
[TOC]
被CS336橄榄了,先学个简单点的
然后发现其实做的事情是差不多的,打算学完这个再过一遍cs336的课程
没有完全按照本课程的顺序走,我进行了调整,方便推进
NLP
溯源一下自然语言处理的前世与今生
大概看一下就好
重点放在词嵌入部分,学的比较详细
发展
总体上的发展路线是:规则、统计、机器学习、深度学习
图灵测试:
-
设定一个人类审问者(评判者),分别与一个人类和一个机器进行对话,但他不知道对面是哪一方。
-
如果审问者无法准确区分哪个是人类、哪个是机器,那么就可以说这台机器“具备智能”——因为它在交流上“像人类一样”。
该阶段侧重语言能力,而忽略了理解、情感、动机等更复杂的智能表现
该阶段主要工作是机器翻译,但是基于字典查找和词序规则,效果一般
符号主义与统计方法(1970年代 - 1990年代)
主要分为两个阵营
-
符号主义研究者关注于形式语言和生成语法,注重规则
-
统计方法的研究者更加关注于统计和概率方法 算力上升、机器学习的出现,后者逐渐占据上风
机器学习与深度学习(2000年代至今)
- RNN、LSTM、Attention
- Word2Vec模型使用词向量进行文本表示
- 以BERT为为起点的预训练模型
- Transformer架构的大语言模型
任务
NLP主要关心几个核心任务
分词Tokenization
英文单词之间使用空格隔开,因此分词是一件非常简单的事情
但是这对中文非常困难
|
|
子词切分Subword Segmentation
是基于分词的一种更细粒度的分词,将词语进一步切分为更小的子词单元(subword units)
子词切分特别适用于处理词汇稀疏问题,即当遇到罕见词或未见过的新词时,能够通过已知的子词单位来理解或生成这些词汇。
- BPE
- WordPiece
- Unigram
示例(使用 BPE):
- 单词:
"unhappiness" - 子词切分:
["un", "happi", "ness"]
对于中文来说,一种极端的子词切分就是一个汉字一个单元
- 高效:子词词汇表通常 10k–30k,远小于全词词汇表(可能百万级)
- 处理未登录词(Out-of-Vocabulary,OOV)能力强:新词可通过子词组合表示。
- 提高泛化能力:不同词可能共享了相同的子词(词根)
词性标注Part-of-Speech Tagging
为文本中的每个单词分配一个词性标签,如名词、动词、形容词等
常用机器学习方法:
- 隐马尔可夫模型(Hidden Markov Model,HMM)
- 条件随机场(Conditional Random Field,CRF)
- 基于深度学习的循环神经网络 RNN 和长短时记忆网络 LSTM
学习大量的标注数据来预测新句子中每个单词的词性
文本分类Text Classification
情感分析、垃圾邮件检测、新闻分类、主题识别
理解文本的含义和上下文,并基于此将文本映射到特定的类别
数据质量很关键
实体识别Named Entity Recognition, NER
自动识别文本中具有特定意义的实体,并将它们分类为预定义的类别,如人名、地点、组织、日期、时间等。
|
|
关系抽取Relation Extraction
从文本中识别实体之间的语义关系
|
|
文本摘要Text Summarization
生成一段简洁准确的摘要,来概括原文的主要内容
有两种方式
- 抽取式摘要(Extractive Summarization):直接从原文中选取关键句子或短语来组成摘要。
- 优点:摘要中的信息完全来自原文,因此准确性较高
