Large Language Diffusion Models
[TOC]
Intro
现象
- 扩散语言模型的Local perception
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
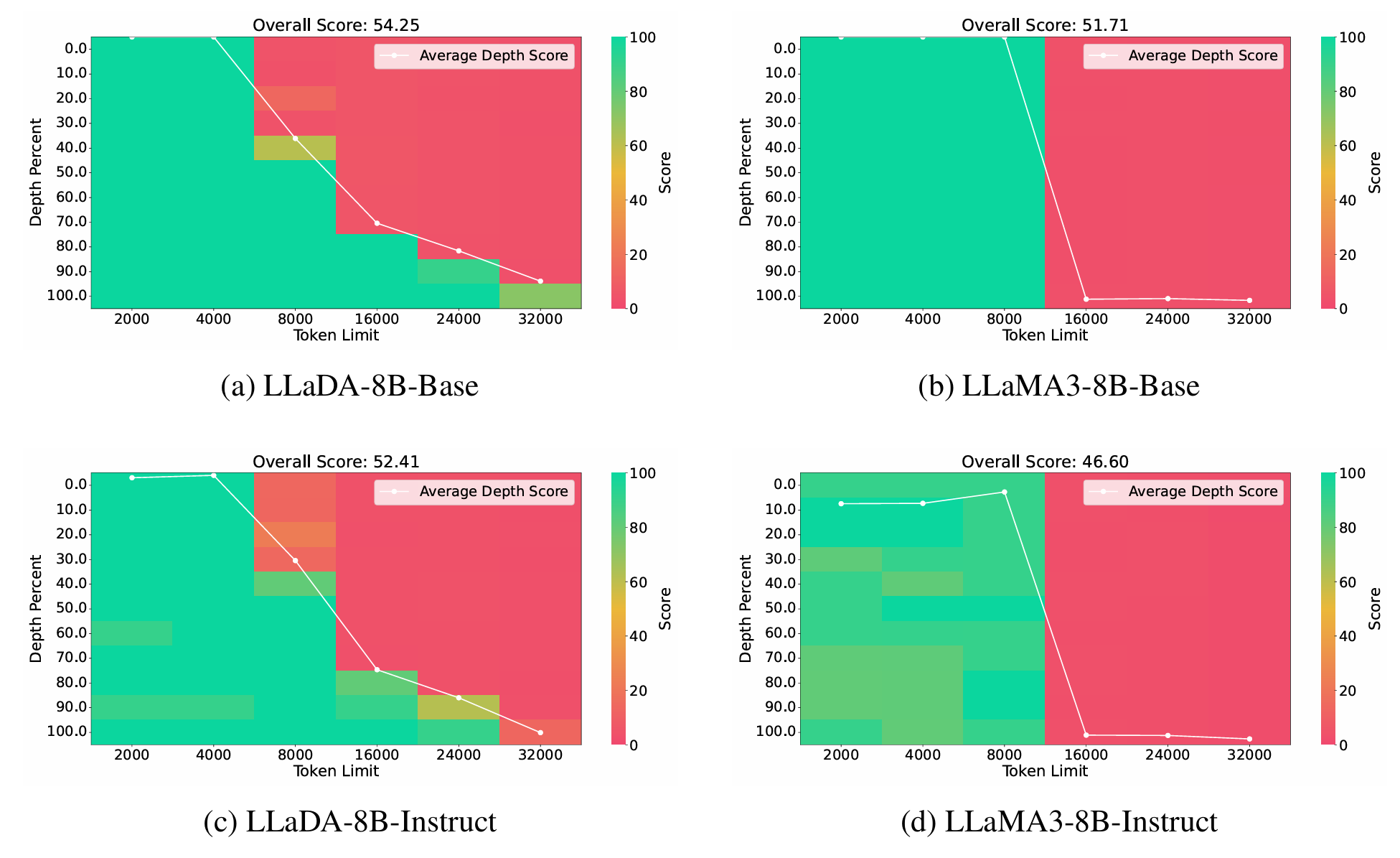
- LongLLaDA观测到这个现象是RoPE+双向上下文带来的
- 提出了一种Training Free的方法,调整了RoPE机制,提升上下文能力
关键挑战
- 如何将AR LLM的上下文扩展技术(不重新预训练)迁移到DLM
- training-free在AR方面证明了效果不如post-training,是否对DLM也是一致的
- 希望模型通过后训练,调整内部机制
核心贡献
- a Diffusion-aware NTK method
- 无需从头训练
- 受神经切线核(Neural Tangent Kernel, NTK)理论启发,开发了一个适配DLM的NTK方法
- 能适应扩散模型的迭代去噪特性,使 RoPE 可以稳定外推到 128K tokens
- 比较了后训练过程中使用的mask策略,分析对优化稳定性和长程回忆的影响
- UltraLLaDA,与LongLLaDA、LLaDA进行benchmark,证明是SOTA
Preliminary Work
-
RoPE:通过旋转向量的方式引入位置信息,旋转角度与位置index是线性关系
-
为了增加上下文,RoPE需要外推到更远的Token
