[TOC]
MMaDA: Multimodal Large Diffusion Language Models
问题
- 先前的多模态架构混合,不同模态需要不同组件、不同数据处理方式
- 扩散模型后训练策略欠缺研究
- 如何文本与视觉模态协同学习、各方面性能超过各领域现有模型
- 如何确保模型具有泛化能力
核心贡献
- 统一Diffusion架构:消除模态专用组件,保持跨任务性能
- 混合Long-CoT的后训练:统一CoT格式,对齐跨模态推理过程,协同训练
- UniGRPO:专用的强化学习方法
- SOTA:文本推理、多模态理解、文生图三方面均是SOTA(AR、混合、扩散)
Method
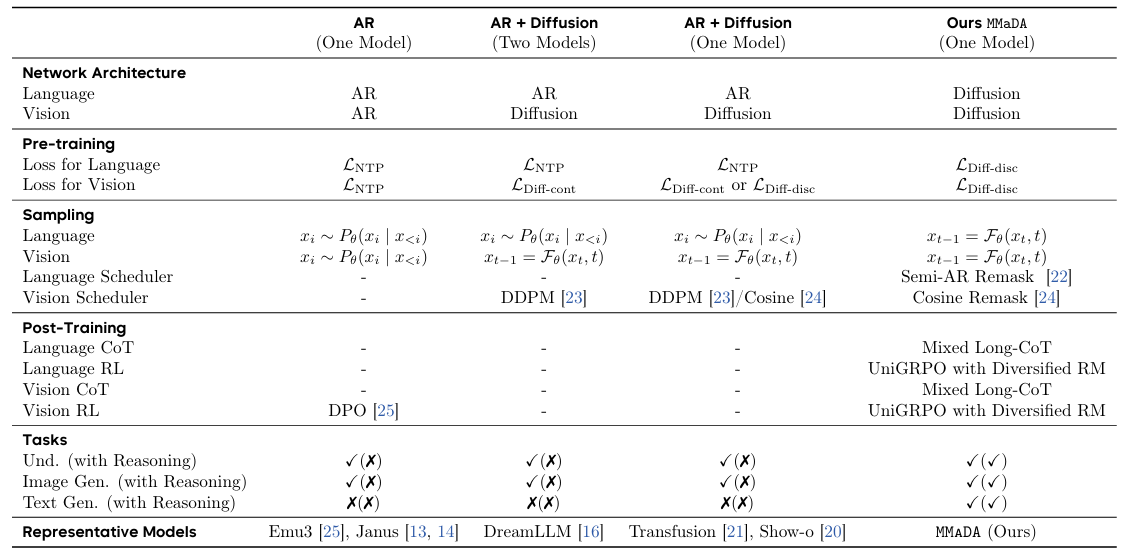
Pretrain
- Data Tokenization
- 文本:采用LLaDA的tokenizer
- 图像:采用Show-o所使用的pretrained image quantizer
- 基于MAGVIT-v2架构(一个图像离散化模型)
MAGVIT-v2的输入与输出
- 输入:单张静态图片的像素阵列、由多帧图像组成的序列
- 输出:一个token序列
论文中采用$F=16$的下采样因子
对于$H\times W$的图像,转化为一维的$\frac{H\times W}{F^2}$长度序列
- 统一的概率建模与目标