- 缺点:拼接生成的摘要可能不够流畅
- 生成式摘要(Abstractive Summarization)
- 重新组织和改写,并生成新的内容
- 需要理解文本的深层含义,并能够以新的方式表达相同的信息
- 需要更复杂的模型,如基于注意力机制的序列到序列模型
机器翻译Machine Translation
- 神经网络的Seq2Seq模型、Transformer模型等
自动问答Automatic Question Answering, QA
自动问答任务模拟了人类理解和回答问题的能力,涵盖了从简单的事实查询到复杂的推理和解释。
自动问答系统的构建涉及多个NLP子任务,如信息检索、文本理解、知识表示和推理等。
文本表示
需要将人类语言转化为计算机能够存储、使用的格式
- 输入:文本中的语言单位(如字、词、短语、句子等)以及它们之间的关系和结构信息
- 输出:向量、矩阵或其他数据结构
One-Hot Encoding
- 每个词用一个独热向量表示,向量长度 = 词汇表大小。
- 只有对应位置为 1,其余为 0。
|
|
- 向量维度高、稀疏(大部分为 0)
- 无法表示语义相似性(“猫”和“狗”距离与“猫”和“跳”一样远)
有一种拓展方式是将1改为词频
Bag-of-Words(词袋模型,BoW)
- 忽略词序,只统计词频。
- 每个文档表示为一个词频向量
|
|
- 丢失词序信息
- 无法处理新词(OOV)
- 无语义信息
与one-hot的区别是,one-hot每个词一个向量,bow一个文档一个向量
TF-IDF(Term Frequency-Inverse Document Frequency)
- 综合考虑词在文档中的频率(TF)和在整个语料中的稀有程度(IDF)
- $t$: 词
- $d$: 文档
- $N$: 总文档数
- $TF(t,d)$:$t$在$d$中的词频
- $DF(t)$ : 包含$t$ 的文档数
对于文档:某个词出现的越多,说明越重要
对于语料:某个词出现的越少,说明越稀有,因此价值越高
-
优点
- 能识别重要词(高频且稀有)
- 广泛用于信息检索
-
缺点
-
仍是词袋模型,无语义
-
无法捕捉上下文
-
词向量Word Vector
一个词的含义由其上下文决定
这个章节唯一有用的部分(
来源:
使用词嵌入(Word Embedding)方式,将词转化为词向量
首先我们需要考虑到语义相似
上述方法都无法表示两个词是语义相似的,例如好和棒,他们只会处理为两个单独的字
我们希望我们的向量表示能够有相似度、距离的度量
学会
好的使用,由于相似,因此能够泛化到棒
同时一个词在不同语义中会含有不同的意思(积极的、消极的)
因此我们需要词向量的表示足够丰富,并且来源于上下文
Word2Vec
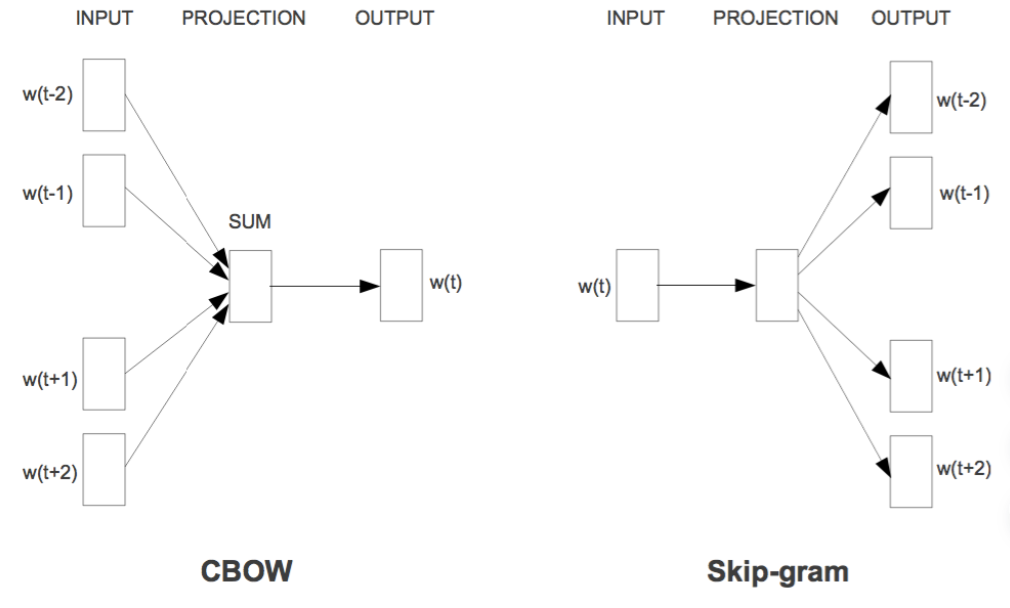
- CBOW:使用大量语料,选择周围的词,预测中间的词
- 输入是词汇表的01向量(周围的词为1,其他词为0),输出固定为预测词为1其他词为0的向量
- 反向传播,最终得到每个词的权重即为词向量
- Skip-Gram:选择中间的词,预测周围的词
相比于传统的高维稀疏表示(如One-Hot编码)
Word2Vec生成的是低维(通常几百维)的密集向量,有助于减少计算复杂度和存储需求
但由于CBOW/Skip-Gram模型是基于局部上下文的,无法捕捉到长距离的依赖关系,缺乏整体的词与词之间的关系,因此在一些复杂的语义任务上表现不佳。
Glove
-
统计词语共现频率
-
