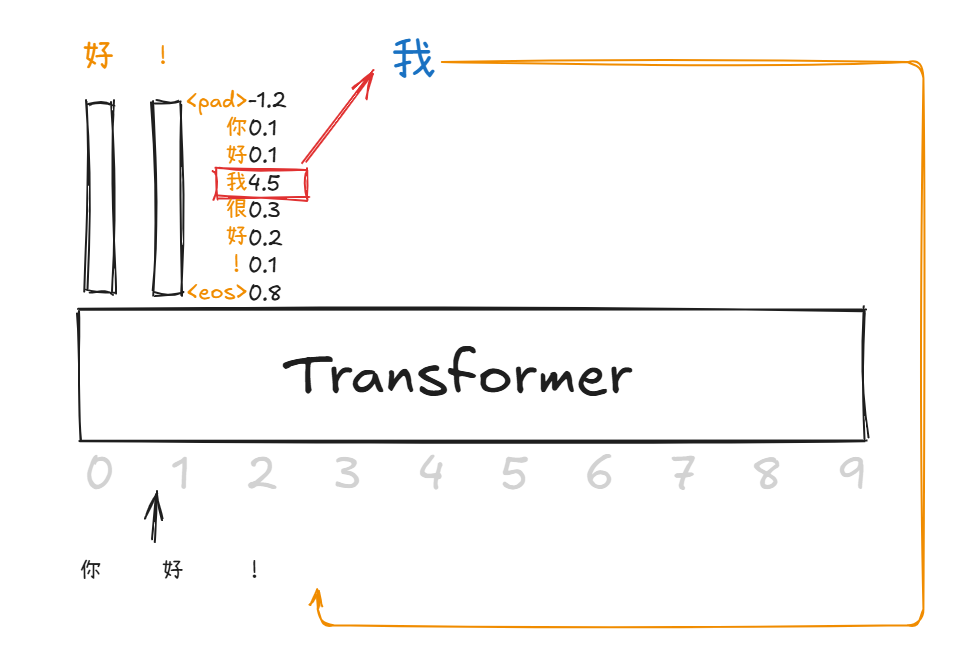
AR LLM
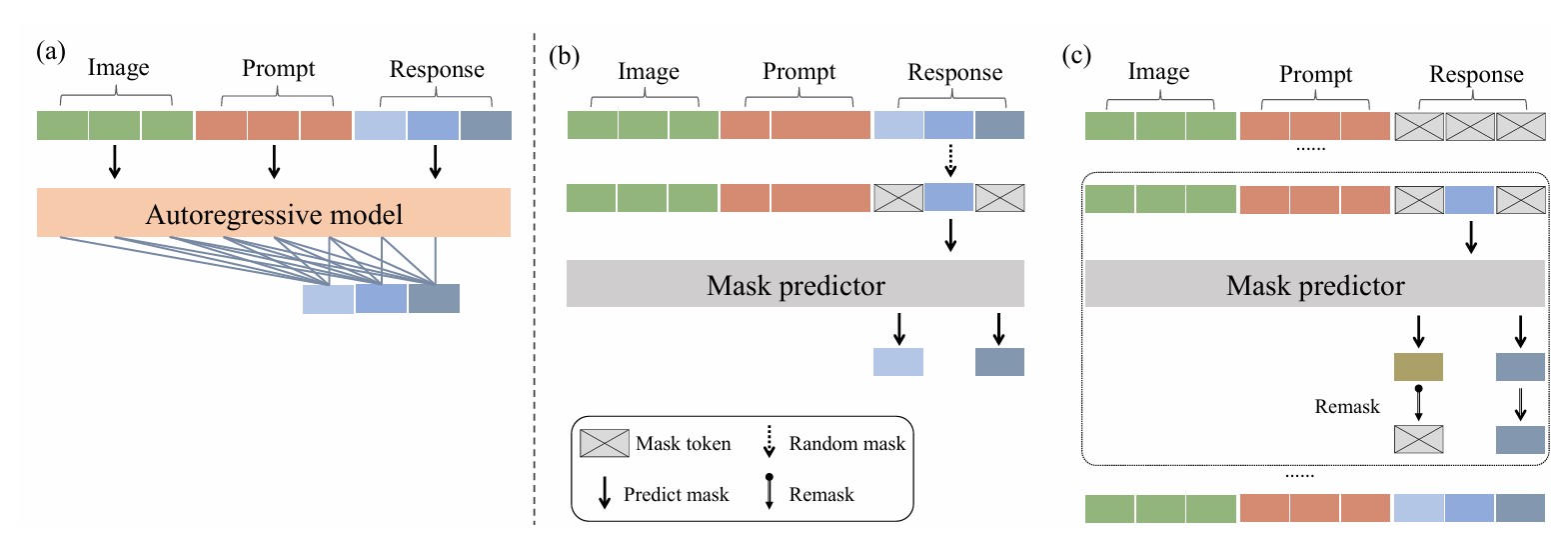
对于自回归模型,假设输入是:[你, 好, !]
词汇表是:
|
|
[TOC]
Dream 7B: Diffusion Large Language Models
2508.15487 Dream 7B: Diffusion Large Language Models
- 问题:
- AR模型对于需要整体考虑的任务(长期规划、多约束)场景表现差
- AR模型对于长文本的一致性较差
- 在各类通用任务中,要达到与Qwen2.5等顶尖自回归模型相当的性能仍存在显著差距
- 贡献:
- 基于自回归的LLM 初始化和上下文自适应噪声调度技术来实现扩散语言模型的规模化训练
- Dream 7B Base和Dream 7B Instruct
Approach
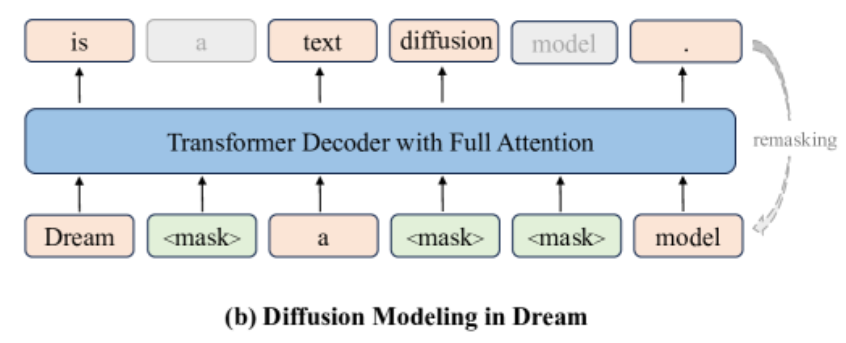
- 使用Transformer以偏移方式,预测所有
[MASK]
常规的MDM是直接预测对应位置的[MASK],需要重新训练一个新的Transformer
AR-based LLM Initialization
自回归模型的训练目标就是使用第$i$个隐藏状态预测$i+1$的token
因此我们以偏移方式进行预测,没有打破这种位置关系
因此将已有的自回归模型参数作为初始值
- 保留AR模型的知识
- 加速收敛
Context-Adaptive Token-Level Noise Rescheduling
先前衡量噪声程度一般都是句子级别的:LLaDA衡量某个句子在$t$时刻的权重是$\frac{1}{t}$
本文发现不同token之间的上下文信息是不同的,因此需要对噪声的衡量更加精细,避免学习的不平衡
公式化地,定义损失函数:
$$ L(\theta) = -\mathbb{E}_{x_0,t,x_t}\sum_{i=1}^{L}1\left [x_t^i=M\right] \cdot w(t,x_t,i) \cdot \log p_\theta(x_0^i\mid x_t) $$对于LLaDA,其$w(t,x_t,i) = \frac{1}{t}$
考虑对于某个token的上下文信息:
- 距离越近的
unmask的token提供的信息越丰富