- 外插:直接应用到更大的index,但是会造成信号失真与混乱(模型没见过这么大的)
- 内插:等比例缩放index到小窗口内,但是会比较模糊
-
序列位置$k$的编码向量(维度为$d$)的第$i$个分量
- NTK-Aware Scaling
定义如下:
$$ \lambda = \left(\frac{T_{target}}{T_{train}}\right)^{\frac{d}{d-2}} $$将原本的底数$\alpha$转化为$\alpha\lambda$
$$ \cos(k(\alpha\lambda)^{\frac{-2i}{d}}) = \cos(k\alpha^{\frac{-2i}{d}}\left(\frac{T_{target}}{T_{train}}\right)^{\frac{-2i}{d-2}}) $$- 低维度:$i$比较小,频率高,$\frac{-2i}{d-2}$接近1,式子近似为$\cos(k\alpha ^ {\frac{-2i}{d}})$
- 高维度:$i$比较大,频率低,$\frac{-2i}{d-2}$接近-1,式子近似为$\cos(\frac{k}{\lambda}\alpha^{\frac{-2i}{d}})$
省流:高频部分外插,低频部分内插
上面都是定性的理解
正确的公式实际是:
$$ \lambda_{baseline} = b^{-1}\cdot\left ( \frac{T_{target}}{2\pi} \right)^{\frac{d}{d_{crit}}}, d_{crit} = 2\left \lceil \frac{d}{2}\log_b \frac{T_{train}}{2\pi} \right \rceil $$b通常是10000
