Online-PVLM: Advancing Personalized VLMs with Online Concept Learning
[TOC]
Intro
- Challenge
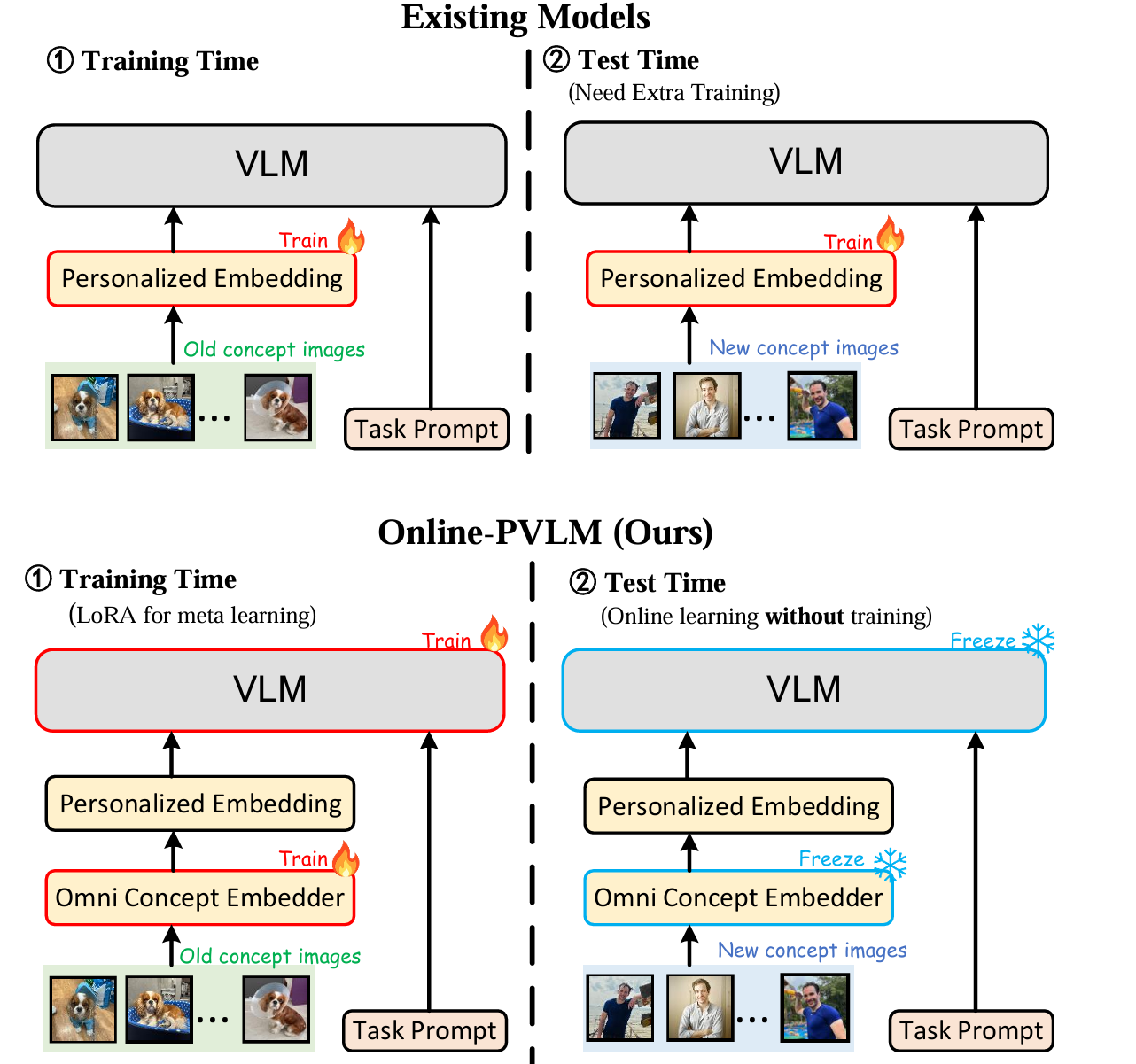
- 缺乏记忆:微调技术无法进行长期记忆
- 离线训练
- 单个概念训练依赖大量负样本、不利于扩展
- 目的
- 能够存储并调用先前交互中的用户特定特征,从而适应不断变化的语境
- 无需为每个实例重新训练即可无缝整合新概念
- 以最小的计算开销高效适应不同用户
- Contribution
- 首次在线概念学习任务
- OP-Eval:通过大规模、稀疏且多样化的概念-任务配置,真实地模拟了在线概念学习场景
- Online-PVLM:采用双曲表示以实现高效个性化,能够处理持续增长的概念数量
Method
Definition
对于概念$c_i$(人、物),任务输入有三个部分:
- $n$张概念图像$R^{(j)}_i$
- 查询图像$Q$
- $m$条与$Q$相关的问题$q_j$
输出:
- 答案$a_j$,与问题$q_j$一一对应
为解决问题,需要生成概念嵌入$z_i$
以<sksi> is <embed.>1<embed.>2...<embed.>k.作为软提示嵌入概念
使得模型生成正确答案
Online-PVLM
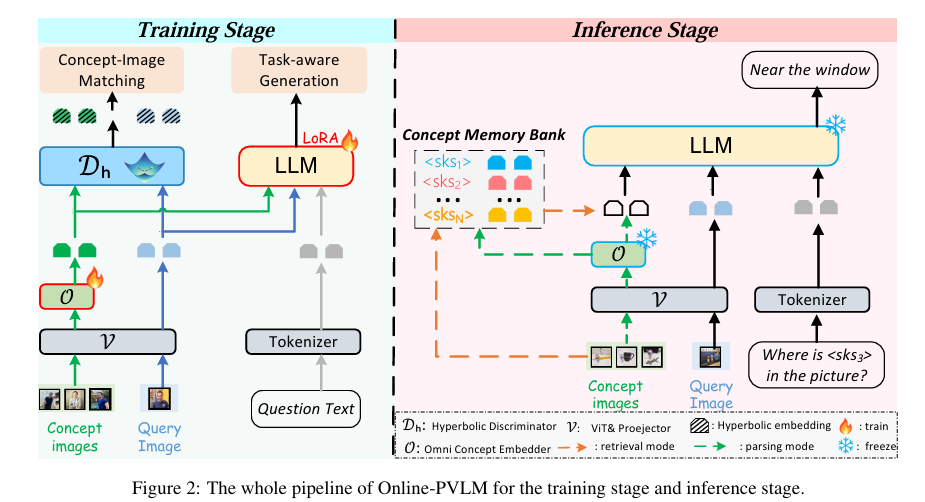
框架有三部分组成:
- Omni Concept Embedder(全能概念嵌入器)$\mathcal{O}$
- hyperbolic discrimination module(双曲判别模块)$\mathcal{D_h}$
- LoRA-based VLM $\mathcal{M}$
Training
Concept Embedding Generation
先前工作+paper证明了基于 LoRA 的模型已展现出处理元信息的强大能力
因此只需要选用一个轻量级的概念嵌入器,从vision encoder中提取概念即可
给定概念 $ c_i $ 的 $ n $ 张概念图像,记作 $ R_i \in \mathbb{Z}^{n \times 3 \times H \times W} $,概念 $ c_i $ 的嵌入向量可表示为:
$$ z_i = \text{MLP} \left( \frac{1}{n} \sum_{j=1}^n \text{IN}(\mathcal{V}(R_i^{(j)})) \right) $$- $\mathcal{V}(\cdot)$ 表示带有多模态投影器的 ViT 特征提取器
- IN(·) 则对每个特征应用instance-normalized
Hyperbolic Discrimination Learning
用于在训练中衡量两个向量的距离,计算损失
希望通过双曲空间让两个特征是可分的
- 同一概念:距离要小
- 不同概念:距离要大,同时设定阈值margin,要求不同概念的距离至少比这个大
流程:
- 计算查询图像$Q$的视觉特征(ViT输出):$t =\mathcal{V}(Q)$
- 通过参考图像$R_i$,依次计算概念集合的概念嵌入$z_i$(Omni Concept Embedder $\mathcal{O}$的输出)
定义样本的损失:
$$ \ell(y) = \begin{cases} d_{\text{hypo}}^2, & y = 1, \\ \left[ \max(0, m - d_{\text{hypo}}) \right]^2, & y = 0, \end{cases} $$- $d_{\text{hypo}}$是两个特征的双曲空间距离
- y=1同一概念:最小化距离
- $m$是设定的margin阈值
- y=0不同概念:必须大于等于margin
Joint Training with Generative Loss
在语言层加了轻量 LoRA;训练时同时最小化两种 loss:
- 模型本身的自回归生成损失
- 前面定义的判别损失
- 着重训练Omni Concept Embedder
- $\theta_e$:Omni Concept Embedder 的参数
- $\theta_m$:VLM 的参数(包含 LoRA adapters)
Inference
- Retrieval mode:若某个概念以及缓存,则直接从Concept Memory Bank取出对应的$z_i$
- 常数复杂度
- Parsing mode:冻结的 Omni Concept Embedder前向一次,生成$z_i$