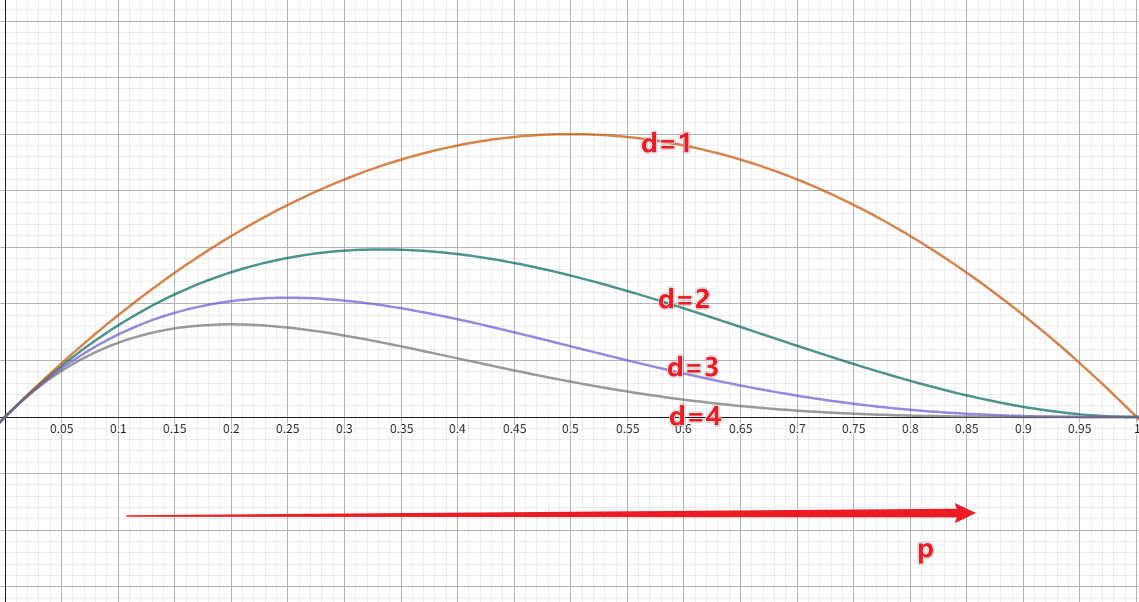
因此论文定义为:
$$ w(t,x_t,i) = \frac{1}{2}\sum_{j=1}^L\left [x_t^j\neq M\right] Geo(p, |i-j|-1) $$其中$Geo$表示几何分布核:
$$ Geo(p,d) = (1-p)^d\cdot p, \quad d\geq 0 $$- 距离$d$越大,贡献越小
- 超参数$p$:
Train
-
Dream-7B采用了与Qwen2.5-7B完全相同的Transformer架构配置
-
Pretrain
-
SFT
采用了之前的技巧,训练上与LLaDA没什么不同(注意损失函数)
Experiment
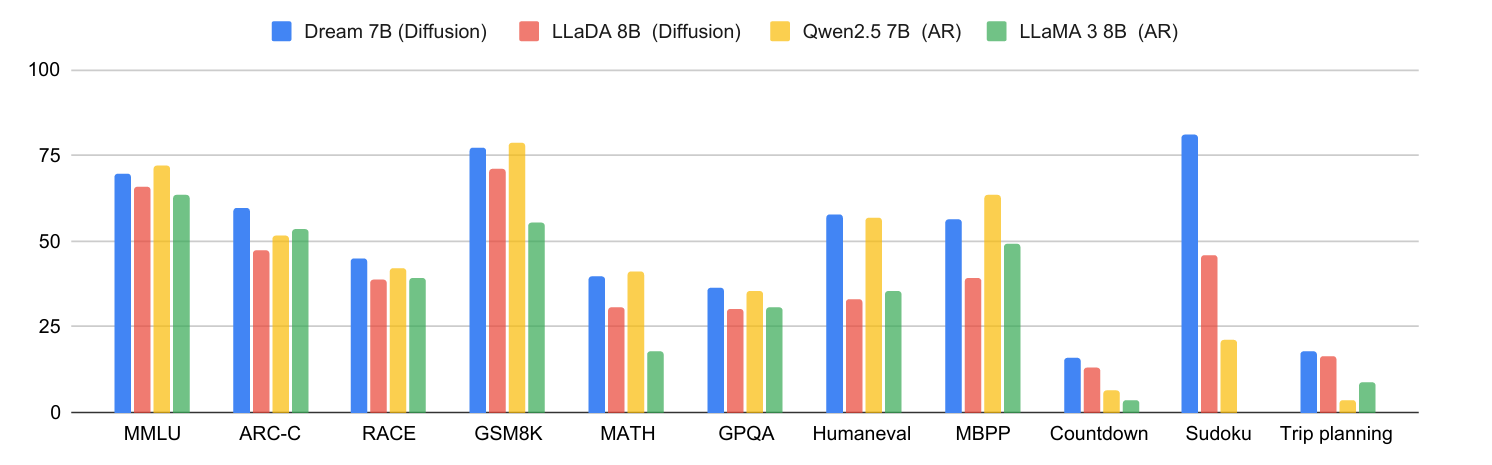
Base模型
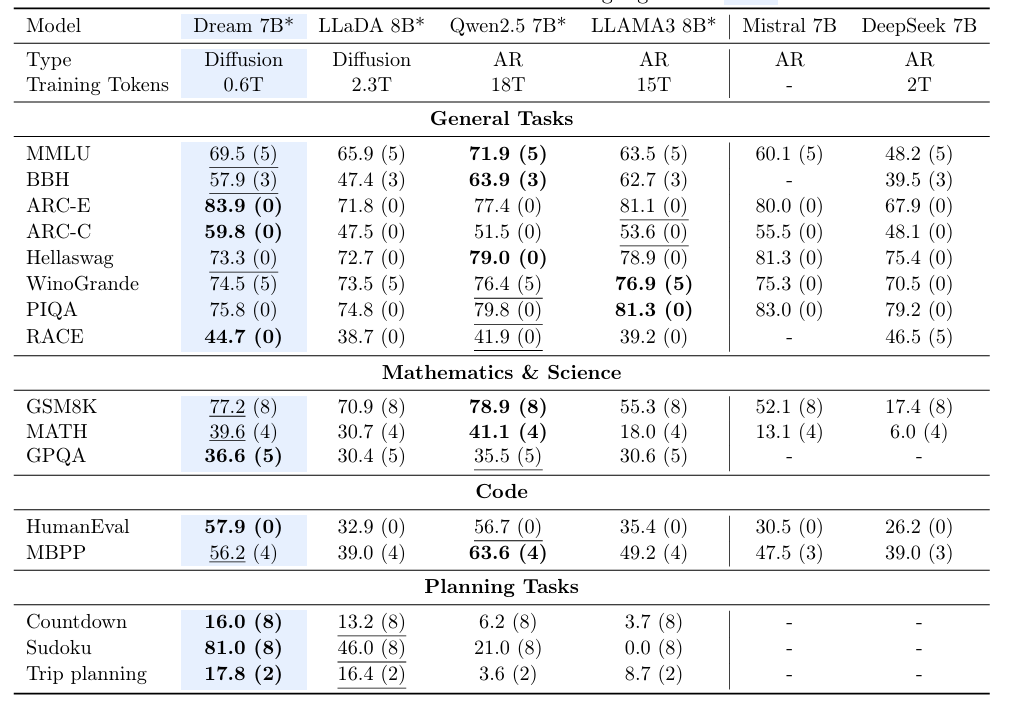
-
推理任务中(ARC-E、ARC-C)表现良好
-
规划任务中领先幅度巨大
-
训练数据量非常小
结论:
- 初始化策略和上下文自适应噪声调度有效性
Dream-Instruct
180万条数据,进行3轮微调
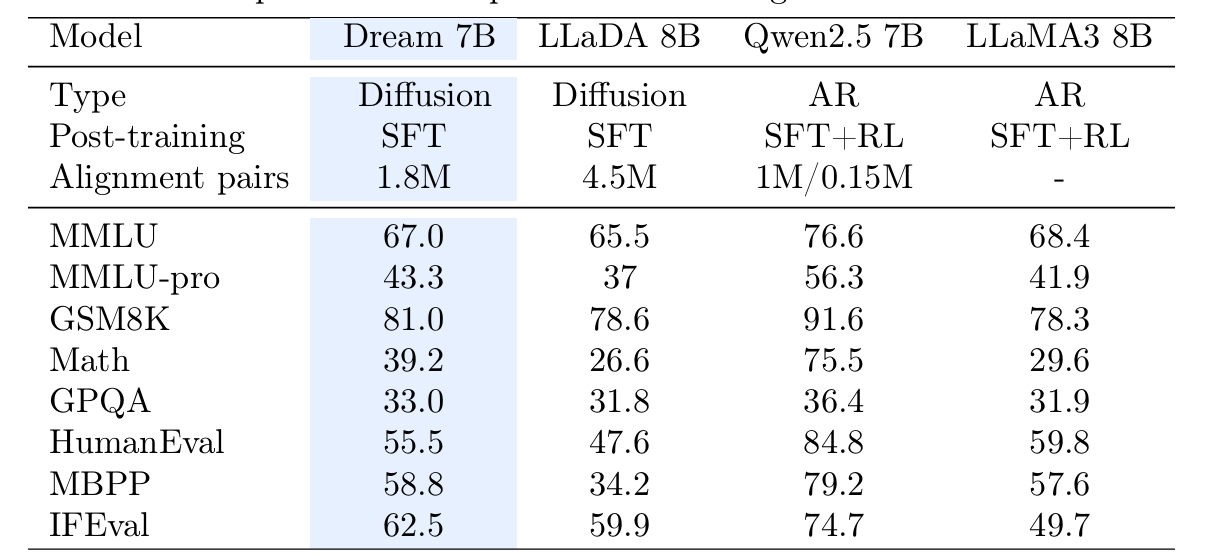
- 论文中没做分析
- 这里和LLaDA一样,SFT之后效果落后,甚至出现了性能下降
扩散大语言模型在遵循指令任务中具备与基于自回归的大语言模型相匹敌的潜力,为未来高级扩散大语言模型后训练方案奠定了基础
AR Initialization的贡献
- 验证:AR LLM初始化是有效的
实验设计:
- LLaMA3.2-1B参数初始化的Dream-1B和从头训练的Dream1B
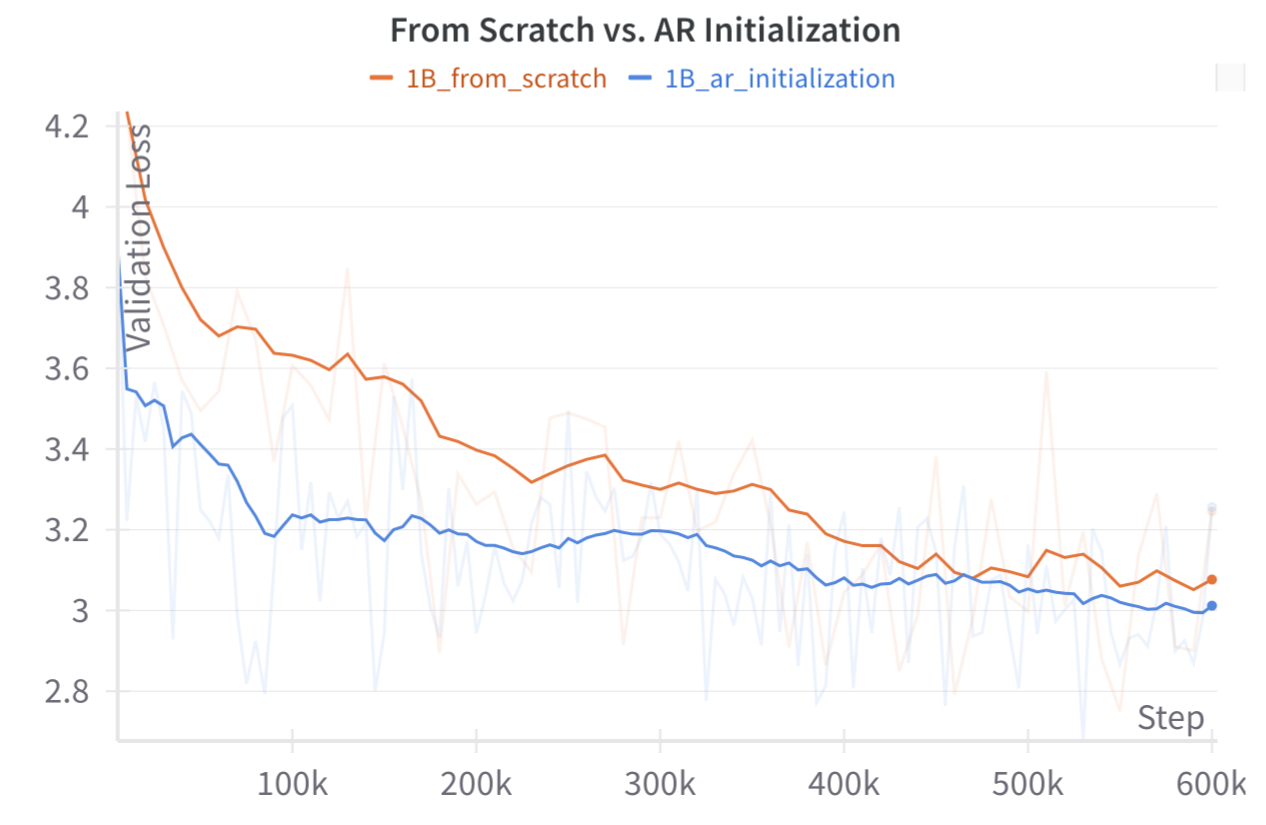
- Loss始终更低,证明了初始化是有效的
同时在这个实验中,论文说明了学习率的影响非常大:
- 大的学习率:破坏AR LLM的有益特性
- 小的学习率:阻碍学习扩散的过程
(但似乎没写上下文自适应噪声调度机制的消融实验)
Planning Ability
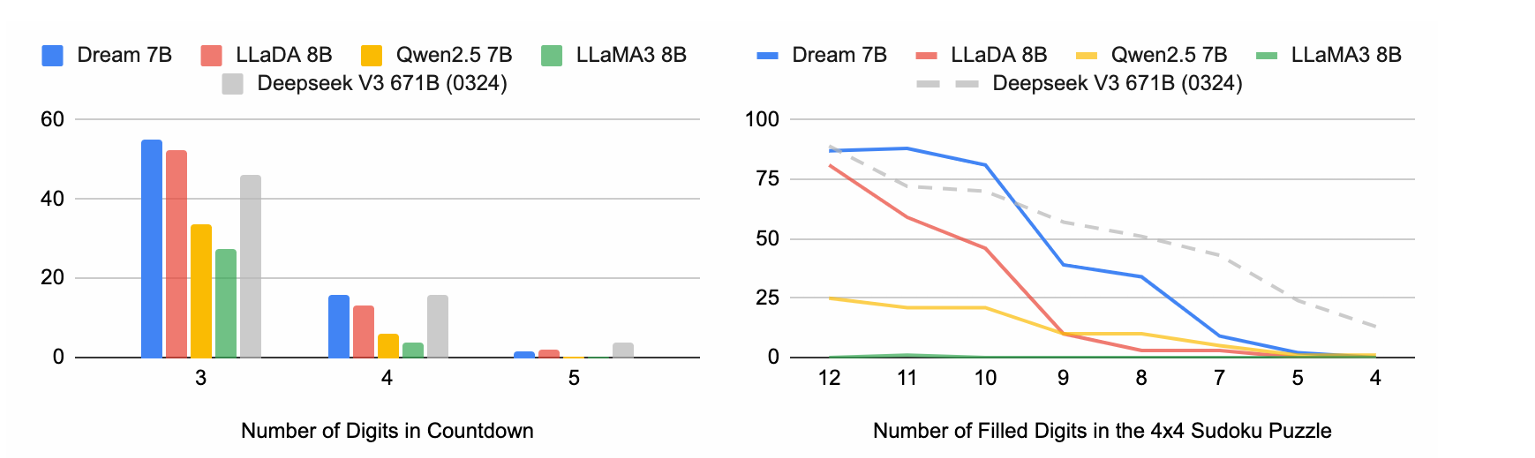
- Dream 模型在两项任务中始终优于其他同等规模的基线模型
- 扩散语言模型在解决涉及多重约束或特定目标优化的问题时具有天然优势(?)