- 输入:$T_{target}, T_{train}$
- 输出:$\lambda$
LongLLaDA将此方法从AR LLM迁移到DLM,并且不进行后训练
Method
从最开始的现象已经说明,RoPE + 双向上下文是不可或缺的
但是LongLLaDA没有任何关于双向上下文的适配,潜力没有被开发完全
Diffusion-aware NTK in UltraLLaDA
AR和DLM能看见的上下文窗口是不一样的
- AR LLM:$[-T_{train}-1,0]$
- DLM:$[-(T_{train}-1), T_{train}-1]$
DLM的真实上下文信息应该是2倍,因此需要对NTK的输入进行修正:
- 输入:$T_{Ecap} \approx 2T_{target}, T_{cap} \approx 2T_{train}$
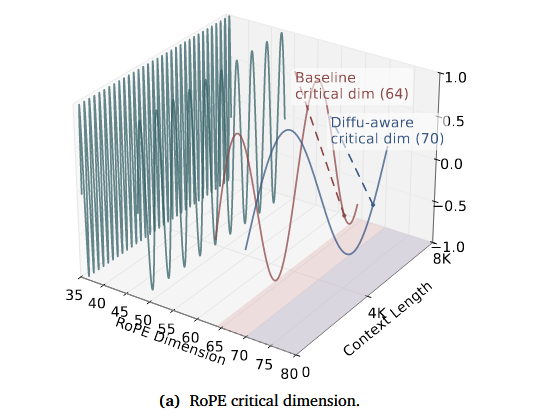
带来更小的频率,该缩放机制增加了所有维度上的RoPE周期
从而有效减缓 RoPE 旋转速度,并延长所有注意力维度上的位置波长
Case Study of Masking for Diffusion LLM Context Extension
-
后训练数据准备
- 来源:PG19
- 处理:短文档通过拼接到达64k,长文档切割成64k的chunk
-
存在问题:跨文档干扰,跨越文档边界进行注意力计算,错误吸收上下文信息
