[TOC]
RAP Retrieval-Augmented Personalization for Multimodal Large Language Models
RAP Retrieval-Augmented Personalization for Multimodal Large Language Models
Intro
- 对每个concept进行微调是昂贵的
- MyVLM和Yo’LLaVA都需要进行额外的训练去添加新的concept从而实现个性化
- 都需要一些样本的正例与负例进行学习
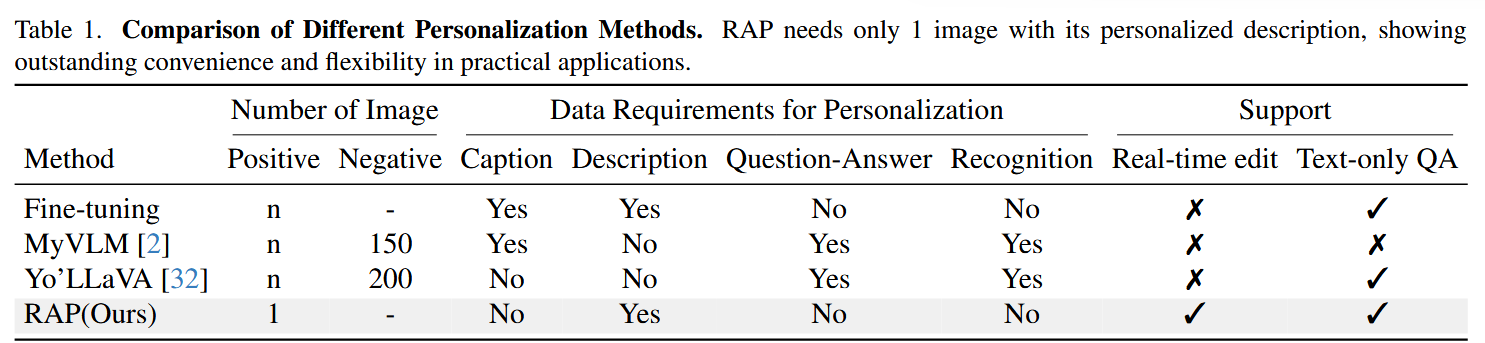
- RAP只需要一张图以及一些相关的信息
- 支持用户实时修改database,从而调整模型的个性化输出
同时RAP构建了一个Pipeline,用于收集大量训练数据,帮助模型先学会理解如何使用用户个人concept的范式
paper的贡献总结为:
- 提出RAP-MLLM框架,支持用户在不需要训练的情况下让模型适应新的concept
- 开发了一个训练数据收集pipeline,支持训练个性化assistant
- 最终模型在image captioning and question answering等个性化任务中表现优异
Method
RAP Framework
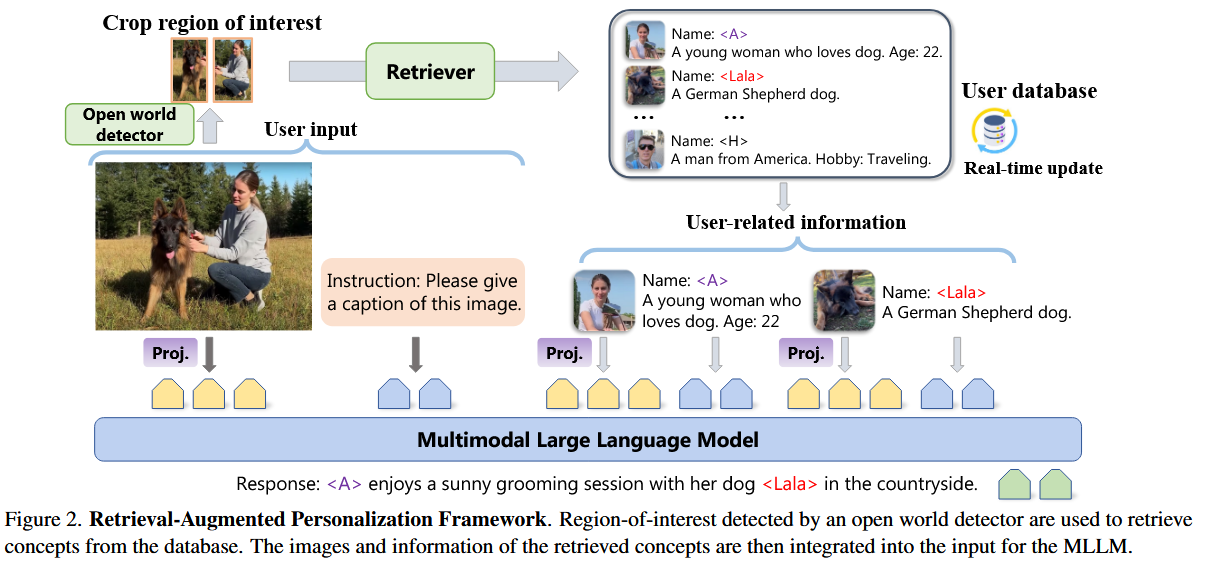
- 建立一个数据库,记录每个concept的一个头像、描述,使用视觉特征作为检索键
- 视觉特征通过一个现有的已经过训练的Encoder
- 检索
- 对于用户的图片输入
- 基于YOLO系列做detector,根据设定好的参数识别出ROI区域
- 将ROI区域送入Encoder,得到视觉特征,进行检索
- 计算欧拉距离最近的top-k组concept
- 对于用户文本输入
- 通过文本中的name,检索是否存在于database中,进行提取
- 对于用户的图片输入
- 生成:将多组(图片,描述)以及用户输入图片及描述送入MLM进行回答
Personalization Dataset
如果只是这样,当时的模型也不一定总能生成准确的回复
因此希望构建一个数据集,用于提升模型的生成能力
视觉定位Visual grounding
基于RefCOCO(单物体目标检测数据集)、ILSVRC2015-VID( 视频目标检测数据集)、TAO 以及 CustomConcept101、Object365 (多对象数据集)