Trade-off
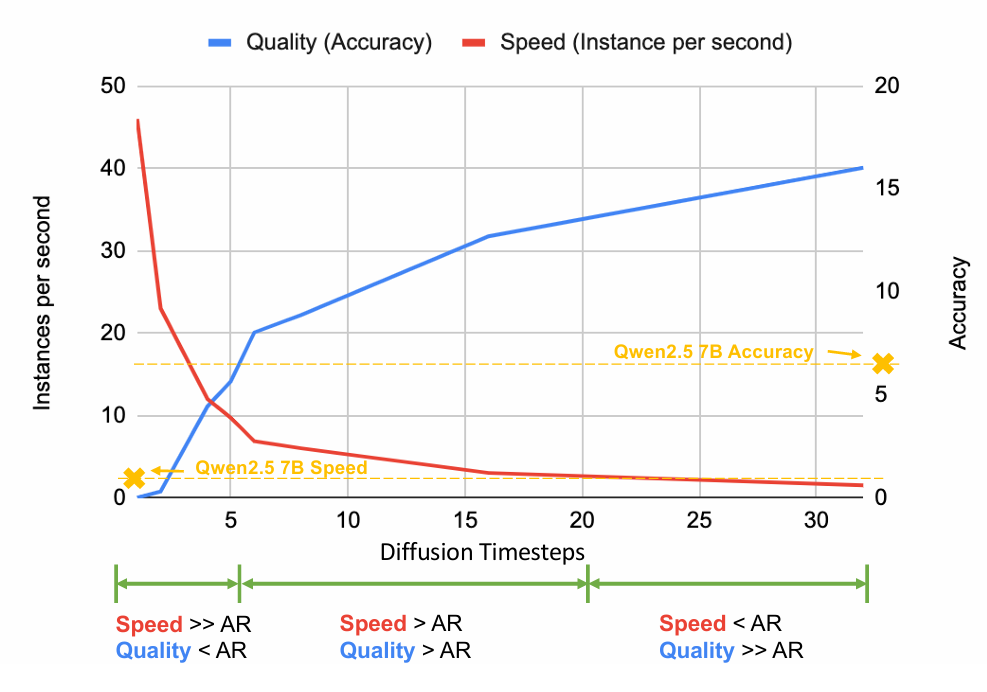
Diffusion language models provide a unique advantage through their adjustable inference process
- 基于时间步长的方法为推理时缩放引入了新的维度,可与现有技术协同工作,例如 OpenAI o1和DeepSeek R1等大型语言模型中使用的思维链推理
- 这种可调节的计算质量权衡代表了扩散模型区别于传统自回归模型的关键优势。
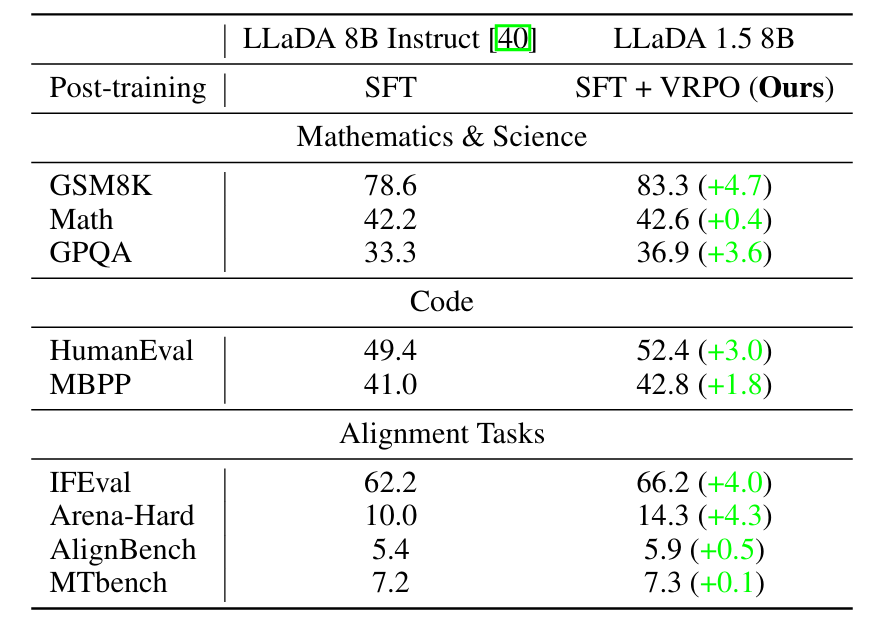
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
2505.19223 LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
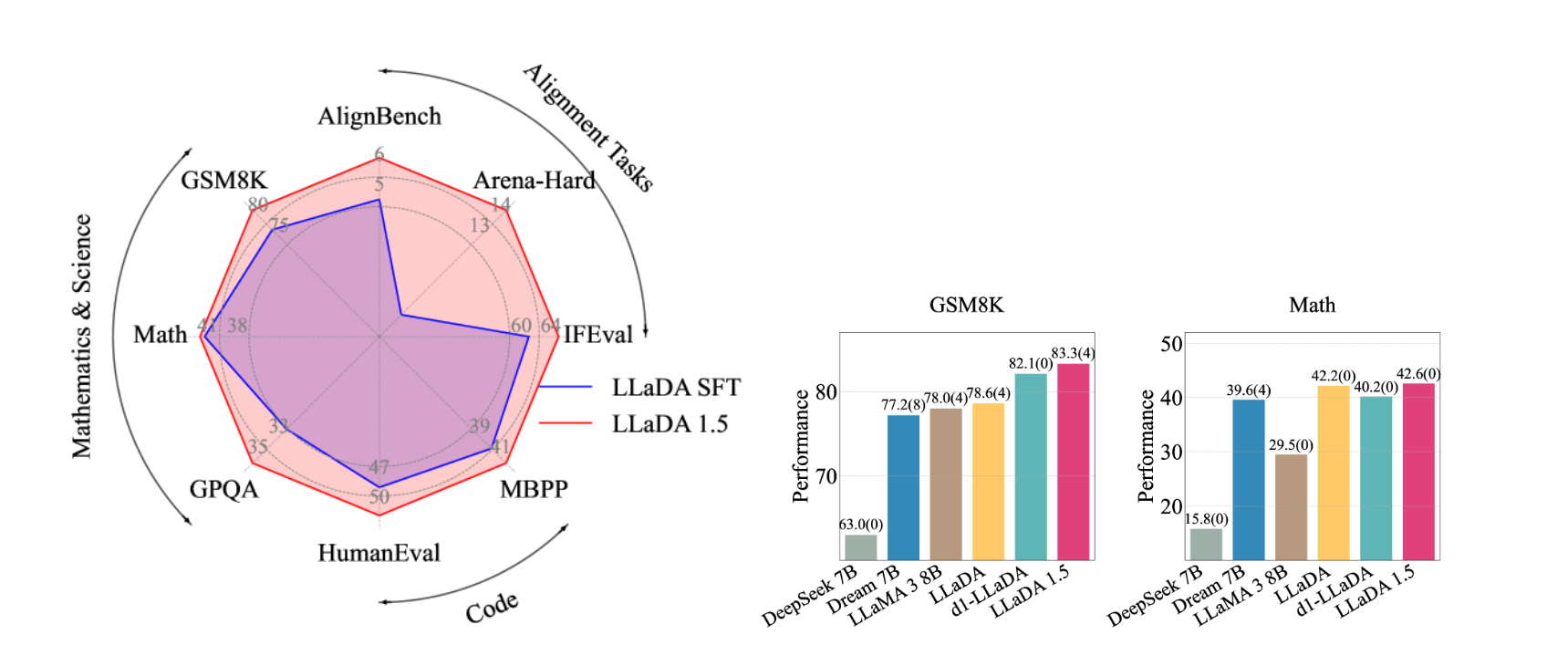
看不懂
大概就是通过VRPO这个方法,基于LLaDA的工作,对LLaDA-instruct进行RL
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
2506.14429 LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
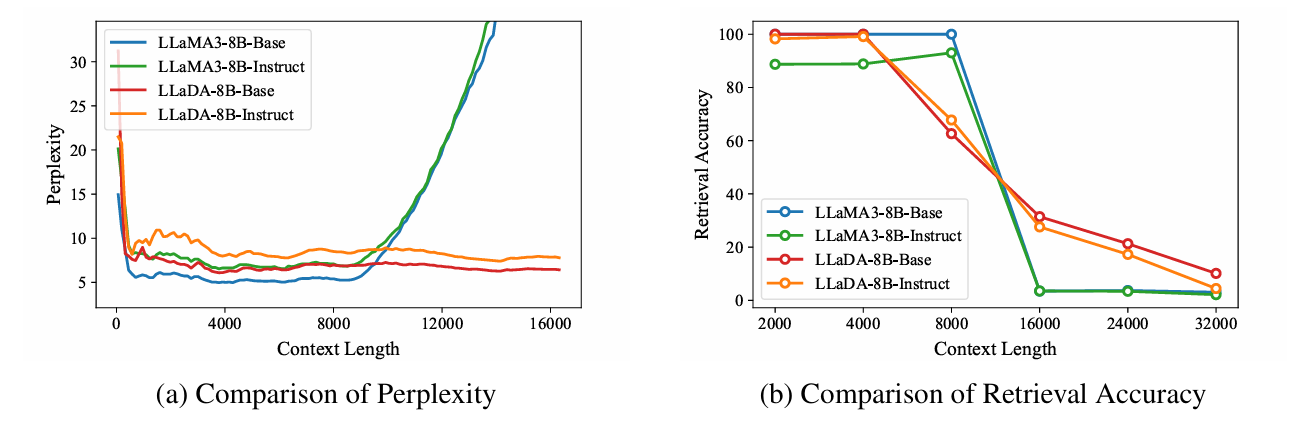
-
核心问题:扩散型LLMs在长文本处理领域的研究空白
- 为什么扩散LLM在直接长度外推时保持稳定的困惑度并呈现局部感知特性
- 针对自回归 LLM 建立的长度扩展技术能否迁移至扩散架构
- 自回归基线相比,扩散 LLM 在长上下文基准测试中表现如何?会显现哪些独特能力或局限性?
-
贡献:
- 揭示了其在上下文外推过程中保持稳定困惑度和局部感知的独特特性,并通过RoPE机制进行了解释
- 基于 NTK 的 RoPE 外推法与缩放定律可无缝迁移至扩散 LLMs,实现 6 倍上下文扩展
- benchmark表明:扩散 LLMs 在检索任务中与自回归模型表现相当,在聚合任务中稍显不足,但在问答任务中表现卓越
