Yo’LLaVA: Your Personalized Language and Vision Assistant | alphaXiv
[TOC]
Intro
Personalization
用户有时候想问的不是我该给一只狗买什么生日礼物
而是我该给我的狗买什么生日礼物
模型能够识别、理解并谈论用户特定的概念或对象
但是模型一般来说学的都是通用的内容,并不知道用户自身的setting
Yo’LLaVA
- 给定少量(几张)特定对象的照片,模型学会将该对象嵌入为一组潜在 Token(Latent Tokens)
- 比单纯的文本提示更加到位
Contribution
- 防止灾难性遗忘:Yo’LLaVA冻结了大部分的预训练参数,只针对一些特殊token
- 捕捉细粒度视觉细节:引入了困难负样本挖掘(Hard Negative Mining),即使用视觉上相似但并非该对象的图片进行训练,迫使模型学习更具辨别力的特征
Abstract
- 读入:五张个性化subject的图片
- 构造对比学习:检索clip相似的若干图片和随机图片,进行recognition训练(带图)
- 构造对话文本数据:使用LLaVA对图片进行描述,生成通用对话文本,进行纯文本训练
- 输出:能够识别图片中的subject和直接描述subject的模型
Related Work
Soft Prompt Tuning
Soft Prompt Tuning 并不修改预训练模型的核心权重,而是通过在输入端引入一组可学习的Tokens来进行优化
Method
Yo’LLaVA的目标是只给若干张subjec的图片,能够做到
- 通过视觉识别subject
- whether
is in a photo or not
- whether
- 支持关于subject的VQA任务
- ask about
<sks>’s location
- ask about
- 缺乏图片输入的情况下,在纯文本环境中回答subject的视觉特征
- ask questions about intrinsic attributes of
<sks>like its color, shape
- ask questions about intrinsic attributes of
Personalizing the Subject as a Learnable Prompt
为了识别图片中是否存在特定的subject
native的做法是:使用prompt详尽地描述subject的每一个细节,但要么很困难要么做不到
需要引入Soft Prompt Tuning,对Prompt层进行学习
|
|
- 只需要增加几个新的token和对应输出权重
- 不需要修改MLMs的预训练权重
因此,对于参数的变化总结为:
- 输出层增加的参数:最后输出的分类头参数矩阵由$C\times N$扩展到$C\times (N+1)$
- $C$表示上一个hidden feature的维度
- $N$表示词表维度
<token1><token2>. . . <tokenk>Prompt层中的可学习token,以及<sks>
定义可训练的参数:
$$ \theta = \left\{\text{构造大量对话文本$(I,X_q,X_a)$,分别表示图片、提问、标准回答,进行训练
从而让模型学习到新的concept(注意冻结其他参数)
Enhancing Recognition with Hard Negative Mining
对于识别问题,比较简单的训练方式就是询问subject是否在图片中
显然不能全是正例,不然会训崩
paper从LAION中抽样了100张图片作为负例,混合训练

同时我们需要避免模型过度泛化
subject:yellow + dog
model: any yellow animal
为了增强训练,paper采用了hard negative mining的方法
- 若subject是一只毛绒狗,则负例应该选择其他不是狗的毛绒动物

