[TOC]
Transformer
- [参考资料](https://datawhalechina.github.io/happy-llm/#/./chapter2/第二章 Transformer架构)
注意力机制
对于一个token序列,注意力机制建立了三个键值:
- query:表示想找什么特征
- key:表示我有什么特征
- value:信息正文
因此为了衡量query和key的特征之间的相似度,我们可以引入点积
所有的query向量和所有的key做点积
$$ QK^\top $$得到注意力矩阵,点积越大越相似
同时为了防止数值爆炸(维数$d_k$越大,累加的数值会越多)
做一下缩放:
$$ \frac{QK^\top}{\sqrt{d_k}} $$然后通过softmax做一下归一化,确保所有权重之和为1,方便约束数值
最后对应权重乘上对应的Value
这样我们计算得到的是上下文文本内容的vector
$$ \text{attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$Self-Attention
注意力机制处理了两个序列(Q、K来自不同序列)之间互相的查询
自注意力理所当然是查询自己
- 检查自己所说过的内容,确保逻辑一致
对于自注意力,每个Token都会有自己的Q、K、V
自然三个矩阵的维度是匹配的(跟序列长度有关),(batch_size, seq_len, d_model)
**Question:**如果你的输入序列有 4 个 token,那么计算 self-attention 的注意力矩阵 size 会是多少?
**Answer:**每个token对应另外4个token的注意力分数,所以是(4,4)
Mask Self-Attention
模型学习过程中,有时候会遮蔽一些token,以该机制阻止计算注意力
最常用的就是通过Mask,遮蔽未来的信息,只允许模型利用历史信息
如果待学习的文本序列是[BOS] I like you [EOS]
|
|
模型能看到的内容就是未被MASK的token
MASK是一个典型的上三角矩阵,因此我们可以创建一个上三角矩阵作为注意力掩码
- 输入:
(batch_size, seq_len, hidden_size) - 注意力掩码:
(1, seq_len, seq_len)
batch中所有内容都可以通用(一般seq_len是一样的)
Multi-Head Attention
- 一次注意力计算只能拟合一种相关关系
- 代词关系、主谓关系、定语修饰……token之间的关系非常多余
我们希望能从多个维度去寻找注意力的相关,自然引入多头注意力机制
- 同时对一个语料进行多次注意力计算,每次注意力计算都能拟合不同的关系
- 最后的多次结果拼接起来作为最后的输出
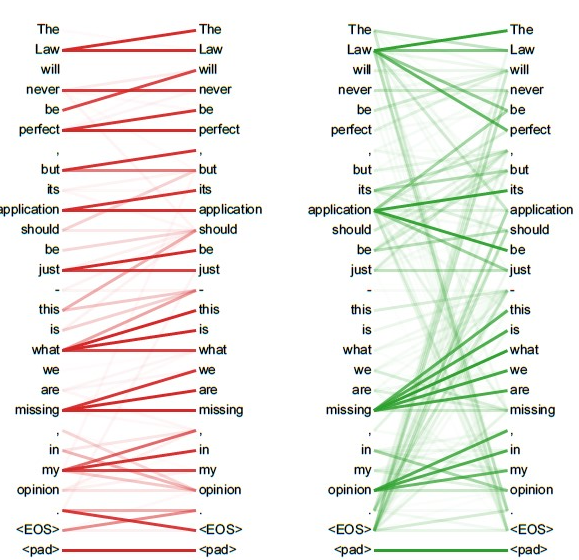
如图,不同的注意力查询,每个token所关注的其他token都不太一样
假设文本的输入序列矩阵是$X$,对于第$i$个头
$$ Q_i = XW_i^Q, K_i=XW_i^K, V_i = XW_i^V $$其对应的注意力为:
$$ \text{head}_i = \text{attention}(Q_i, K_i,V_i) $$多头注意力表示为:
$$ \text{MultiHead}(Q,K,V) = \text{Concat}(head_i)W^O $$