Long-Context Phenomenology of Diffusion LLMs
大海捞针测试(Needle-In-A-Haystack, NIAH)
在一个超长的上下文(haystack,干草堆)里,研究者会插入一小段关键信息(needle,针)
模型的任务是:在生成或问答过程中,能否准确地“找到”并使用这段信息。
这类测试会改变针的位置(例如放在靠前、中间或靠后部分)以及上下文的总长度,用来观察模型在不同深度和不同长度下的表现。
-
实验目的:揭示扩散 LLM 在长上下文中出现的局部感知 (local perception)
-
实验设计:
-
输入:在不同长度(最多32k)的长上下文中插入一个needle
-
输出:限定模型输出最多32个token
-
实验对象
- DLM:block size = 32,采样步数 = 32
- LLM:默认
-
评估指标
- 找到Needle的成功率
- 模型在不同深度(前文、中间、后文)找到Needle的能力
-
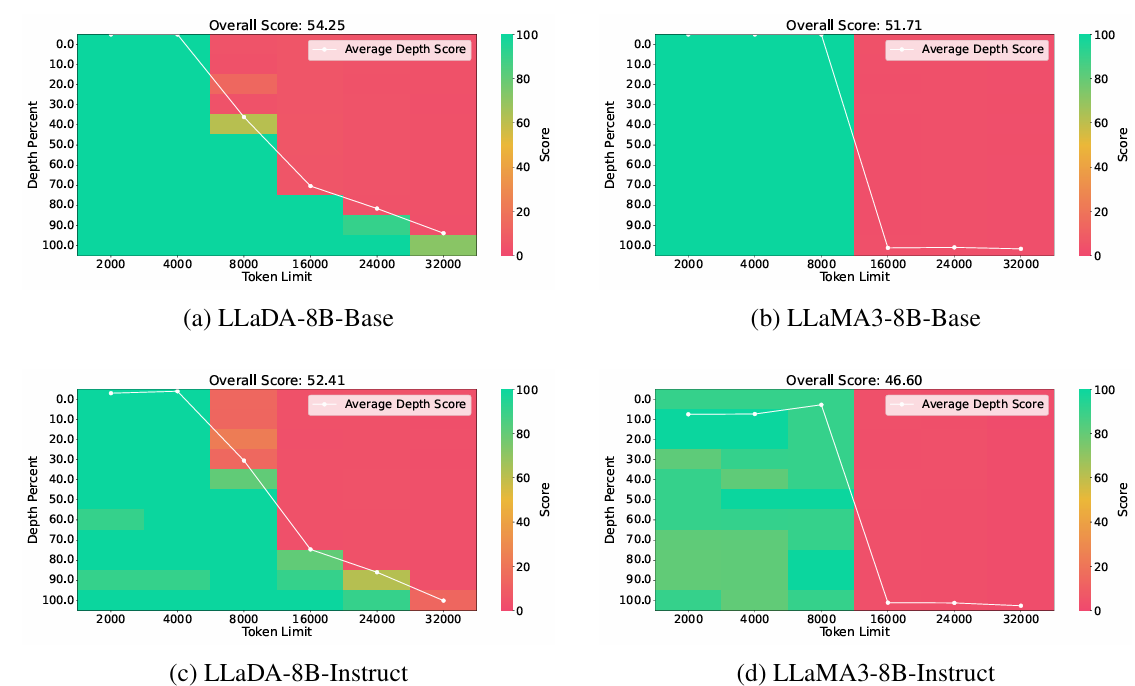
附录中补充了其他DLM模型的实验
- AR LLM在8K内的上下文表现完美,超过8K长度无法完成任何任务
- DLM出现了类似**滑动窗口(窗口长度为4k)**的表现
DLM受采样步数影响较大,因此定量补充了实验:
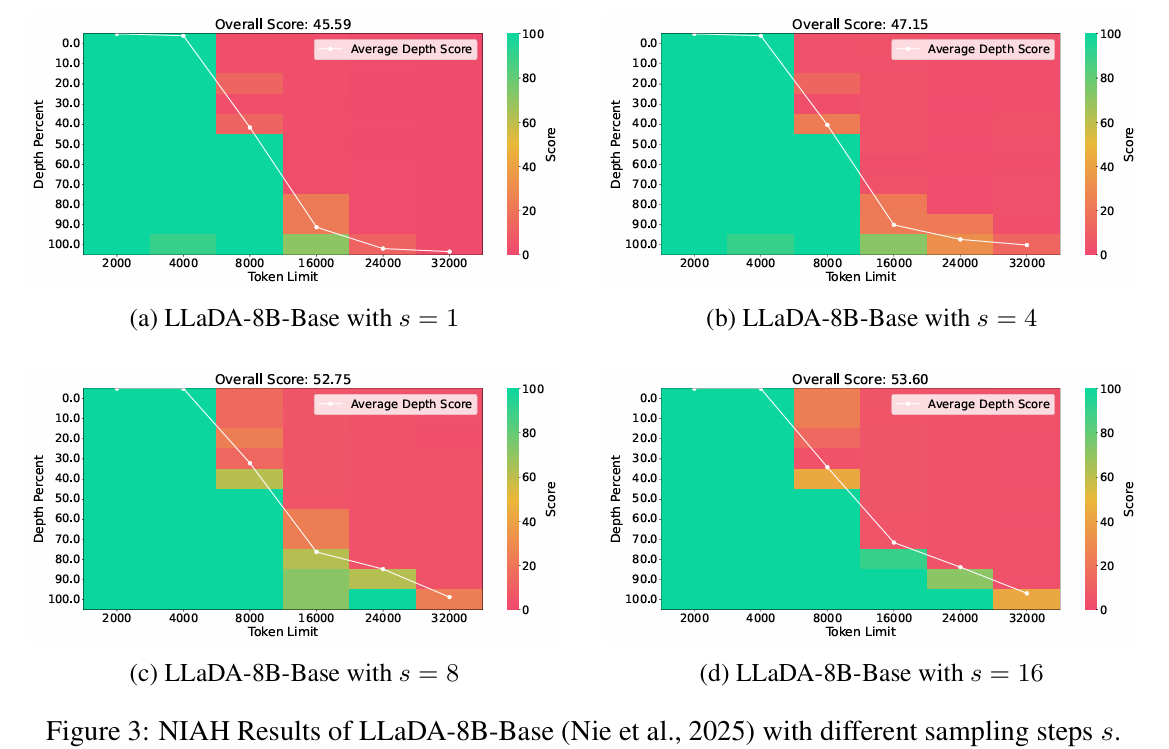
- 表明扩散 LLMs 的长上下文性能虽受采样步数影响,但仍受限于模型支持的最大上下文长度
机制分析
- 自回归只能看见后续的:$[0, T_{train} - 1]$(LLaMA的$T_{train} = 8192$)
- DLM是双向注意力:$[1-T_{train},T_{train}-1]$(LLaDA的$T_{train}=4096$)
- 对于单个token,可以同时出现在左边的上下文窗口,也可以出现在右边的上下文窗口
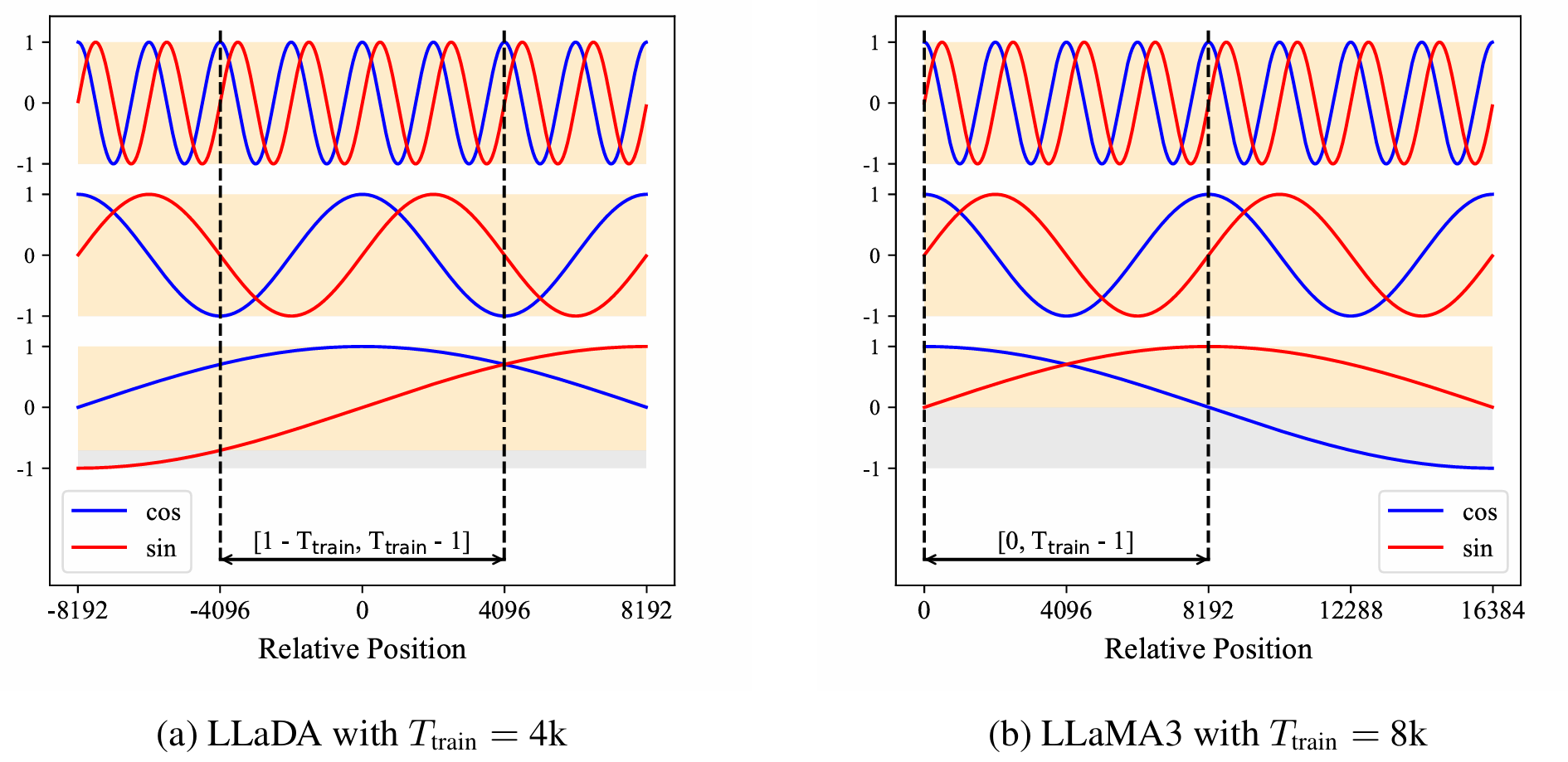
留坑:RoPE
- LLaMA完全丢失了负相对位置的信息,外推能力受限
- LLaDA虽然$T_{train}$比较小,但是能够接受到一个负正窗口
LLaMA:只学习了从头往后一个个token读取的能力