- 输入:裁剪出物体对应的标注图像,使用Gemini1.5生成描述
- 训练输出:对应物体的边界框
指令遵循Instruction Following
该部分包括:
- 图像标题生成 (Image Captioning):将目标概念的裁剪图、名称及描述注入模型输入,要求模型生成能反映这些特定概念的标题
- 问答 (Question Answering) :利用种子问题迭代生成多样化的对话,涵盖视觉相关问题和纯文本查询
trick
- 为了让模型对检索器返回的噪声更加鲁棒,在训练输入中加入噪声概念,但是要求模型的输出仍然不变,学会过滤信息
- 对裁剪出的图片进行旋转、翻转、3D合成新视角……
- 加入LLaVA模型原有的数据集LLaVA-Instruct-665k,防止灾难性遗忘
Training-Free Personalization via Retrieval and Reasoning
Training-Free Personalization via Retrieval and Reasoning on Fingerprints
Intro
- 现有方法都需要进行训练
- 但是VLMs实际上接触的语义概念是足够多的,内部知识丰富
Paper同样构建了一个带有参考图像、描述的数据库
使用VLM通过distinctive attributes对描述进行enrich
Method
Database
首先构建database
- 输入:
- 参考图像 ($I_i$):用户提供的包含特定个性化概念图片
- 概念名称 ($c_i$):用户为该概念起的名称
- 类别 ($g_i$):该概念所属的语义类别(如“毛绒玩具”或“猫”)
- 中间处理:
- 利用 VLM 提取指纹属性 ($A_i$)(即能将该物体与其同类区分开的关键特征,如“粉色领结”、“Nashville 吉他标志”)和判别性描述 ($d_i$)
- 利用视觉编码器和文本编码器生成图像特征 ($f_i^V$) 和文本特征 ($f_i^T$)
- 输出(存入数据库 $\mathcal{D}$):
- 包含 ${I_i, c_i, g_i, d_i, A_i, f_i^V, f_i^T}$ 的完整条目
文本特征由$d_i$作为输入生成
|
|
假设传入一张毛绒玩具的图像,及其名字和物体类别,该阶段返回内容为:
|
|
同时保存视觉特征和文本特征向量进入database
Multimodal Retrieval
- 输入:查询图像