- AR:由于Causal Mask,只能看见之前的文档,天然限制了部分干扰
- DLM:能看见所有的文档,干扰非常强
-
处理策略(idea来自AR LLM)
- baseline:直接拼接,什么都不做
- Adaptive Attention Masking:只计算文档内部的注意力
- End-of-document:文档之间插入special token(并没有显式地禁止注意力跨文档),采用Full Attention
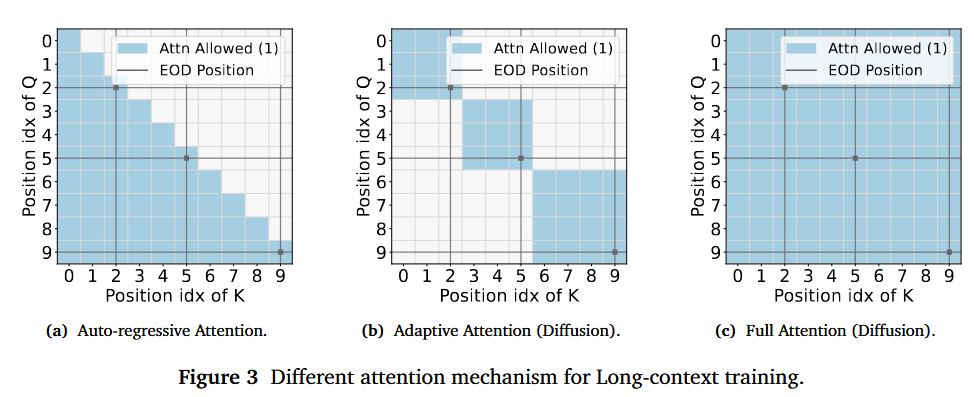
对三种策略都进行了训练(结合前文所提NTK)
训练参数:

- 对特定任务采用不同策略训练的UltraLLaDA模型
后续的实验证明:
- 采用直接拼接后训练的模型常产生不连贯结果,这可能是由于无关内容相互渗透所致
Experiments
Train-Free NTK
- 目的:在Train-Free的情况下,修正NTK的上下文长度参数输入的作用
- 方法:未做后训练,只修改编码方式进行测试
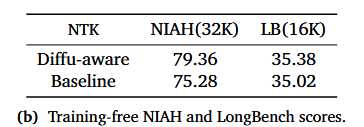
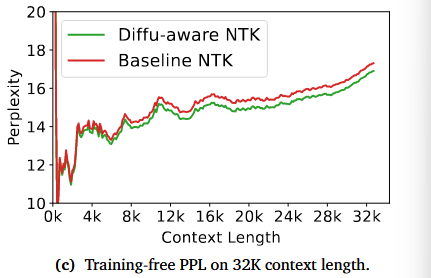
- 结论:引入双向覆盖对于扩展DLM的上下文长度至关重要
NIAH
Needle-in-a-haystack long-context retrieval task
该任务将单个相关语句嵌入长达 128K 标记的干扰文本中,要求模型准确检索目标语句
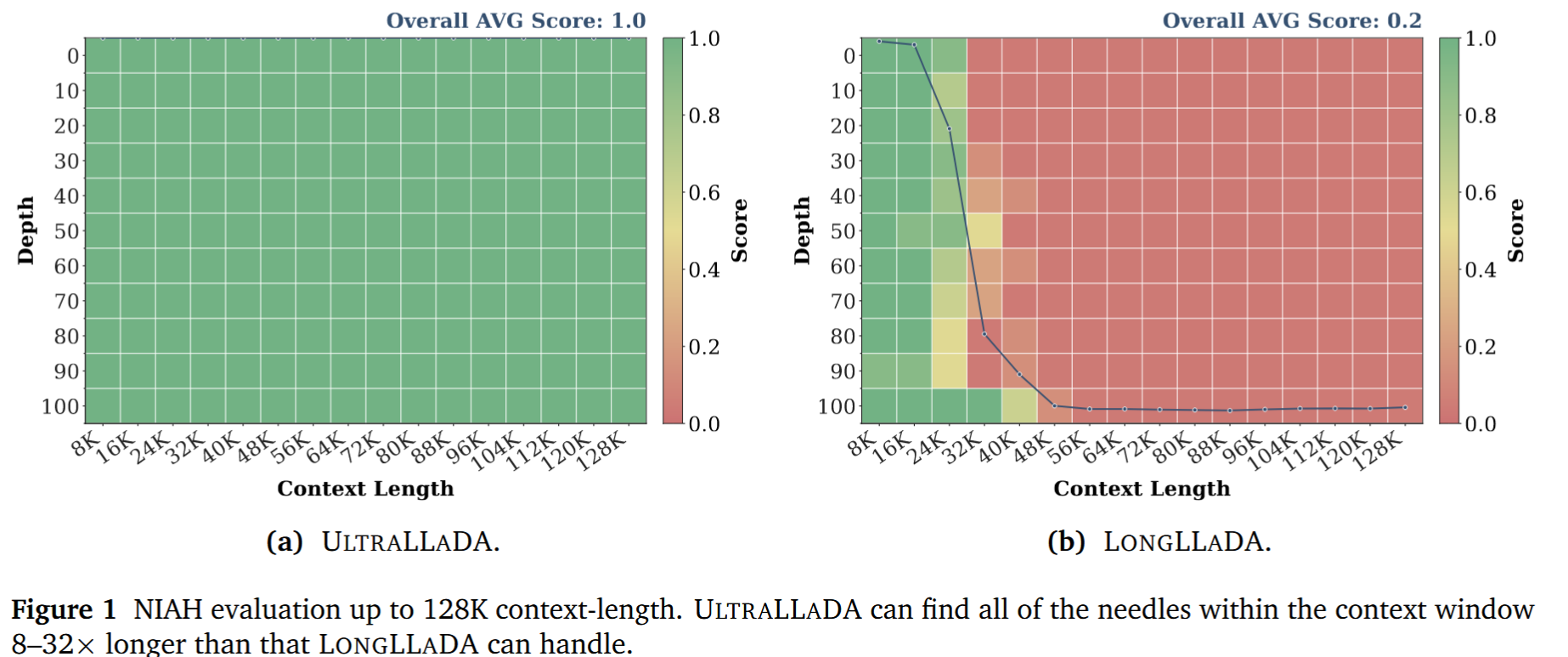