先统计整个语料中,每两个词一起出现的次数,形成一个“共现矩阵”
-
然后让模型学习:向量之间的点积 ≈ 共现次数的对数
-
比如:“猫”和“抓”的共现次数多 → 它们的向量点积要大
-
杂谈
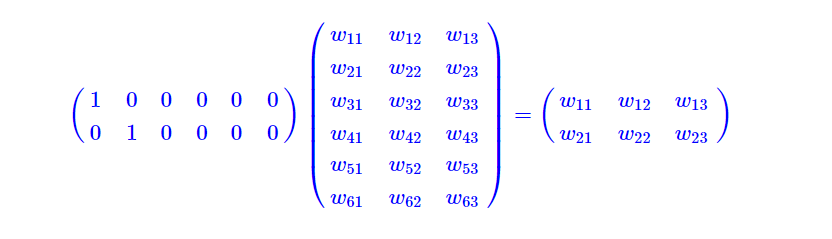
Embedding似乎就是喂入一个one-hot矩阵,过几个全连接层
但是对于one-hot的矩阵乘法来说,似乎本质上是一个查表
权重矩阵构成了一个词向量表,one-hot从中取出对应的向量
(一种优化是这里冻结0的权重,直接查表,不做矩阵乘法)
整个过程是一个自监督的
我们输入one hot,然后连接一个全连接层,然后再连接若干个层,最后接一个softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是字、词向量表
所谓语言模型,就是通过前n个字预测下一个字的概率
Word2Vec
这个实在是过于深入人心了,我们来重点聊一聊
word2vec最大的亮点是Word Analogy(词语类比),指的是两个词语之间的关系与另外两个词语之间的关系相似
king - man + woman = queen
即通过上下文信息来估计某个词出现的概率
实际训练中是非常慢的,词汇表一般巨大,假设为$|V|$,有以下提速方式
- 层次Softmax
- 传统Softmax需要最后对所有词汇表的输出概率做归一化,代价为$O(|V|)$
- 这里将词汇表组织成一颗二叉哈夫曼树,每个叶节点对应一个词
- 计算某个词的概率需要沿着路径,代价为$O(\log_2|V|)$
构造哈夫曼树时使用 词频 作为权重
每个结点本质上是一个sigmoid控制的二分类:向左/向右
只更新路径上的权重
- 负样本采样
- 假设我们需要通过
dog预测周围词bark - 我们可以基于
dog,采样$K$个负样本(语料中不与dog搭配的词) (dog, apple), (dog, table), ...- 本质上做了多组二分类:判断词对是否常见0/1
- 目标是
bark趋近于1,$K$个样本趋近0 - 使用这些样本进行训练,并且只更新相关的权重,$O(K)$
- 假设我们需要通过
关键词提取
这里作者做了一个很有意思的应用,根据文章内容提取关键词
TF-IDF当然是一个合适的做法,速度快$O(N)$,但是只考虑了相同词,而没有考虑相似词
而且概率是离散值计算出来的
这里认为,关键词可以尽可能获取文章的大意,因此数学上我们可以表示为:
$$ p(s|w_{key}) $$我们需要最大化这个概率:由关键词$w_{key}$推出文本$s$
基于朴素贝叶斯假设
$$ p(s|w_i) = p(w_1,w_2,...,w_n|w_i)=\prod_{i=j}^np(w_j|w_i) $$所以我们用word2vec求出所有的$p(w_j|w_i)$,虽然是$O(N^2)$
最后出来概率最高的几个就是关键词
而且概率是神经网络出来的,自带平滑,处理近似词语效果更加合理
相似度
从word2vec得到的词向量,可以使用余弦相似度比较两向量的方向
- -1:词义相反
- 0:正交,无相关性
- 1:词义相同
余弦相似度大,事实上意味着这两个词经常跟同一批词搭配
也就是说基本可以直接替换
|
|
城市名词之间替换是很合理的,因此相似度高
相关
可能会觉得东莞、广州好像没什么关系,不如广州和白云机场
这个被称为相关
$$ \log\frac{p(x,y)}{p(x)p(y)} = \log p(y|x)-\log p(y) $$互信息越大,说明x,y两个词经常一起出现