它可以知道,第2个token是第1个token的后一个……第1000个token是第999个token的后一个……
(像翻书一样可以一页一页翻)
但是一旦碰到第10000页,它推理不出这是9999页过来的(超出上下文,没有学习过这种关系)
LLaDA:双向上下文
可以推断出9999是10000的前一页
论文补充了t-SNE可视化实验
观察了两个模型最后的Q和K states
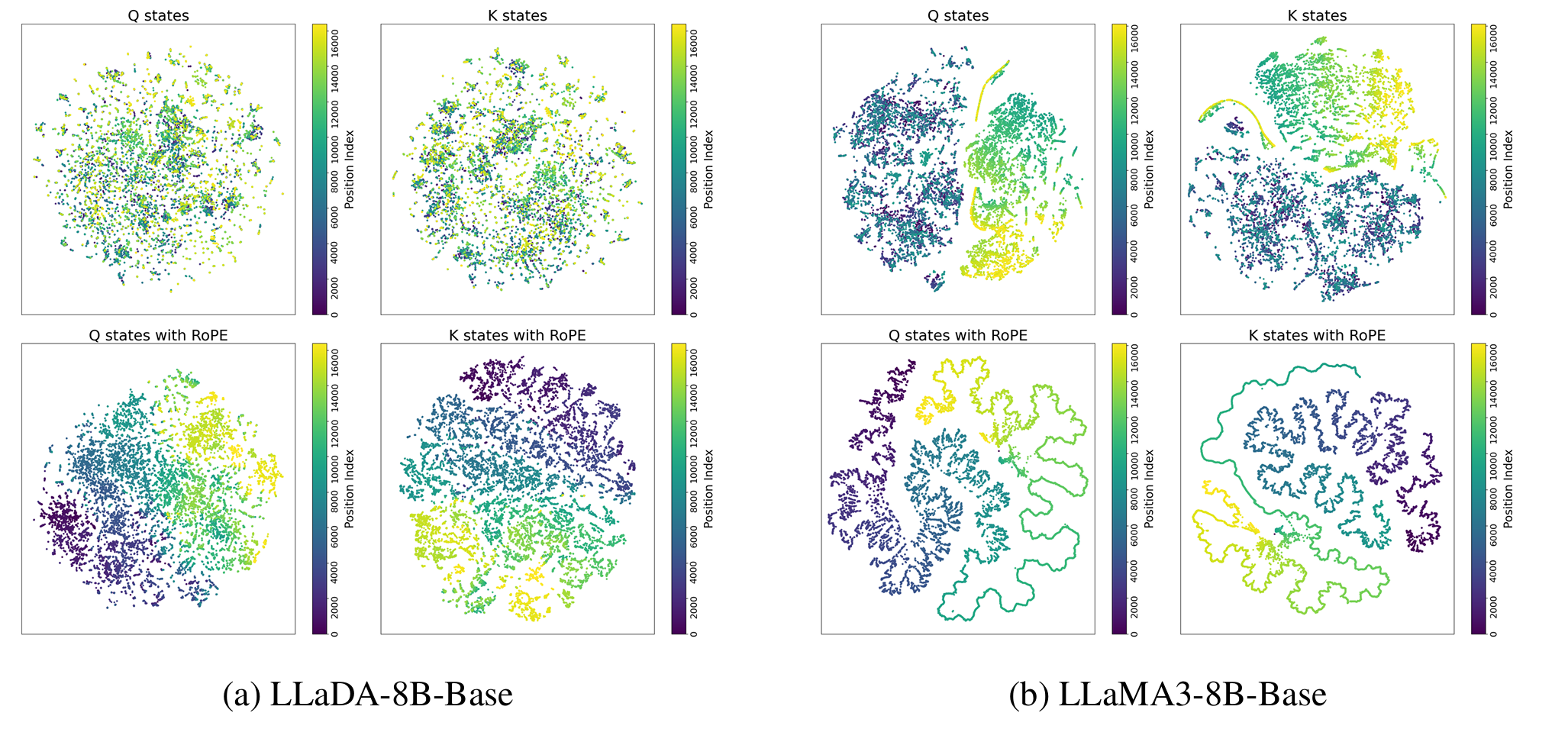
- LLaDA随着上下文长度增加,仍然保持形状
- LLaMA出现了明显的聚类分离,表示内部出现了
distribution shift
Context Extension
将 NTK-based RoPE extrapolation(一种在自回归 LLM 中已验证的旋转位置嵌入扩展方法)迁移到扩散式 LLM
缩放旋转基数 β0,让正弦/余弦函数周期变长,相当于“拉伸坐标轴”,从而容纳更长的上下文
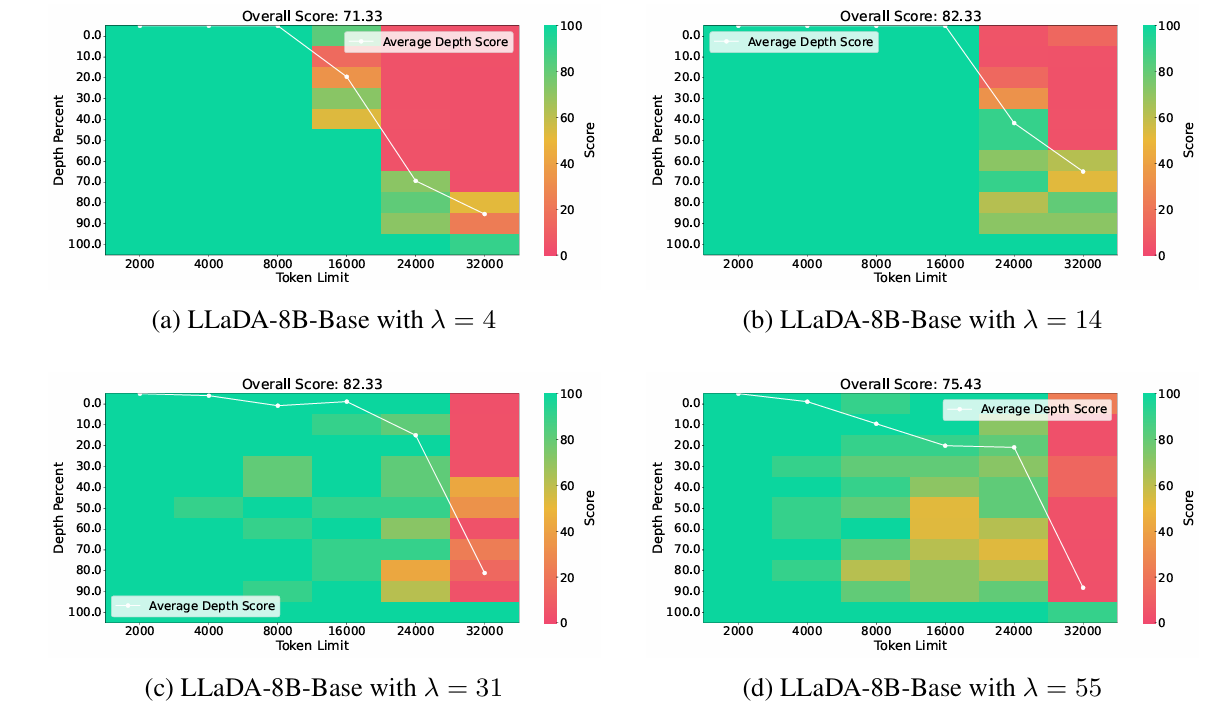
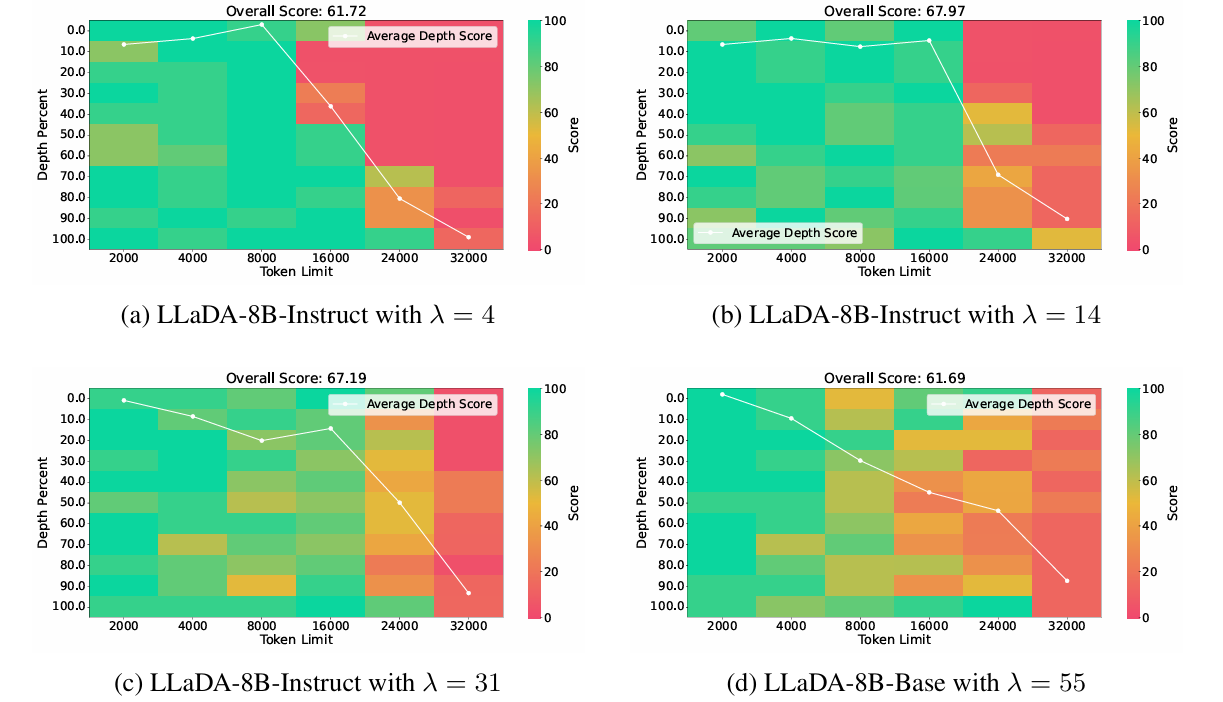
-
小幅扩展有效: 8k 或 16k,几乎在所有深度下都保持接近 100% 的检索准确率。
-
中等扩展出现性能下降:24k ,出现lost-in-the-middle现象
- 自回归模型中同样有的现象
-
大规模扩展失败:模型无法再有效外推,说明方法的实际上限已到达。
附录中对同类的DLM做了相同的实验
Experiment
SD、MD、Sum 和 Syn 分别代表单文档问答、多文档问答、摘要和合成任务
Avg 是所有子任务按评估数据数量加权的平均得分
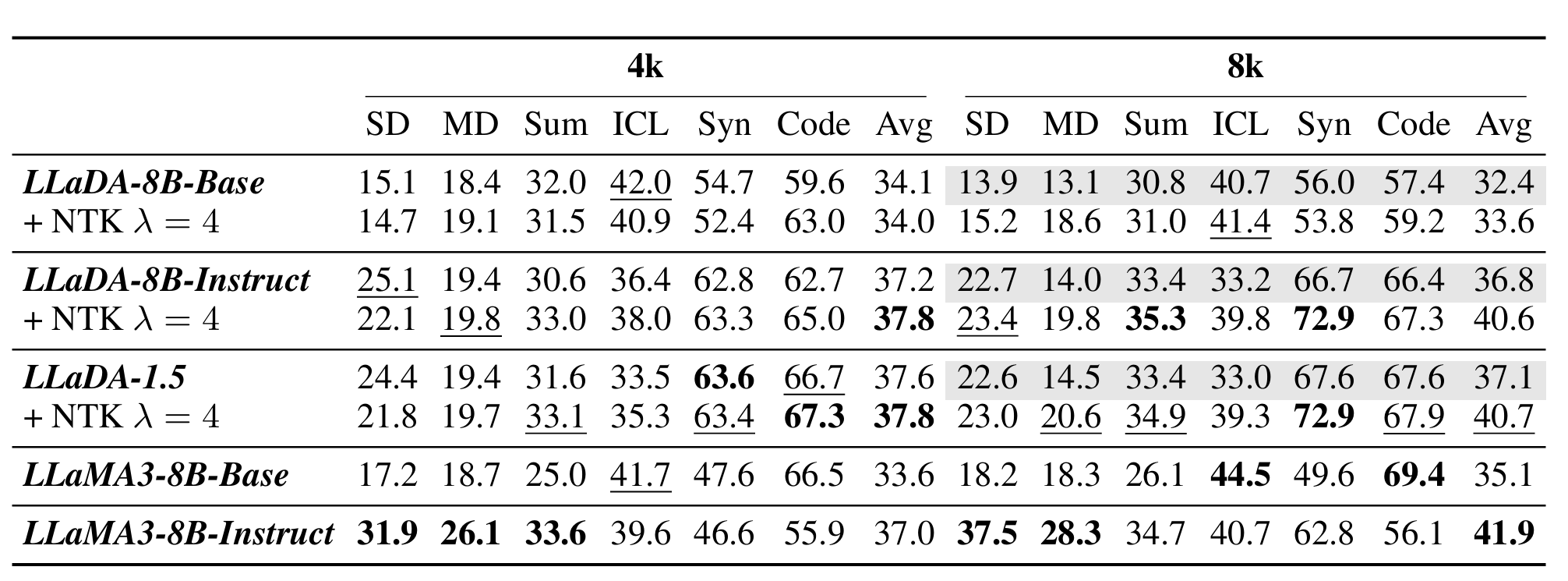
- 平均得分媲美AR LLM
检索(NIAH)/聚合(AGG)/问答(QA)
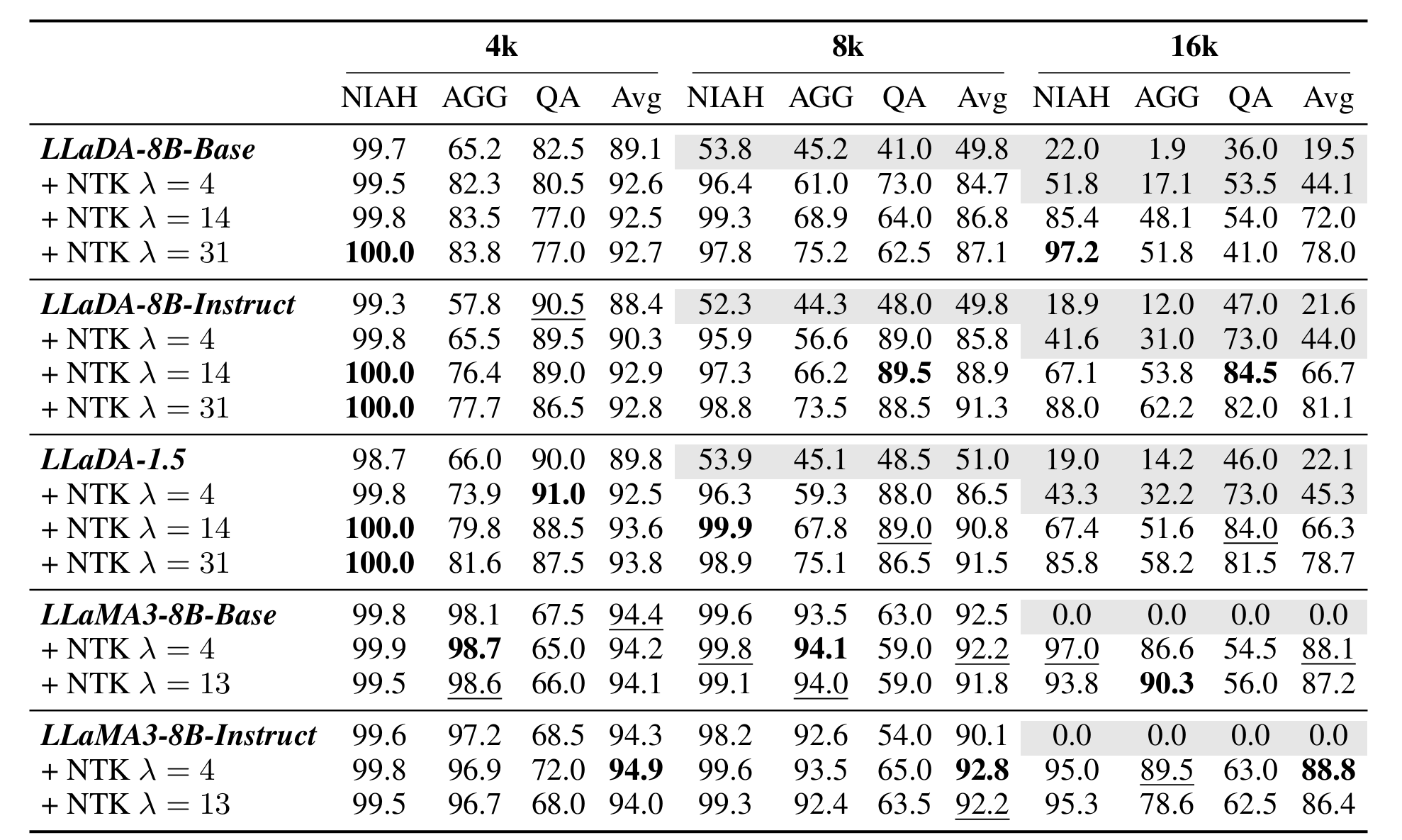
- 检索任务:相当
- 聚合任务:不如AR LLM
- 问答任务:超过AR LLM
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
-
问题:完全基于扩散机制的多模态大语言模型能否达到与AR LLM相匹敌的性能?
