Large Language Diffusion Models
[TOC]
Intro
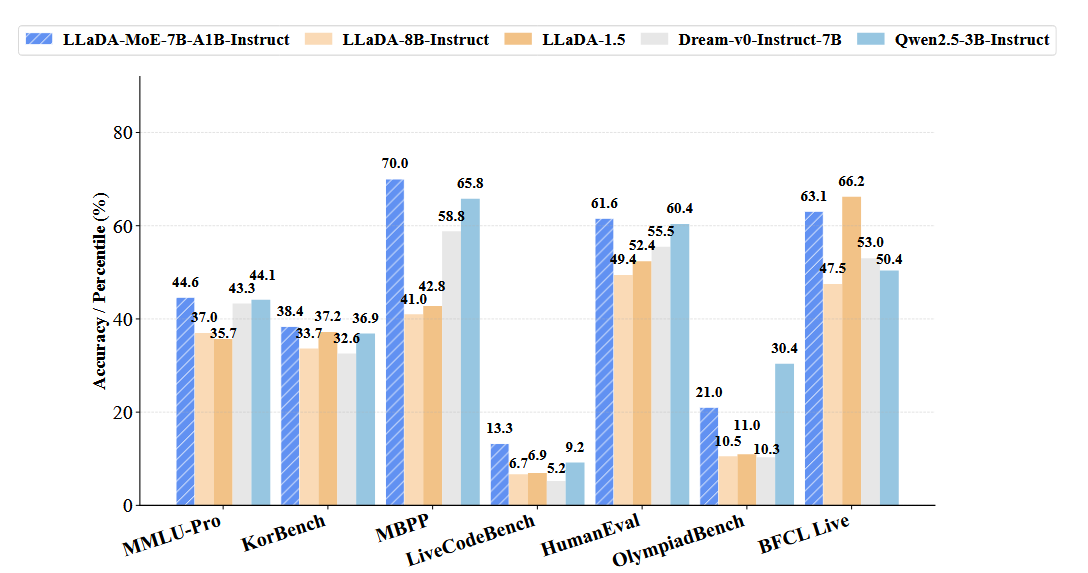
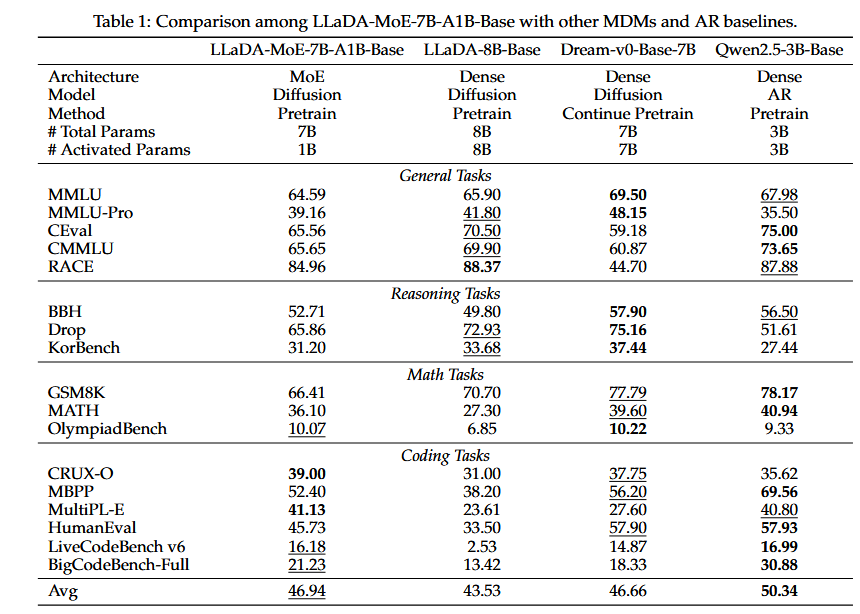
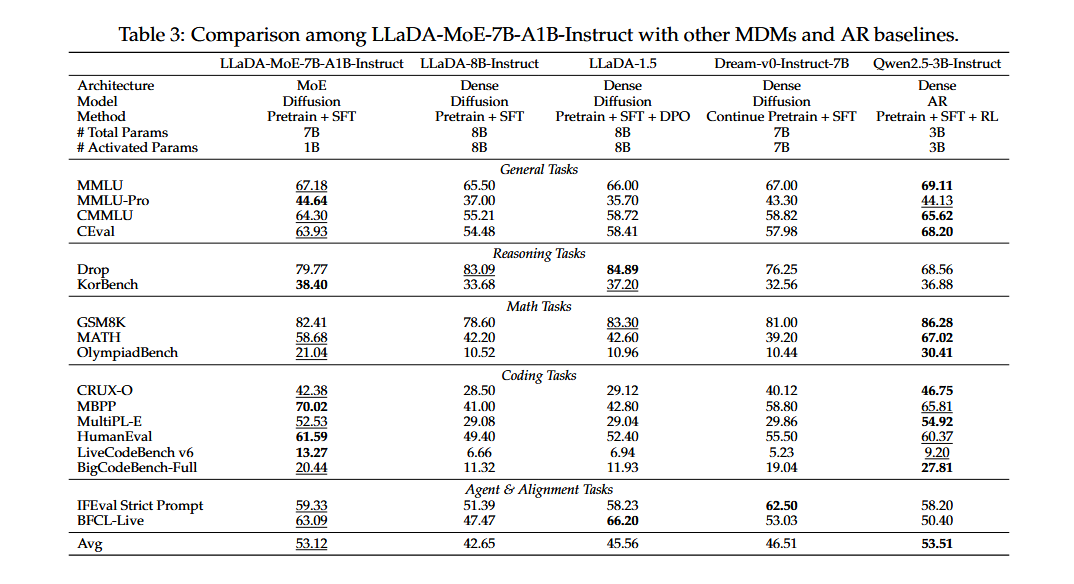
- LLaDA-MoE:激活1.4B参数的情况下,超过先前8B的DLMs性能,取得DLMs的SOTA,与Qwen2.5-3B-Instruct性能相当
LLaDA-MoE
Architecture

- RMSNorm、SwiGLU、RoPE、QK-LayerNorm
Train

- Pretrain Stage 1:从头开始训练,10T
- Pretrain Stage 2:从相同的底层数据重新采样10T(提高数学、代码的权重),继续训练
- Annealing Stage 1:从Pretrain Stage 2中最好的checkpoint开始,训练500B的高质量文本
- Annealing Stage 2:将RoPE的base从10000提高到50000(扩充4k到8k的上下文),500B
- SFT
Annealing:用更高质量的数据让模型“收敛得更好”