- 将图像的视觉向量,分别与数据库中的视觉特征和文本特征进行相似度计算
- 最终的相似度分数由两者均值得到
- 输出:top-k的候选concepts
结合两者,避免出现视觉误导
Attribute-focused CoT reasoning
|
|
- 输入:查询图像 + 候选concepts的文本描述
- 任务:模型需要列出查询图像与每个候选概念之间共同拥有的属性
- 输出:预测最佳匹配概念以及共享属性列表
这部分需要使用CoT
Cross-modal Attribute Verification
这部分的主要目的是排查模型幻觉
有些属性可能根本没有出现在图像中,造成了模型误判
- 使用文本编码器对每个共享的指纹属性进行编码
- 依次计算与查询图像的相似度
- 计算得到相似度均值最高的concept(代表共享属性和对应图像最匹配)
如果该concept就是CoT推理得到的最优concept,那么就结束算法
否则我们需要更加精确的CoT
Pairwise Reasoning
只提供了文本描述看来是不够的,我们需要结合所有信息进行昂贵的推理
保证这步确实完成任务
转化为多个二分类任务:
- 输入
- 查询图像
- 一个候选concept的原始图像+文本描述
- 输出
- VLM 输出层中 “Yes” 和 “No” Token 的置信度
因此全过程先通过检索缩小范围,再通过CoT快速筛选,最后只在属性验证失败时才调用最重的配对推理
RePIC: Reinforced Post-Training for Personalizing Multi ModalLanguageModels
RePIC: Reinforced Post-Training for Personalizing Multi-Modal Language Models
Intro
- 在多概念图像描述任务中,SFT模型的效果一般不行,依赖大量高质量数据
- 同一对象的不同视觉图片可能差异较大,特别是姿势、位置、光照、背景变化
- 整合信息时可能遗漏和不准确
Method
通过强化学习GRPO进行训练
数据集采用Subject200K以及合成数据(扩散模型生成)
提供了大量同一物体在不同光照、姿态下的多样化视觉特征
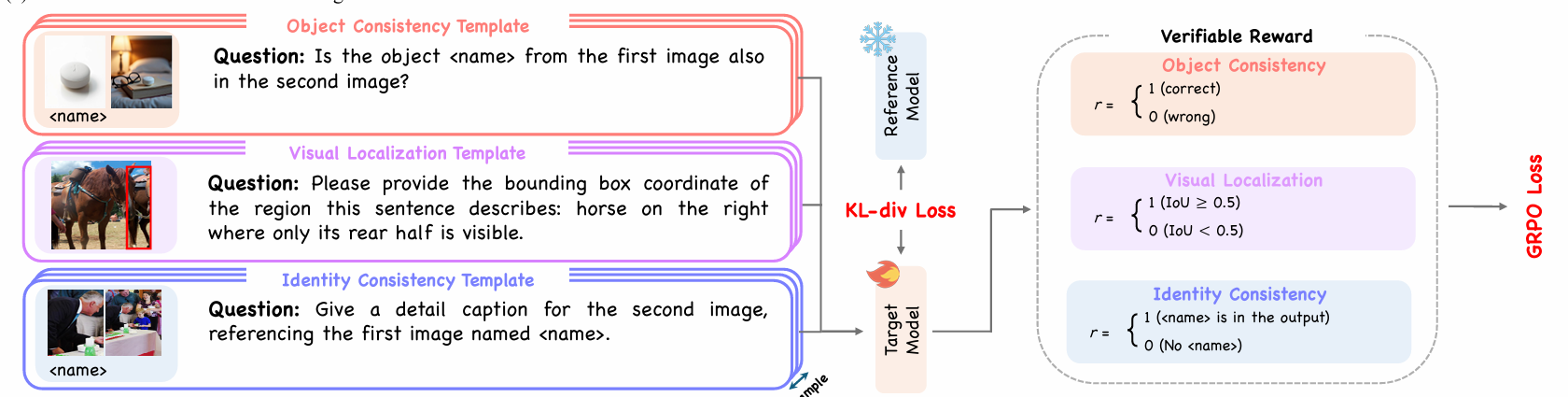
OCT - Object Consistency Tuning
- 构造正负图像对
- 正例:图像对包含相同对象
- 负例:图像对包含不同对象
- 模型回答:图像A是否包含图像B的同一个物体?