-
论文贡献
- 首个完全基于扩散模型的多模态大语言模型
- 在多个基准测试中展现出卓越的可扩展性
- 在混合型及纯扩散式多模态大语言模型中均SOTA
Visual Instruction Tuning
-
Vison Tower(CLIP或SigLIP):图像转视觉表征
-
MLP connector:嵌入LLM词空间
-
Language Tower:LLM
主流的多模态大模型架构之一,只需要相对较少的数据(less than 100w 图文数据对)
本文主要研究如何在DLM中进行Visual Instruction Tuning
Method
- Language Tower:LLaDA 8B(与LLaMA3-8B相当的语言模型)
- Vison Tower:SigLIP
- MLP Connector:a two-layer MLP
Training
训练阶段引入了含有多轮对话的数据
为了简化描述,文章以2轮对话的数据进行说明,定义符号:
- $\mathcal{v}$:Vison Tower和MLP Connector生成的视觉表征向量
- $[M]$:掩码标记
- 数据:$(\mathcal{v}, p_0^1,r_0^1,p_0^2,r_0^2)$
- $p_0^1 = [ p_0^{1,i}]$:首轮提示文本
- $p_0^2 = [ p_0^{2,i}]$ :次轮提示文本
对于一个二轮对话,训练目标定义为:
$$ L(\theta) = -\mathbb{E}_{\mathcal{v},t,p_0^1,r_0^1,r_t^1,p_0^2,r_0^2,r_t^2}\left[\frac{1}{t}\sum_{i=1}^{L_{p_1}}\sum_{j=1}^{L_{p_2}}1\left[r_t^{1,i}=M\wedge r_t^{2,j}=M\right] \cdot \log p_\theta(r_0^{1,i},r_0^{2,j}\mid \mathcal{v}, p_0^1,r_0^1,p_0^2,r_0^2 ) \right] $$在多轮对话场景下,不同轮次的响应是强相关的
- 用户的问题可能在第 1 轮,答案在第 2 轮
- 推理链条往往横跨多个回合,不能只看单独的 token
模型必须在预测某个 token 时,同时考虑另一轮对话中的掩码 token
这样就把 跨轮次的依赖关系 学进去,而不是每轮单独学
联合约束迫使模型去捕捉 对话轮次之间的因果逻辑
理论上这个式子在先前工作中已经被证明为整个任务的负对数似然上界
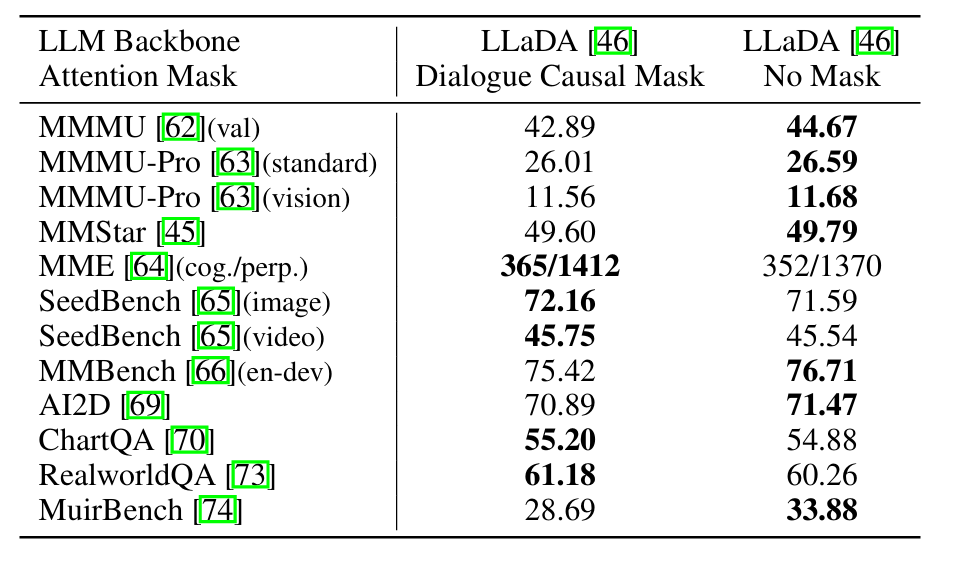
- 在多轮对话中似乎可以采用causal mask,阻止早期对话轮次访问了后期的对话轮次
- 后文消融实验证明双向注意力的效果更好(实现对整体对话语境的全面理解)
该机制在近期视频扩散模型中已证实可有效提升生成视频的时间连贯性
本身训练的流程和LLaDA的SFT流程比较相似,加噪只会在Response中,且同时对多轮对话中的Response进行加噪
一次性让模型恢复所有对话中的MASK
Training Strategies
整个训练过程参考了LLaVA的训练策略
建立语言和视觉对齐关系并培养视觉指令跟随能力
训练目标函数与上文相同
- 阶段一:语言-图像对齐
- 目的:图像与语言的分布不一致,如果直接做指令调优,模型学习跨模态语义很困难
- 方法:将视觉表征与 LLaDA 的词向量进行对齐
- 冻结Vison Tower和Language Tower(这两个本身进行过预训练),只训练MLP Connector
- 数据集:LLaVA-Pretrain
- 阶段二:视觉指令调优Visual Instruction Tuning
- 目的:(单图像训练)建立基本的图像理解能力,(多图像训练)扩展到时序和跨图像推理
- 方法:(两个阶段)解冻所有层
- 单图像训练Single image:在 1,000 万单图像样本上训练,增强对单张图像的理解与响应能力。
- 统一视觉训练阶段one vision:在 约 200 万多模态样本(包括单图、多图和视频)上训练,使模型具备处理复杂场景的能力
- 数据集:MAmmoTH-VL 数据集
- 阶段三:多模态推理增强 Multimodal Reasoning Enhancement
- 目的:增强模型处理复杂任务的多模态推理能力,加入reasoning data提升数学、跨图像和逻辑推理任务的表现
- 方法
- 推理训练:使用来自 VisualWebInstruct聚焦推理的多模态数据对 LLaDA-V 进行训练(90 万个问答对,详尽的推理链和最终答案)
- 平衡训练:参考qwen系列,融合VisualWebInstruct(其中50%添加
\think)和MAmmoTH-VL(one vison部分,全部添加\no_think,鼓励直接回答)
Inference
推理时根据已有的对话记录,对当前的prompt进行单轮的response生成