- 定义MMaDA为一个Mask Token Predictor,直接预测文本与图像的
[MASK] - 仅在
[MASK]的图像或文本Token上做统一交叉熵损失
- 定义MMaDA为一个Mask Token Predictor,直接预测文本与图像的
Post-Training with Mixed Long-CoT Finetuning
MMaDA明确面向:
- 推理密集型任务(例如数学)
- 具备World-knowledge-aware的文生图
- 事实一致性非常重要
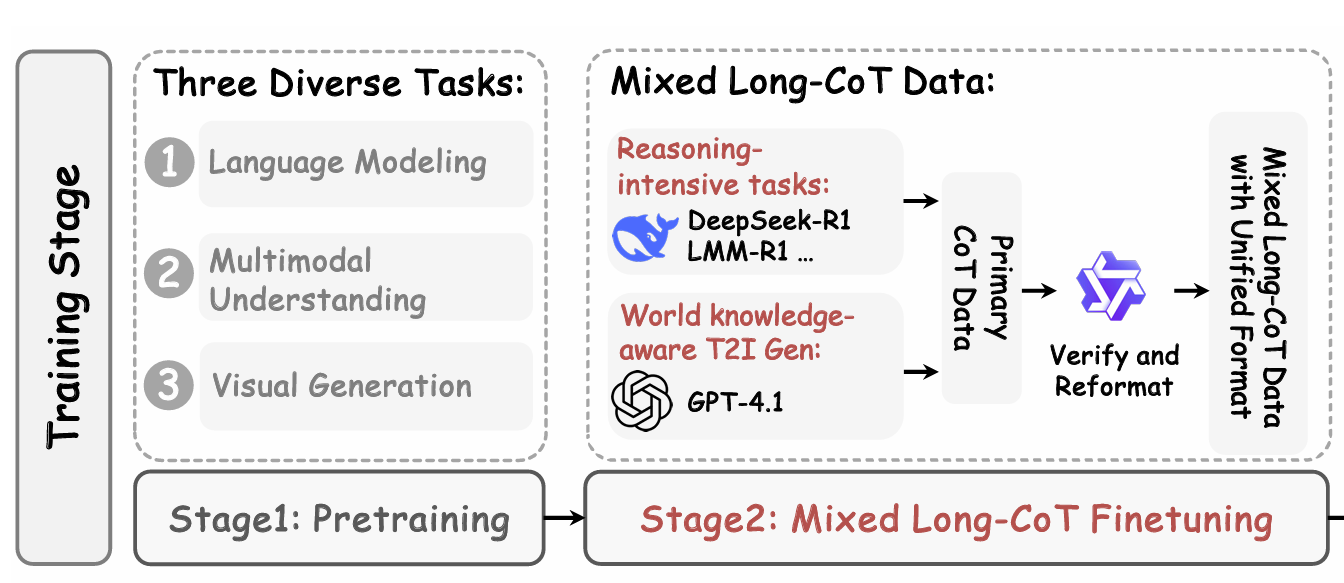
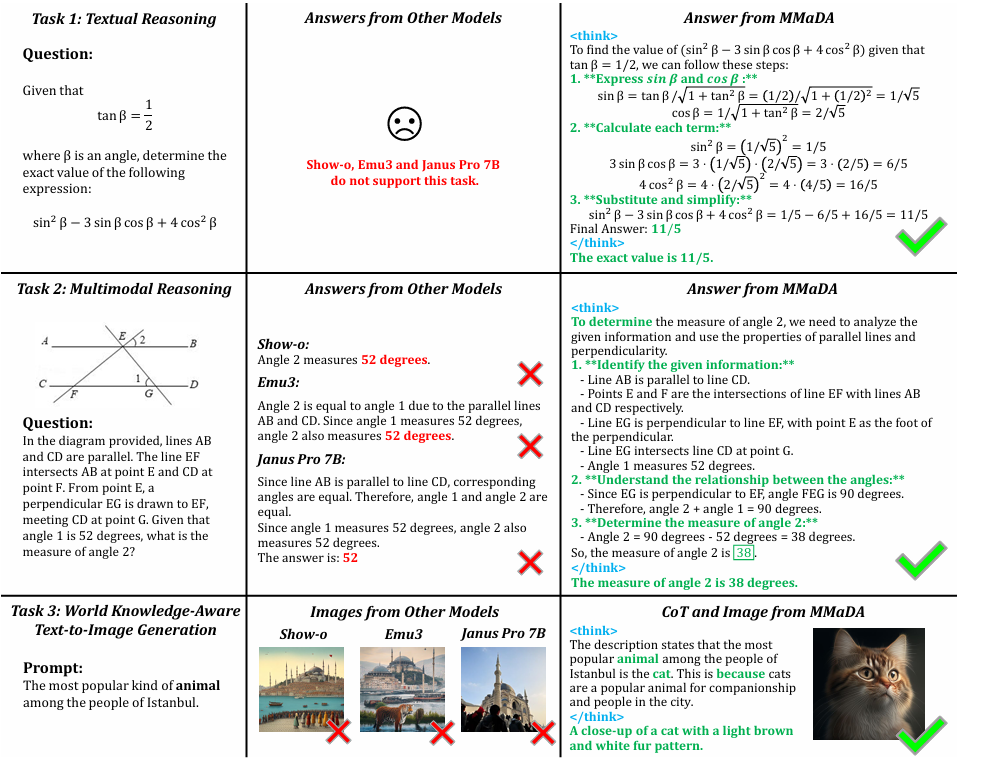
为进行稳定的后训练,论文整理了一个包含三类核心任务(文本推理、多模态推理、文本到图像生成)CoT数据集
利用这篇数据,在RL之前通过SFT做冷启动
- 统一的CoT格式:消除不同任务的输出异构性
|
|
后续证明了有益于跨模态的协同训练与对齐
希望文本推理逻辑指导图像生成
- 多样性、复杂性、准确性
- 通过已有的LLM、VLM,合成多样化的数据
- 使用模型过滤,只保留高质量、长形式的CoT样本
MMaDA进行了混合任务的CoT微调
- 保留提示词,对response进行加噪
- 通过预训练得到的Predictor进行损失计算
Post-Training with Unified RL