- 正例需要回答Yes
- 负例需要回答No
VLT - Visual Localization Tuning
- 模型根据指令,预测指定物体的边界框
- 若IoU大于等于0.5,给出对应奖励
ICT - Identity Consistency Tuning
- 要求模型生成一段描述,并且需要包含正确的个性化标签,如
<name> - 若场景中有m个,模型提到了n个,则获得
n/m的奖励
为了避免模型通过生成
This is <name>这种无意义的简短废话刷分要求模型至少输出100个token
PreferThinker: Reasoning-based Personalized Image Preference Assessment
PreferThinker: Reasoning-based Personalized Image Preference Assessment
Intro
- 任务:仅给少量“喜欢/不喜欢”参考图,判断候选图哪个更合用户口味
- 个性化数据极其稀缺
- 个人的喜好往往是多维度、复杂、难以描述的,无法用一个数值描述
Method
个体偏好常涉及多维度视觉要素(如艺术风格、颜色、媒介、饱和度、细节等)
远超“文本-图像对齐”或“美观度”等通用偏好所能刻画
但是组成“复杂口味”的基本组成要素,多多少少是能够列举出来的、通用的
要么喜欢“高饱和度”,要么喜欢“低饱和度”
paper根据参考图像,构建用户画像
- 喜欢:……
- 讨厌:……
按照画像进行评估与推理
Profile
- 从Lexica中提取prompt中频率最高、且对生成结果影响最大的视觉元素(15个)
- 找了 100 个受试者进行投票,让大家选出“最能代表个人偏好”的元素(缩小到5个)