- 训练阶段(预训练+SFT)的损失函数同LLaDA
- 预训练1%是随机长度,99%是4096定长(同LLaDA)
MoE Routing
$$ p_t = \text{Softmax}(\text{Router}(h_t))\\ o_t = \sum_i p_{t,i}E_i(h_t), \quad \text{where }p_{t,i} \in\text{Topk}(p_t) $$- $h_t$是hidden state
- $E$是专家网络
MoE选取p最大的k个专家网络进行加权
为了平衡负载,采用了标准的MoE auxiliary loss
-
Load Balancing Loss
- $P_i$:token级的专家$i$被分配的平均概率
- $f_i$:经过所有token每个专家被选中的频率
- $N$:专家数
通过该损失避免某个专家被频繁选中
- Z-Loss
- $z_t$表示$\text{Router}(h_t)$
- $z_{t,j}$即为第$j$个专家的打分
通过该损失抑制logits分布,防止softmax极端化
LLaDA-MoE为LB设置0.01权重,为Z-Loss设定0.001
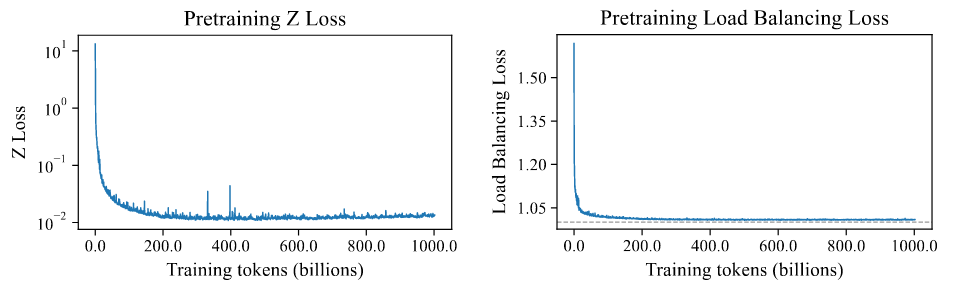
Experiments