重掩码策略采用low-confidence strategy
Experiment
可扩展性
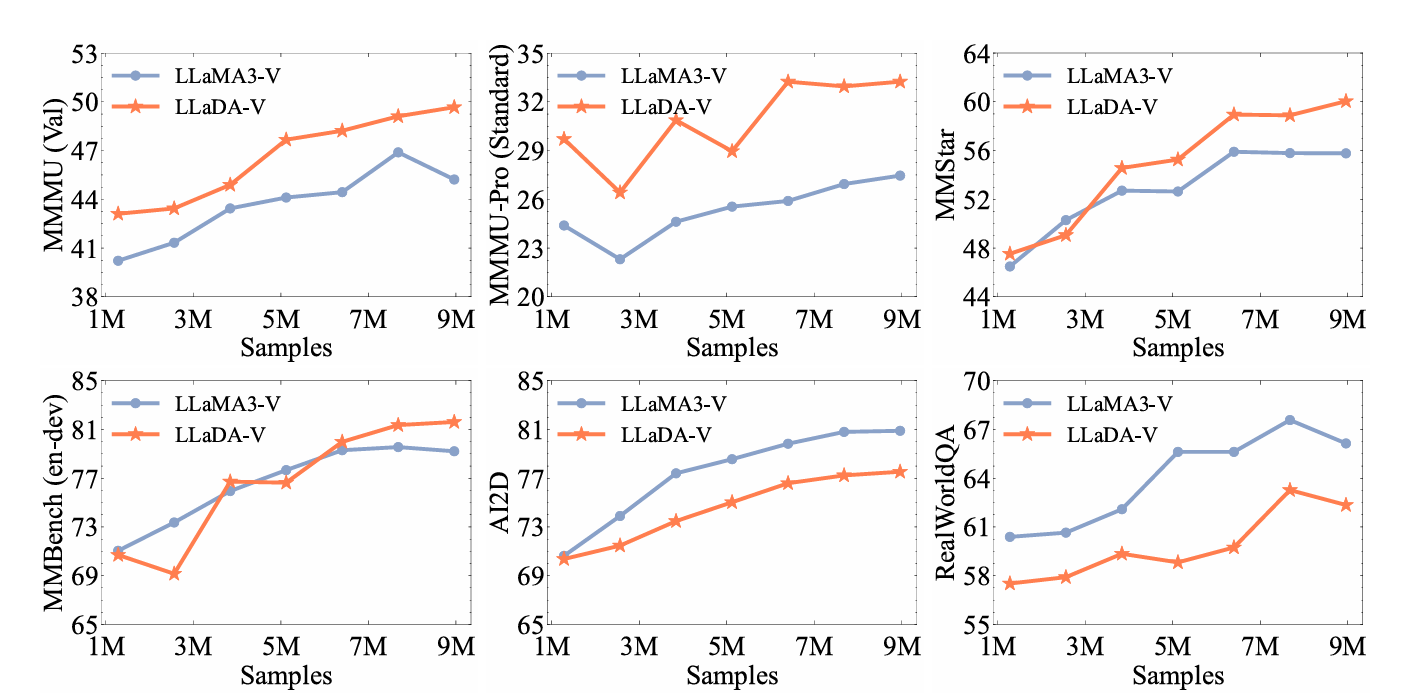
- LLaDA-V 随着训练数据增加性能持续提升
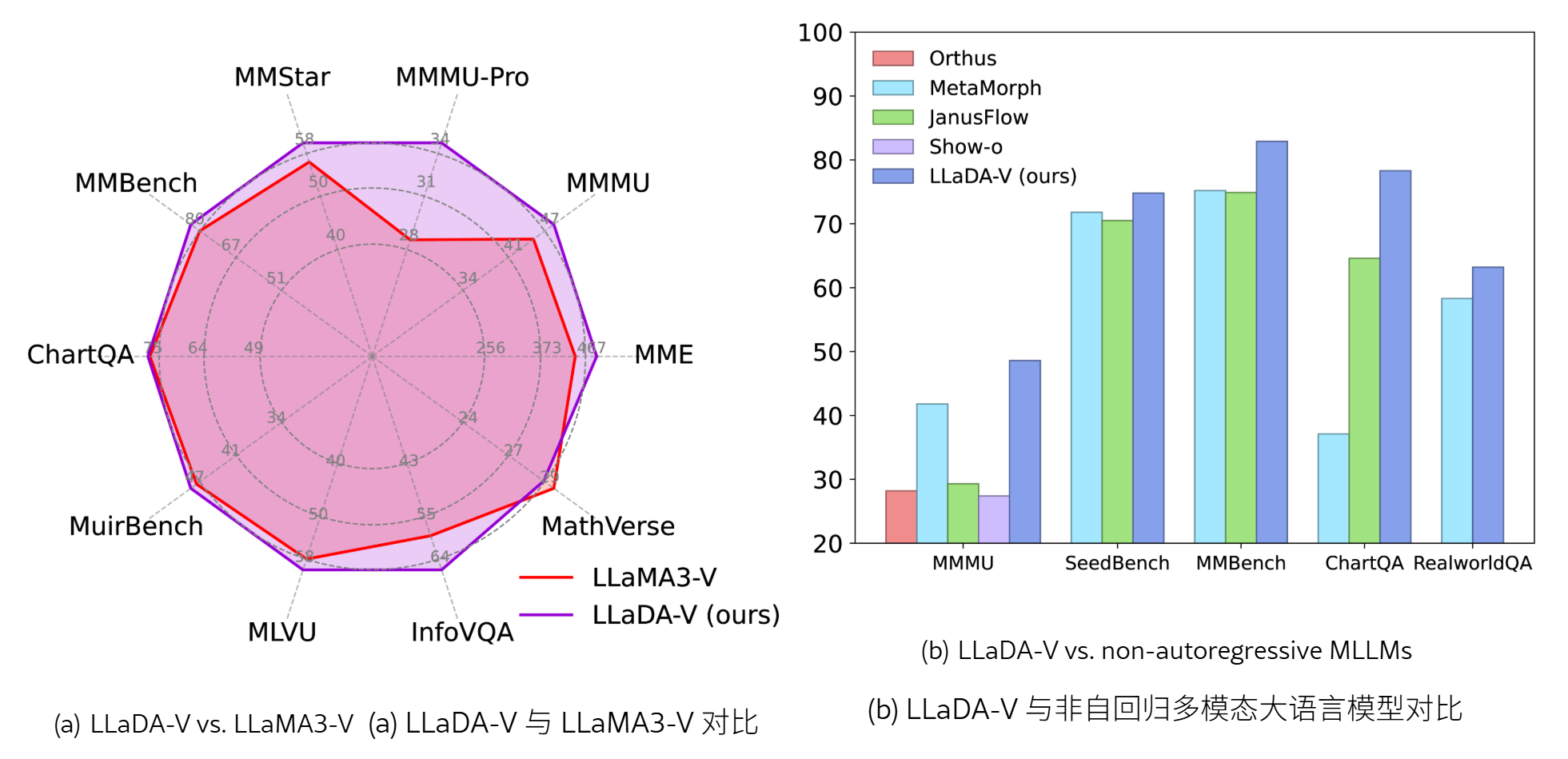
- 在 多学科与数学推理任务 上,LLaDA-V 扩展性明显优于 LLaMA3-V
- 但在 图表/文档理解 和 真实场景理解 任务上,LLaMA3-V 表现更优
Benchmark
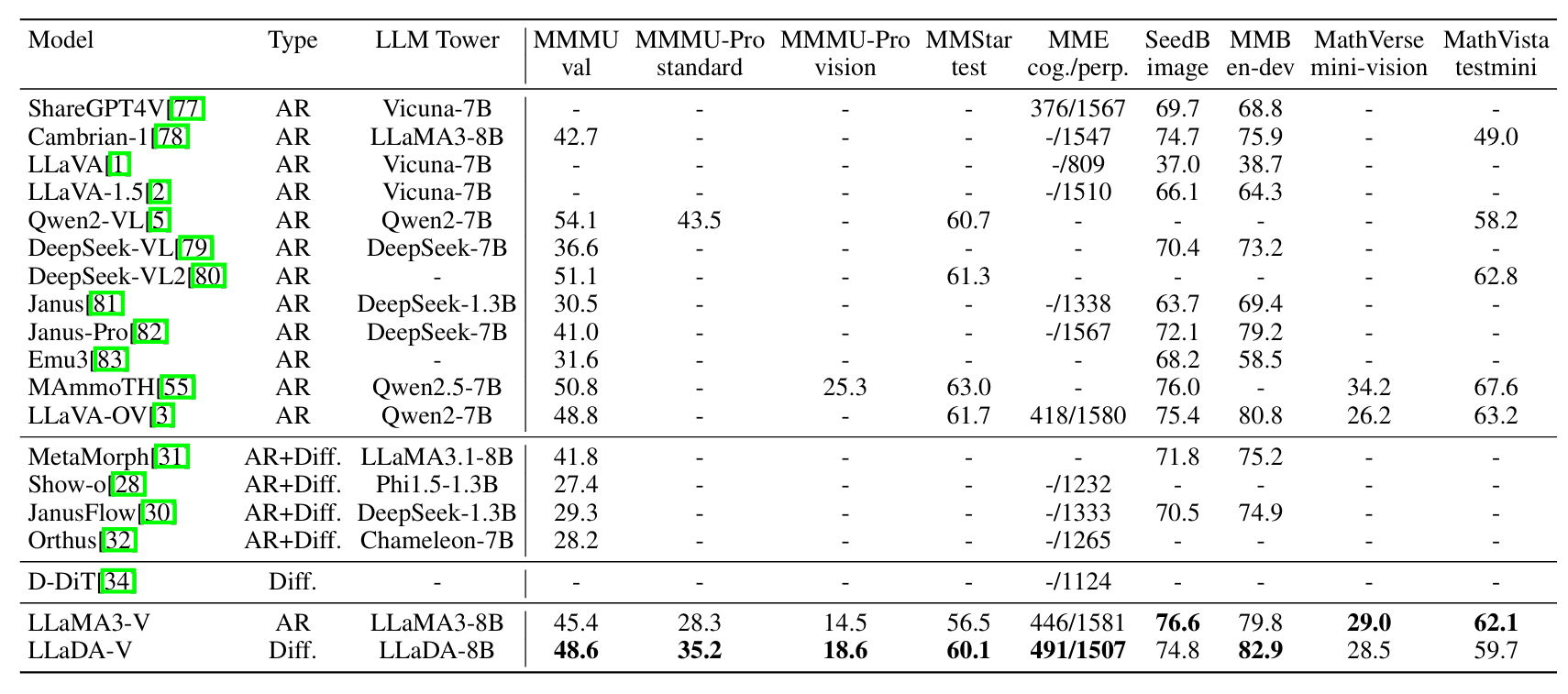
- 对于已有的混合或扩散模型,LLaDA-V是SOTA
- 对比LLaMA3-V:6 个任务上超越
- 对比Qwen2-VL:整体仍落后
- 图表/文档理解和 RealWorldQA 上表现稍差
消融实验
- 对比了Causal Mask和无Mask(多轮对话)
- 12个benchmark中7个更优
Conclusion
- 图像接入SigLIP的方式比较简单,会丢失分辨率和信息,造成图表问题表现差
LLaDA-MedV: Exploring Large Language Diffusion Models for Biomedical Image Understanding
2508.01617 LLaDA-MedV: Exploring Large Language Diffusion Models for Biomedical Image Understanding
没怎么看,大概是把LLaDA-V的工作调整到了垂类领域
一些比较有趣的实验分析:
- DLM在一些垂类领域非常合适,可以显式地控制一个大概的生成长度
- 模型可能出现重复 token(如 “the the the …”)的问题,尤其在采样步数较少或长度设定较大时
- 直接使用LLaDA-V的参数做微调的性能反而更差,需要从LLaDA-instruct出发,重新走3个步骤
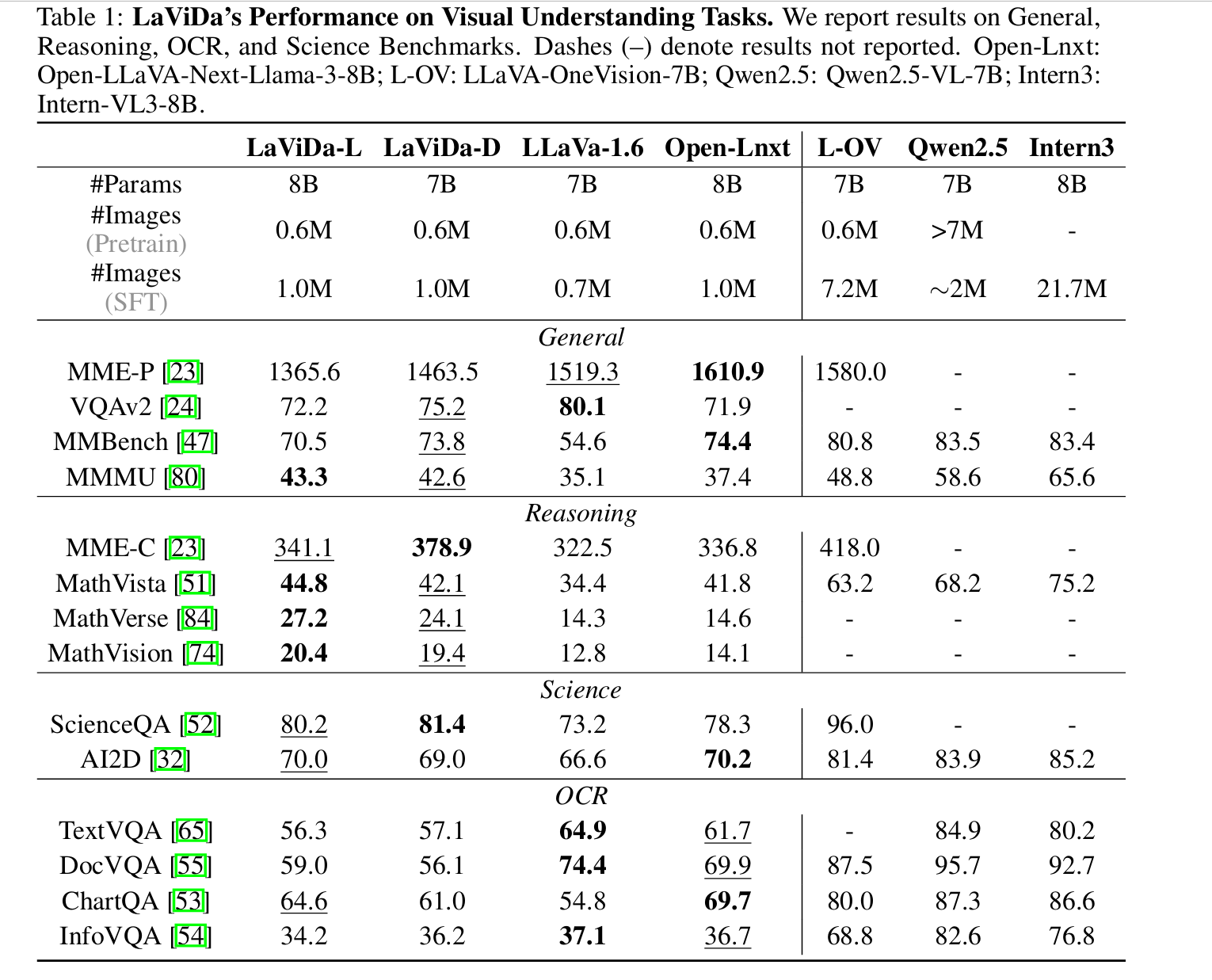
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
https://arxiv.org/abs/2505.16839
问题:
-
AR LLM对强双向上下文要求的任务(文本填充、从图像中提取信息填充到json格式)很弱
- 视觉语言场景中对输出模式的要求特别严格
-
标准扩散模型训练的数据效率低下,未被遮盖的token不参与损失函数计算,容易遗失关键语义信息(关键词)
-
现有的推理方式缺少了KV cache的支持(双向上下文固有的缺陷)
- 短文本环境中是可容忍的
- 对于VLM任务无法接受,常常伴有数百个visual token
-
固定比例的
unmask在迭代次数较少时效果非常差
贡献:
-
第一个DLM视觉语言模型
-
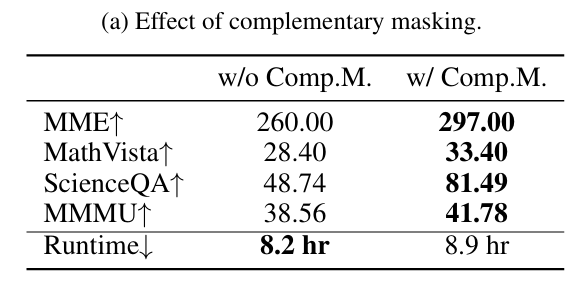
一种互补的mask方案,确保每个token都能参与到学习过程中,提高数据效率
-
Prefix-DLM decoding:缓存多模态的提示词与图像输入,从而加速推理过程
-
受文生图技术的启发,采用了时间步偏移策略,自适应调整每次迭代的解码数量
Method
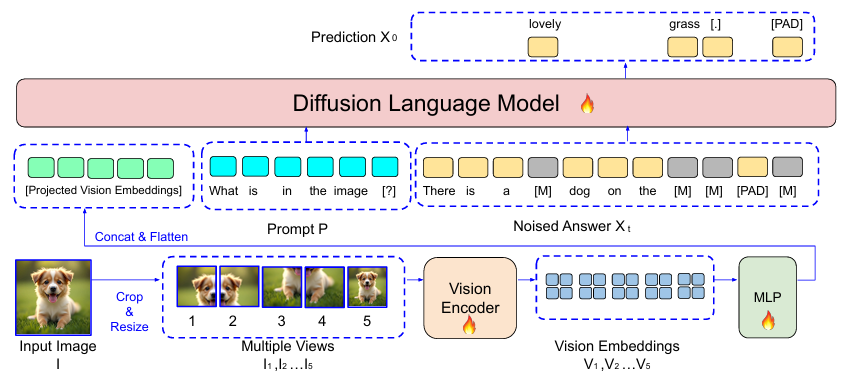
-
Vision Encoder和DLM通过MLP进行连接
-
模型输入:图像$I$和文本$P$
Vision Encoder
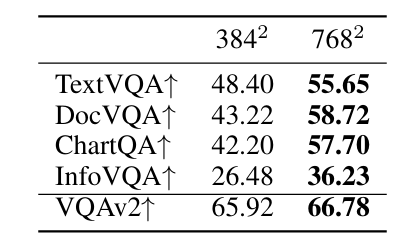
- $I \to_{resize} 768\times 768$
- 切分成四个不重叠的部分($I_{1:4} = (384,384)$);直接resize原图为$(384,384)$,得到$I_5$
- 每一个子图被独立地通过Vision Encoder(SigLIP-400M )进行编码
- $I_i \to V_i, \text{size} = 27 \times 27$,五个子图总共产生了3645个embeddings
- $2\times 2$平均池化(缩短序列,提升训练效率):$14\times 14$,总共980个embeddings
- 经过MLP构成的Projection Network,Flatten到1D
这里是输出5个一维向量,还是拼在一起的1个一维向量?
暂时没去研究
DLM
DLM的输入:
- 视觉嵌入向量
- 文本提示词$P$
- 带有掩码的$X_t$
输出:
- 概率分布,用于获取$X_0$
论文采用LLaDA和Dream作为DLM
Complementary Mask
文本中信息量非常密集,一般就是几个词
对于之前的加噪方法,不一定能恰好遮蔽需要的词
例如The answer is dog.,加噪为:The [MASK] [Mask] dog.