结果:
|
|
Profile将基于这五个维度进行描述,但问题的关键是如何用丰富的词汇描述准这五个维度
- 针对每一个维度,都收集了大量的细粒度描述词
对于颜色,不能只是红、蓝……
应该包含“Blush Pink”(腮红粉)、“Electric Lime”(电光绿)等具体词汇

Dataset
- 模拟8w个用户
- 随机采样五个视觉偏好要素,为每个用户分配其视觉偏好画像与非偏好画像
- 真实用户可能同时具有多种偏好:为部分用户分配了多个偏好画像(2w)
- 基于profile,结合从 Lexica/COCO 等数据集里选的初始 Prompt(19w条) ,扔给 Text-to-Image进行图像生成
- 生成一组 参考图 (Reference Images):代表用户的历史喜好
- 生成两张 候选图 (Candidate Images):一张符合偏好,一张符合“厌恶偏好”
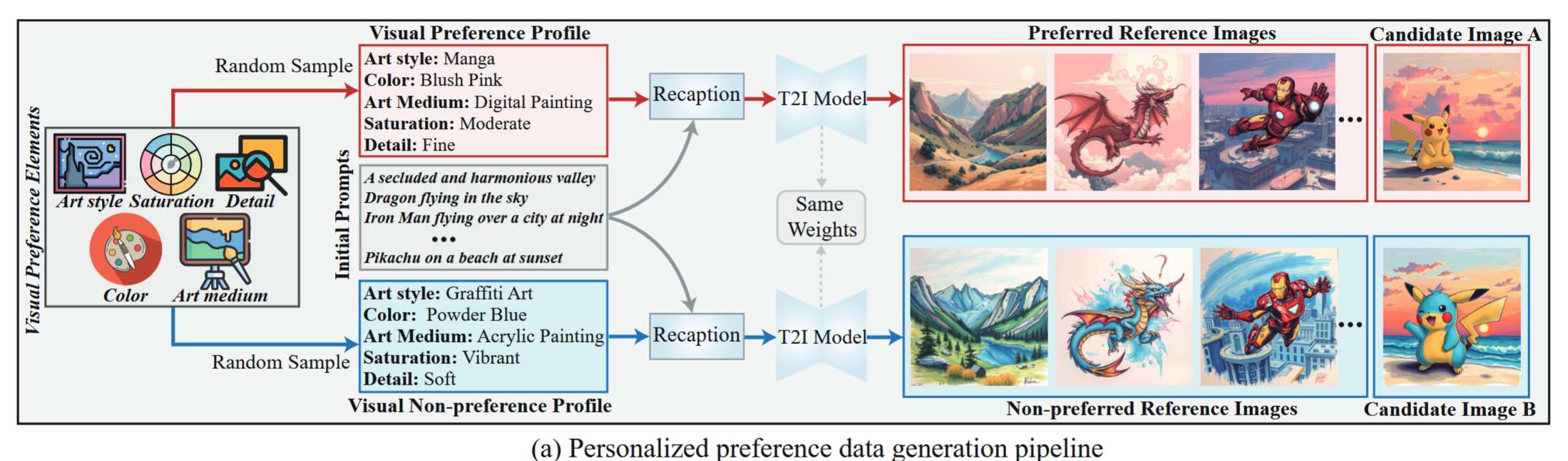
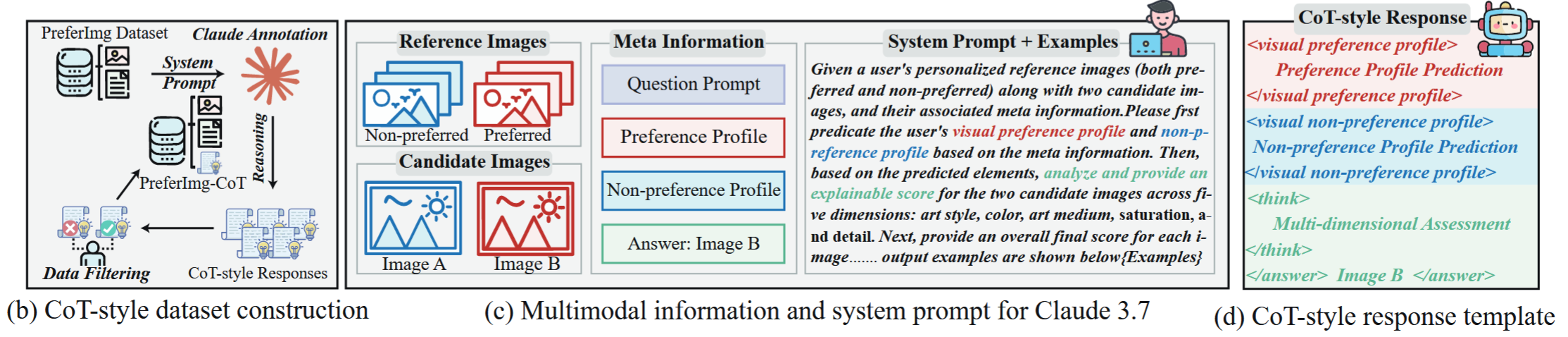
使用Claude3.7做先预测后评价
- 输入(相当于直接给了答案)
- 参考图(喜欢的 & 不喜欢的)
- 两张候选图
- 输出:(需要CoT)
- 预测:基于参考图,把用户的画像(Art Style: xxx, Color: xxx)写出来
- 评估:对比两张候选图,在 5 个维度上分别进行解释和打分
- 作答:给出A和B哪个更喜欢
对数据进行清洗:
- 偏好画像预测与真实标签明显不匹配的样本
- 结论与推理过程矛盾的样本
最后得到:60,000 名用户样本
Training……
pass