- 缓存到bank中
最后构造成软提示
OP-Eval
- 现有的dataset的概念数明显不足
- 任务单一
- 未见概念、跨概念、多概念、数据稀疏等问题考察不多
paper构造了OP-Eval数据集:
- 1,292 个概念、约 3,000 张图、约 30,000 个高质量问题样例
数据集来源:
- PVIT:2410.07113 Personalized Visual Instruction Tuning
- Myvlm
- Yo’llava
过滤
针对两类关键噪声来源,提供过滤策略:
- PVIT数据集出现的人工拼接图:通过标签直接删除
- 低质量、模糊图
- Variance of the Laplacian(拉普拉斯方差)初筛
- 人工复核确认质量
分类
目的:根据图像中主体的突出程度进行分类

- 单一主体:目标概念是主要主体且无其他物体
- 次要干扰:目标概念是主要主体,但存在少量视觉干扰
- 主要干扰:目标概念是主要主体,但部分被遮挡或背景杂乱
- 双主体:存在两个同等显著的主体
- 多主体:出现多个不同主体,焦点不明确
- 非主体:目标概念缺失或仅存在于背景中
两位人工标注者 + GPT-4o-0806共同评估
标注的方式讲的不是很细致
大致应该是按照突出程度打分:Single=1, Minor=2, Major=3, Dual=4, Multi=5, Non=6
取三者的均值作为最后的分类
对于每个概念,取突出程度最高的6张图作为concept image set
剩余图片由于难度较高,作为test
Task
所有任务都由GPT-4o-0806模型
提供概念图像及test image结合,生成对应的问题
所有生成的问题均由两位人工标注员交叉验证,以确保其质量与一致性
为了方便生成题目,首先使用模型生成concept的描述
|
|
Concept Identification概念识别
- 查询概念是否出现在test图像中
- 前述工作的test图作为正样本
- bing image search得到负样本(没有说细节?)
询问概念是否存在于样本之中
Concept QA
- 文本QA问答:例如问颜色、形状等基本细节
- 生成选择题题干+选项+答案
- VQA:……
- Confusion VQA
- 刻意提问干扰物体