- 全部100%检索成功
由于模型缺陷,LongLLaDA 无法进行 32K 以上的评估
- 结论:后训练方法即使在极长上下文(128K)中仍能保持卓越的检索能力,而Train-Free会随上下文长度增加快速失效
PPL
- 基于PG19中128K长度的文档的语言建模困惑度评估
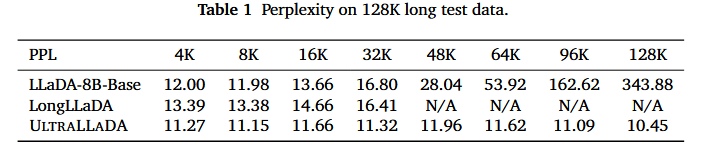
- 结论:UltraLLaDA的训练在超长序列建模中具有很强的鲁棒性
LongBench
- 截断在16K上下文长度(大部分任务只有这么长)
- 单/多文档问答、摘要、上下文学习、合成推理任务、代码补全

- 结论:长上下文训练不仅扩展了上下文长度,即使在 16K 范围内(基线模型能力范围内)也能在挑战性任务上实现质量增益
- 归因于后训练过程带来的长距离连贯性与理解能力的提升
RULER
- 在4K至32K上下文长度下(涵盖检索、聚合、问答及多跳变量追踪任务)
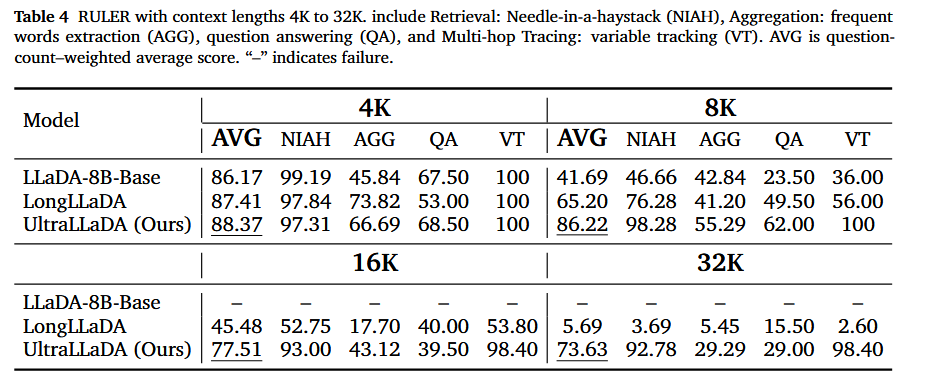
- 在检索(NIAH)和追踪(VT)类别中均展现出强劲的扩展性
- 在聚合(AGG)及部分问答任务(QA)上的提升相对有限
消融实验
- 针对NTK和跨文档策略进行消融实验
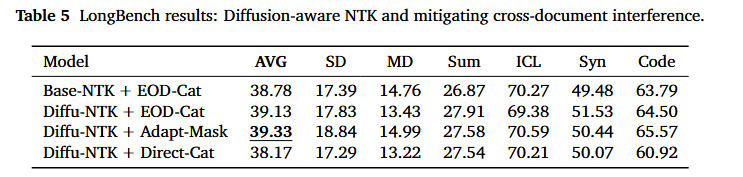
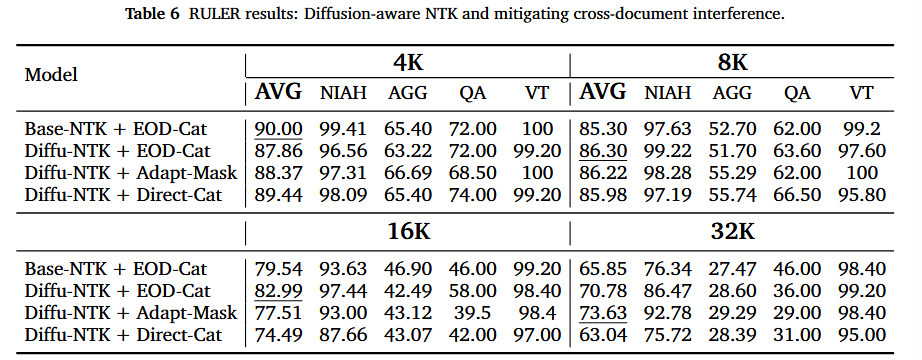
- EOD 拼接策略在较短或中等长度下表现更优
- 在更长序列中,自适应掩码策略会反超EOD拼接