事实上我们只需要引入它的互补形式:[MASK] answer is [MASK]
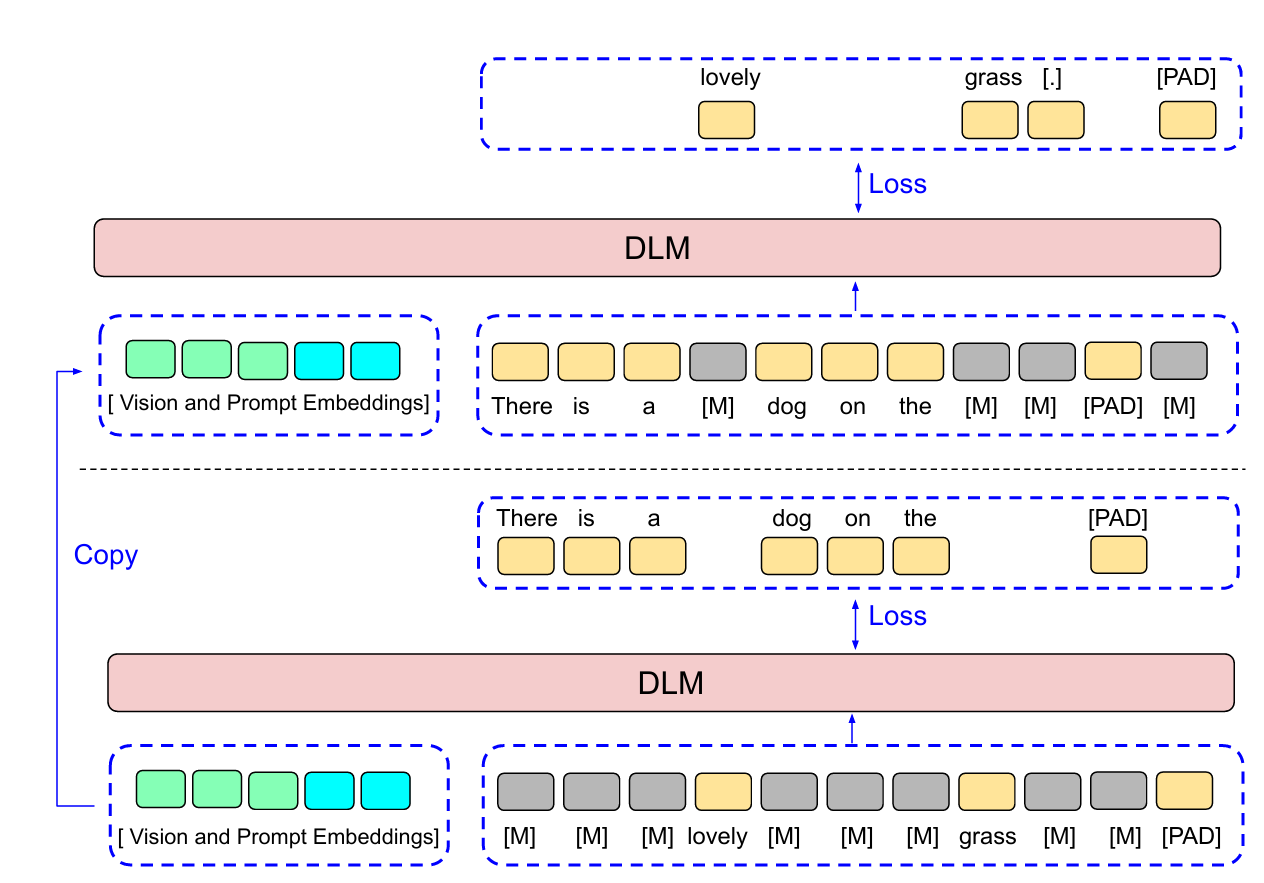
同时,这份数据会直接copy视觉以及提示词部分的嵌入
因此对实际训练开销的影响较小
Prefix-DLM
定义序列长度为$L$,推理的迭代次数$K$,我们有NFE(fraction of the number of functional evaluations):
$$ \text{NFE} = \frac{K}{L} $$- NFE=100%时,每次迭代生成一个Token
- NFE=50%时,每次迭代生成2个Token
但实际上由于毫无推理优化,DLM的速度比自回归慢
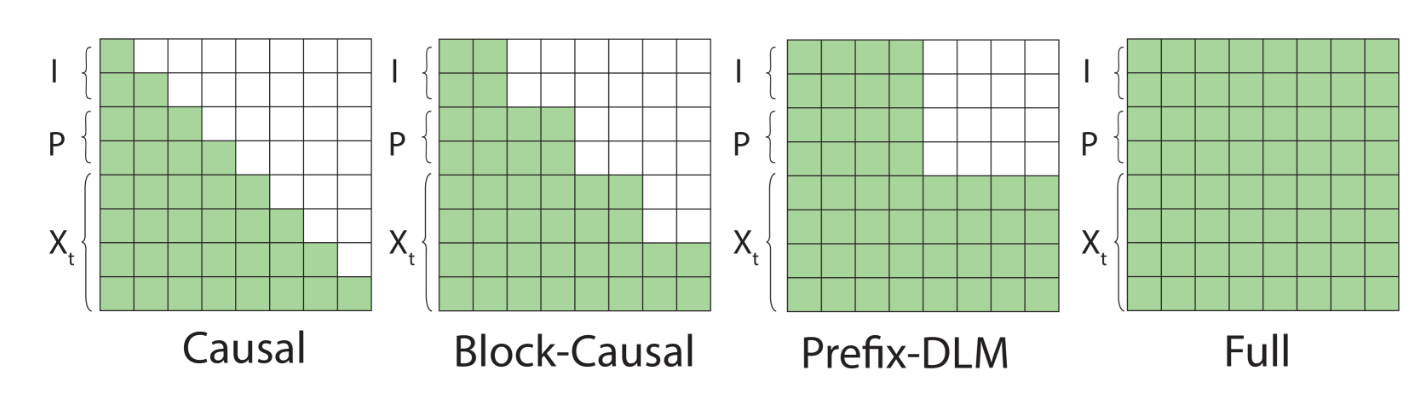
- Causal Mask:可以不断复用之前的token的kv矩阵(之前的token没有变化,且之前的token对未来的token不感兴趣)
- Full Mask:每个token都会看前后的内容,因此需要不断重新计算
- Prefix-DLM:I和P部分不会发生变化,遮蔽了对未来answer的token
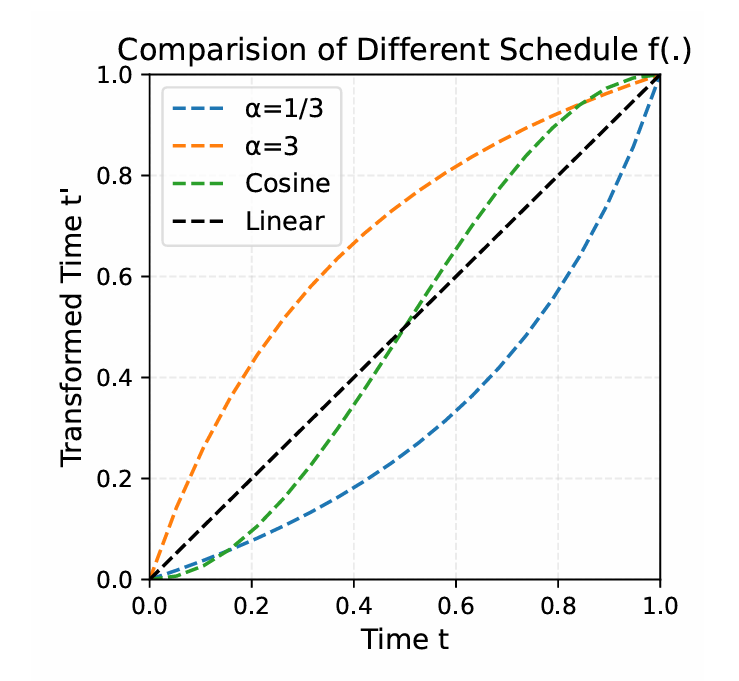
Schedule Shift
喷了一下等步长的解码,提出了非线性的递推:
$$ t'_i = \frac{\alpha t_i}{1+(\alpha -1)t_i} $$设计一个时间重参数化的函数,要求满足:
- $t_0 = 0,t_1 = 1$,仍然保持边界
- 单调递增
- 曲率可控,方便控制早晚阶段的速度
- 简单,防止数值不稳定或梯度爆炸
论文希望早期降噪快,后期降噪慢
希望先快速搭建一个骨架,后面慢慢填充
对这个式子求导:
$$ \frac{dt_i'}{dt_i} = \frac{\alpha}{(1+(\alpha-1)t)^2} $$当$t=0$,导数为$\alpha$,$t=1$,导数为$\frac{1}{\alpha}$
可以通过$\alpha$和1的大小关系,控制是先快后慢,还是先慢后快
Experiments
略过benchmark部分
Reasoning Distillation
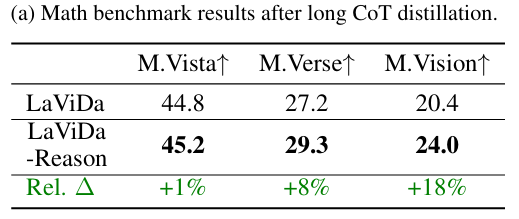
paper通过蒸馏VL-Rethinker-7B模型(19.2K CoT examples)
训练得到LaViDa-Reason
在MathVista、MathVerse和MathVision上均得到提升
Text Infilling
对于实际的文本填充任务,不需要生成所有内容,只需要填写需要填写的
任意时间步长开始生成
例如:
There is a [M][M][M][M] in the image.
这里我们希望是dog或者traffic light,也是就是variable-length completions
因此利用了第二阶段(激活全部参数)的20%数据,进行第三阶段训练,得到LaViDa-FIM
- 文本中插入随机长度的
[S][S]……[S][FIM]序列 - 推理时,在掩码段后面附加
[FIM],得到There is a [M][M][M][M][FIM] in the image. - 模型自然可以生成:
There is a dog[S][S][S][FIM] in the image.There is a traffic light[S][S][FIM] in the image.
约束性诗歌生成:模型根据图像生成一首诗,每行以特定音节开头
强调了结构性约束和上下文一致性,测试双向生成能力
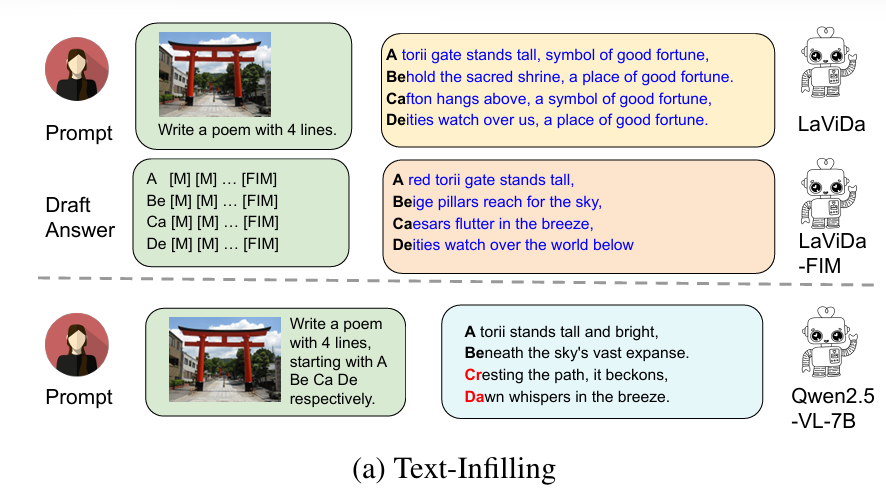
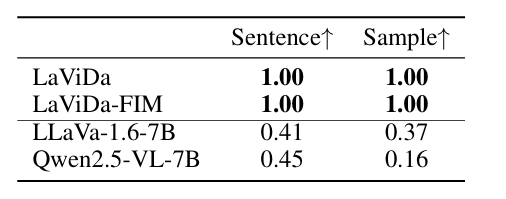
- Sentence:满足行级别的约束的比例
- Sample:满足样本级约束的比例
Speed vs. Quality Trade off
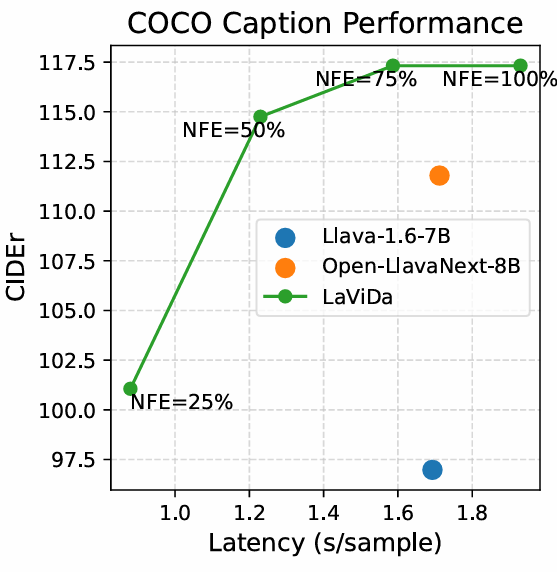
设定长度固定32,通过调整迭代次数K,进行实验
(数据集COCO2017图像描述 500张,生成图像标题)
- NFE=100%,稍慢于AR LLM,但是性能更强
- 50-75%的性能和速度都很不错
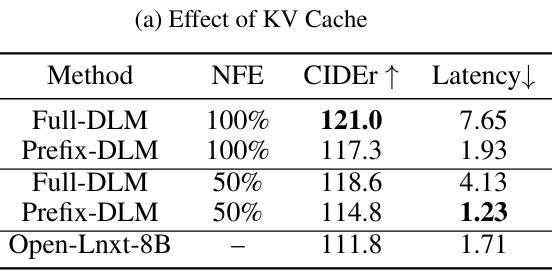
- 有效的加速推理,性能下降少
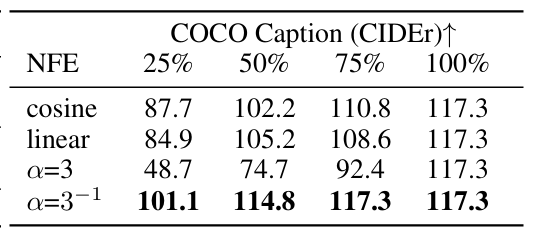
- 先快后慢是对的
消融实验部分
- 验证了互补掩码
- 验证了图像分辨率的影响(输入分辨率)
- OCR(上面四个)的提升更为明显
- 一般视觉理解任务(最后一个)提升不多
STOP,接下来需要进入any2any的调研
这部分内容另开一篇