- 诱导模型把干扰物误当成目标概念
- 原因是:许多 VLM 容易凭“表面相似”把别的物体当目标概念
|
|
对于ConfusionVQA,首先利用GPT4o-0806生成测试图像的描述
将该描述与概念说明、测试图像描述及典型示例相结合,构建基于混淆逻辑的问题
- OpenAI o1-12-17
|
|
|
|
Caption
要求模型输出必须提到概念名
Ex
实验分两大类:Novel Concept Test(新概念) + Cached Concept Test(缓存概念)
数据集 (Datasets):
- OP-Eval
- 1292 个概念
- 30000 个问答对
- P-Bench: 用于补充测试,大量人物概念,主要使用其 VQA 子集
- MyVLM: 用于Cached Concept 测试,29 个物体级概念
基础模型: InternVL2.5-8B
Novel Concept Test
- 评估模型对unseen concepts的鲁棒性与泛化
模型通过Parsing Mode即时生成概念嵌入
模型使用OP-Eval中的683的概念进行了训练
- OP-Eval 中的 608 个测试概念
- P-Bench 测试集中的 341 个概念
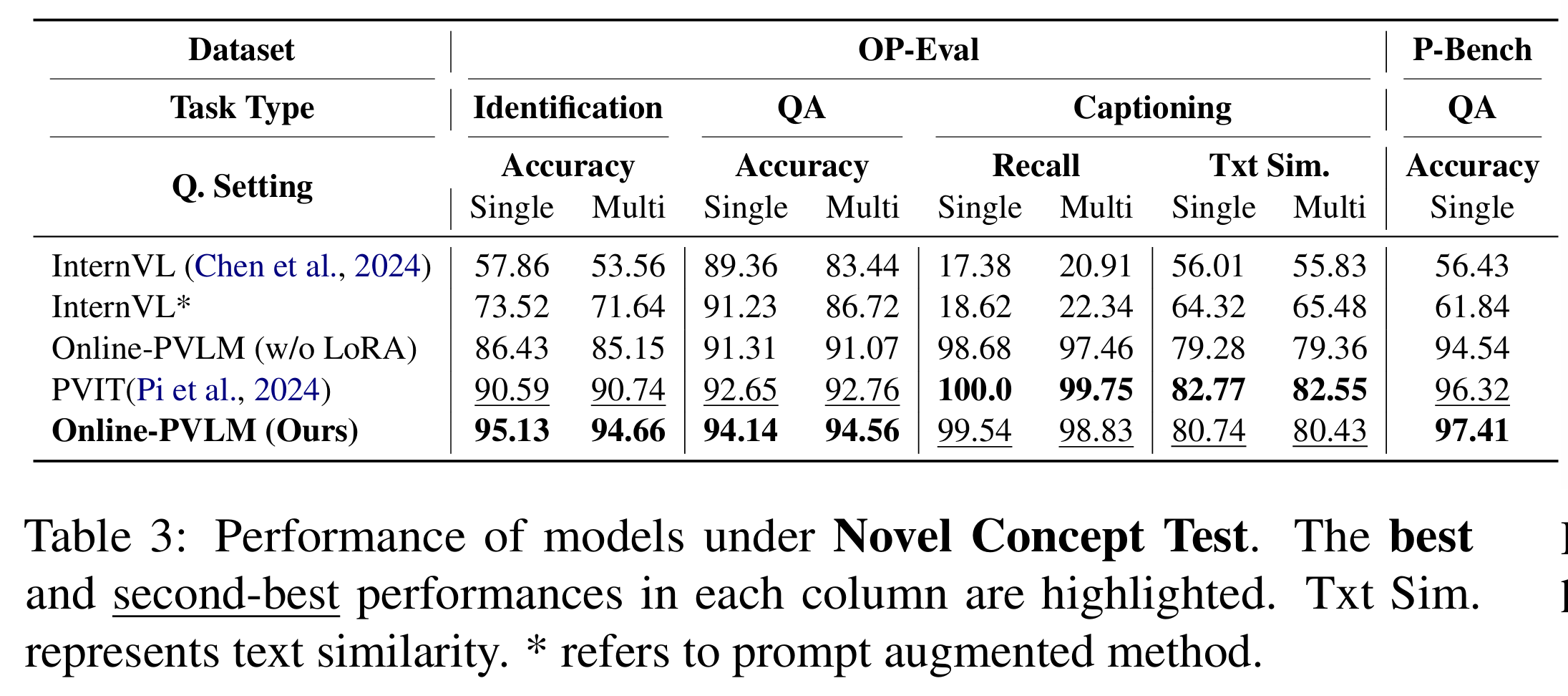
Prompt-Augmented:在提示词中加入了gpt4o生成的概念描述
Online-PVLM w/o LoRA: 去掉 LoRA 模块的变体,只靠 Omni Concept Embedder
- paper认为判别loss提高了识别能力,造成生成能力轻微下降(因此Caption没有最好)
Cached Concept Test
测试Retrieval Mode下的性能
-
MyVLM 数据集 (29 个概念) 。
-
从 OP-Eval 中随机抽取的 1,000 个概念
MyVLM 和 Yo’LLAVA: 这两种方法都需要针对每个新概念进行单独的训练
- 从concept image set中为每个概念提取最多 4 张图像,用于生成嵌入
- 直接使用训练好的 Omni Concept Embedder生成
- 存到bank中
- 测试时,模型直接通过概念标识符(
<sks>)找到对应向量- 注意:嵌入和测试过程的图像是隔离的