- 自回归模型:每个Token的条件概率都非常好计算,适合RL
- Diffusion:过程复杂,无法直接使用传统强化学习方法
- 局部掩码依赖:只有
[MASK]处有预测概率,其他位置已知 - 掩码比例敏感:训练必须兼容不同噪声程度的恢复
- LLaDA采样大量样本,造成RL开销巨大
- 非自回归序列似然:
- AR模型:句子概率可以通过token概率乘积计算
- Diffusion:很难计算
- 局部掩码依赖:只有
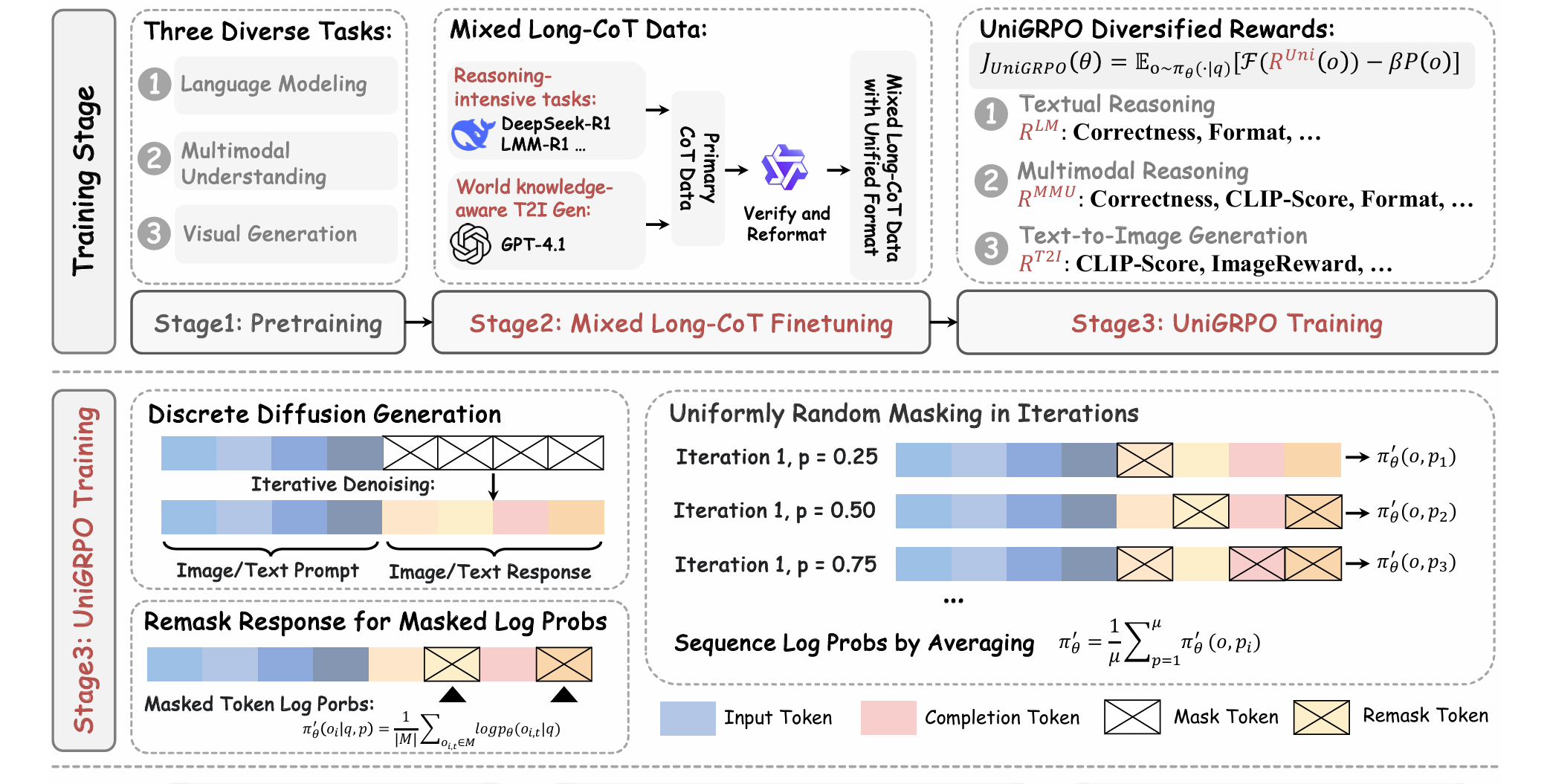
UniGRPO
这部分搁置一下 后续补一下RL的知识
主要有三个关键点
- 结构化加噪策略
- 序列对数似然近似为:被遮位置对数概率的平均
- 用旧策略和当前策略的“近似序列似然”做比值
UniGPRO的奖励是多样化的
- 文本推理奖励
- 答案正确奖励
- 格式奖励(
<think><think>)
- 多模态推理奖励
- 同上
- CLIP奖励:使用原始 CLIP 分数衡量文本-图像的语义一致性
- 文生图奖励
- 同上
- 图像奖励:反映人类偏好得分
Inference
- 文本生成:采用半自回归采样
- Masking Schedule采用线性计划,与LLaDA一致
- 图像生成:采用低置信度重掩码
- 余弦噪声调度
Experiments
一般的benchmark跳过