OPENCSG CHINESE CORPUS A SERIES OF HIGHQUALITY CHINESE DATASETS FOR LLM TRAINING
Dataset:https://huggingface.co/collections/opencsg/chinese-fineweb-66cfed105f502ece8f29643e
Code:https://github.com/yuyijiong/fineweb-edu-chinese
Paper:[2501.08197] OpenCSG Chinese Corpus: A Series of High-quality Chinese Datasets for LLM Training
[TOC]
FineWeb-Edu-Chinese
Hugging Face的数据集主页有一些表述和论文是不同的
FineWeb-Edu-Chinese数据集的构建流程在很大程度上遵循了FineWeb-edu的策略FineWeb-edu从15TB的FineWeb语料库进行筛选- 重点关注数据的教育价值和内容质量
- 中文数据相对匮乏,整合了多个开源中文语料库
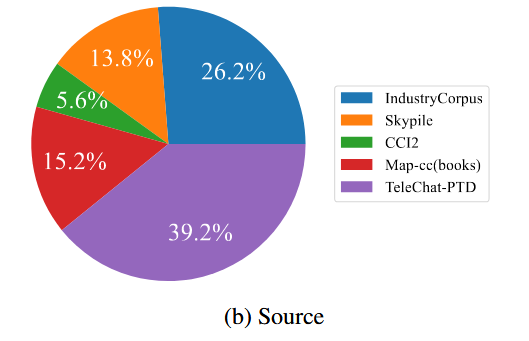
These datasets were selected for their diversity and their educational and technical relevance.
由上述语料库构建了Original Data Pool
首先从教育相关性的方向进行过滤:

- 从
CCI2数据集中抽取100万个条目 - 使用
Qwen2-7b-instruct按照附录A.1的提示词,对样本的教育价值打分0-5,完成数据标注 - 使用这些打分数据,微调
bge-rerank-zh,添加一个线性回归层,得到一个filter - 利用
filter排除所有语料库中分数低于3的数据

opencsg/chinese-fineweb-v2-scorer-train-data · Datasets at Hugging Face
同时为了去重,采用重叠阈值0.7的Min-Hash算法(平衡计算效率、数据多样性)
最后得到:
Fineweb-Edu-Chinese数据集包含 8900 万个高质量样本,为教育和技术应用提供了丰富的资源。
附录A.1提示词:
|
|
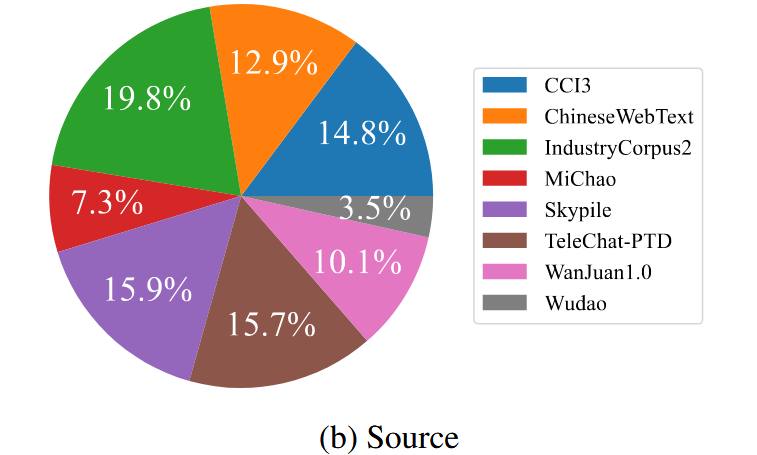
FineWeb-Edu-Chinese-V2
- 进一步扩展了语料库,添加了这个那个和那个……数据集
Qwen2.5-14b-instruct更换了Qwen2-7b-instruct
|
|
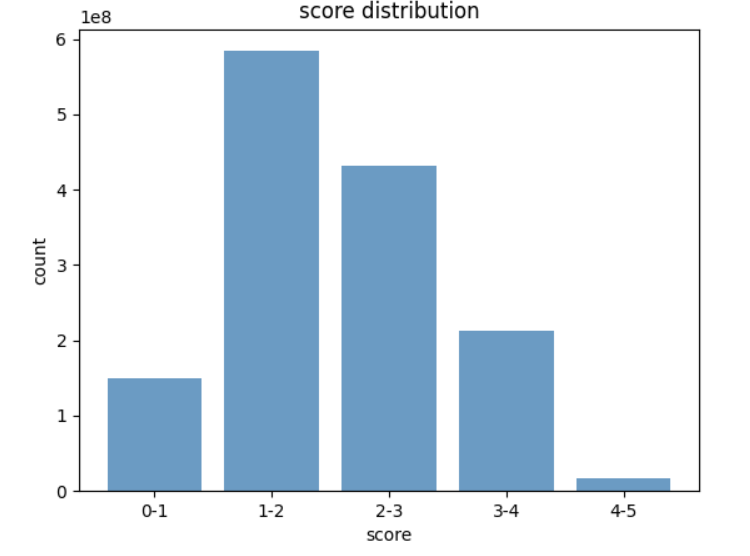
打分的分布如下,最终选择3以上的数据:
Cosmopedia-Chinese
种子数据来源:
- 560万百度百科条目
- 100万个知乎问答样本
- 200万个技术博客条目
丰富领域知识、较高的信息密度
- 中文数据池中的网页文本:质量不够高,含有广告
种子数据:for example an extract from a web page
Cosmopedia-v2的实验说明更大的模型生成数据有显著效果
qwen2-7b-instruct、yi-1.5-9b-chat:倾向于输出简洁、通用的内容,如摘要、大纲(提示词也没救)- 最终选择
glm4-9b-longwriter:教科书主要内容那样足够详细和具体的内容
生成:
- 生成了各种体裁的合成样本,如教科书单元、叙事故事和详细的 “操作指南”
- 温度0.8保证多样性
- 对2000万个样本进行Min-Hash去重,保留1500万个
|
|
以及其他写故事、教程、教科书的提示词
Smoltalk-Chinese
基于
Magpie-ultra-1M和Smoltalk的方法构建,提升任务多样性和对话深度
- 引入了 7 个额外的任务类别:格式约束、总结、改写、文档QA、安全QA、翻译和日常对话。
- 确保了对与自然语言理解和生成相关的任务有更广泛的覆盖。
- 使用
Deepseek-V2.5、Qwen2.5-72B-Insturct等较为先进的模型 - 为
Magpie-ultra-1M使用的11个任务类别生成3轮对话、新任务类别(除日常对话)1轮对话、日常对话5轮
对于质量筛选,首先要保证用户的第一个命令语句是流畅、连贯、清晰的,使用Qwen2.5-7b-instruct打分,保留超过3分的
使用gte-zh-large编码的嵌入进行去重