因此最后训练数据图片的组成为:
- 100张随机抽取
- 100张通过CLIP计算相似度得到top-m张图(m=100)
- 正样本(5张左右)
然后paper构造了30条左右的prompt,以不同方式询问与回答:<sks>在图里吗?
Learning to Engage in Natural Conversations about the Subject
通过上述算法,模型掌握了识别的能力,但未必掌握了如何描述subject:Describe <sks> in detail.
因此需要进一步训练,使得模型能够在对话中熟悉掌握subject的本质特性
paper定义了10份通用对话模板,分为人类、物体两种(方便套用任何需要进行个性化训练的subject)
避免过于细节的问题,例如:subject的尾巴是什么颜色的?
显然不是所有物体都有这个特征
对于每一张图像,使用LLaVA针对问题生成回答,完成数据集构建
为了让模型真实地记住subject的特征,避免模型通过图像泄露得到答案
这一阶段训练是纯文本的,只使用问题-答案对进行训练
Experiment
Train
对于单个subject,使用5张图像作为输入,软提示的视角token数量设定为16
使用LLaVA-1.5-13B,进行单轮对话训练,GPU选择单卡A6000
Dataset
数据集的初始构建由40个subject构成:Person (10), Pets (5), Landmarks (5), Objects (15), and Fiction Characters (5).
每个subject含有10-20张图片,切分为训练集和测试集
Baselines
- Naive LLaVA
- LLaVA + Prompt:通过提示词提供subject信息给LLaVA
- GPT-4V
- +Prompt
- +Images(GPT-4V支持多轮图像对话,因此可以提供多个subject的图片,单张图片1k token)
图片信息显著比文本提示更加丰富,因此GPT-4V+Images应当是性能的理论上界(提供了充足的描述)
文本提示的获得方法:
- 人工(约 16 token)
- 模型生成
为了方便对比,准备了两组文本提示词:
- 拼接人工+模型生成(约1.3k的token)
- 模型再总结(约16 token)
Results
Recognition Ability
- 40 个主体,每个主体有 5 到 10 张包含该对应主体的test图像
- 对于每个主体,其所有的测试图像均作为正样本,而来自其余 39 个类别的测试图像则作为负样本
- 总共有 333 个正向测试样本和 13,320 个负向测试样本
实验提供图像+问题Can you see if <sks> is in this photo? Answer with a single word or phrase.
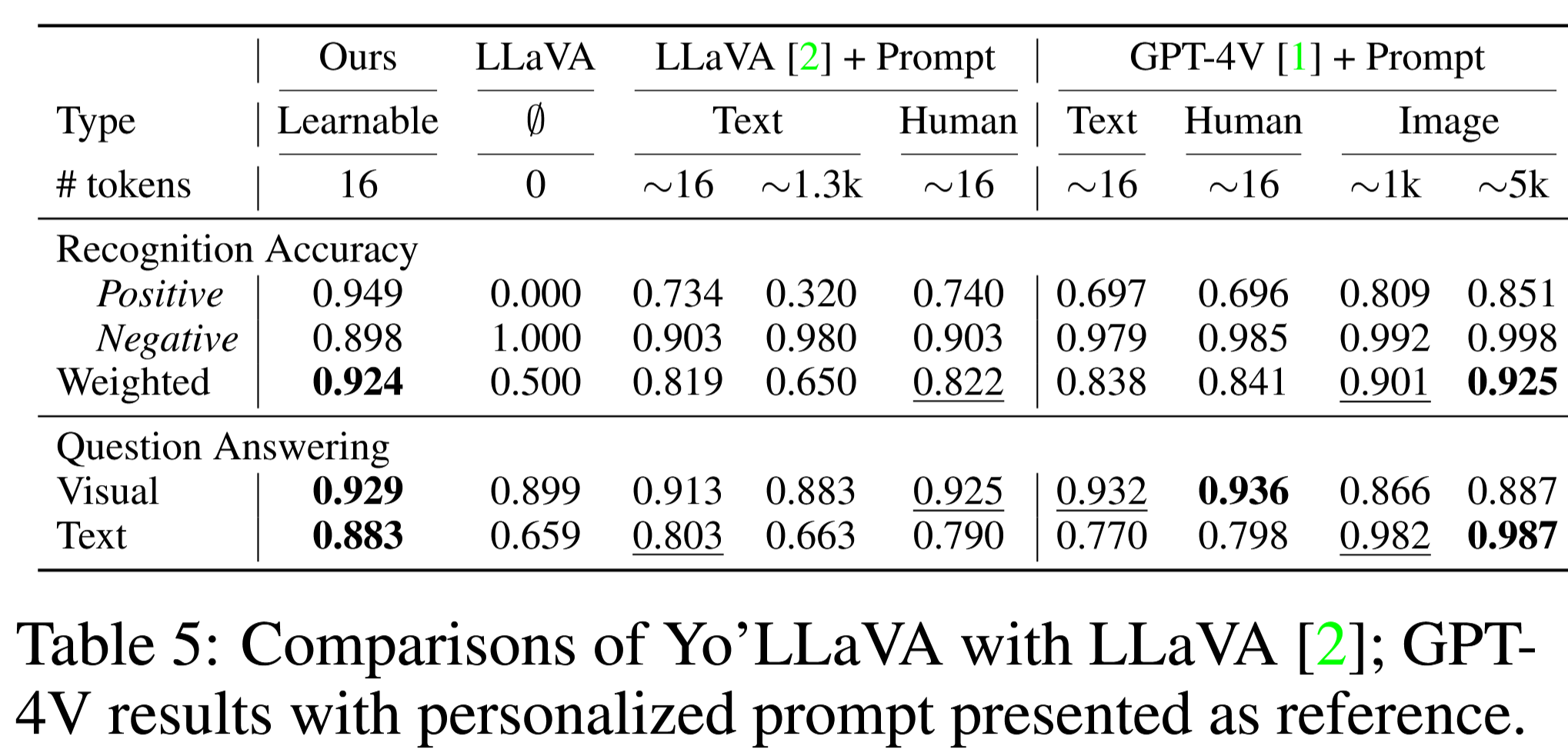
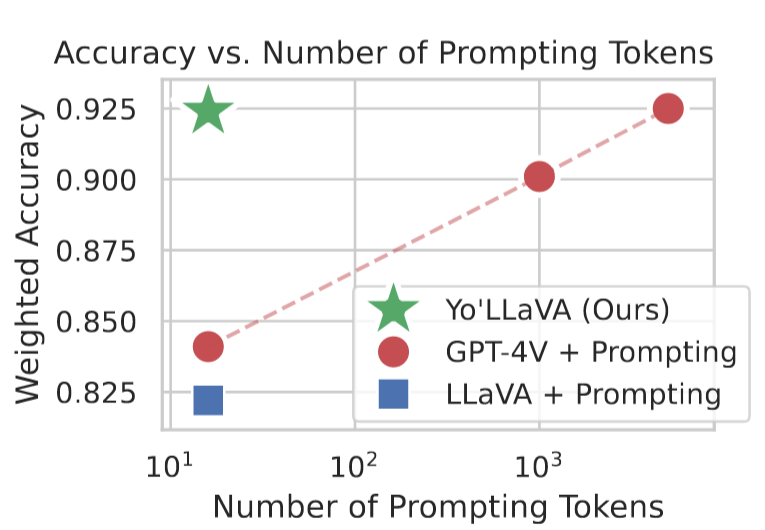
Weighted是正负样本准确率的均值
- 过长的描述会对性能产生负面影响(即使用 1.3k 个 token 仅达到 0.650),可能描述了多余内容
- 给出的参考图像越多,性能越好
Question Answering
准备了多道A或者B的选择题
- 171道视觉(基于图片提问)
- 400纯文本
Comparison with MyVLM

Ablation Studies
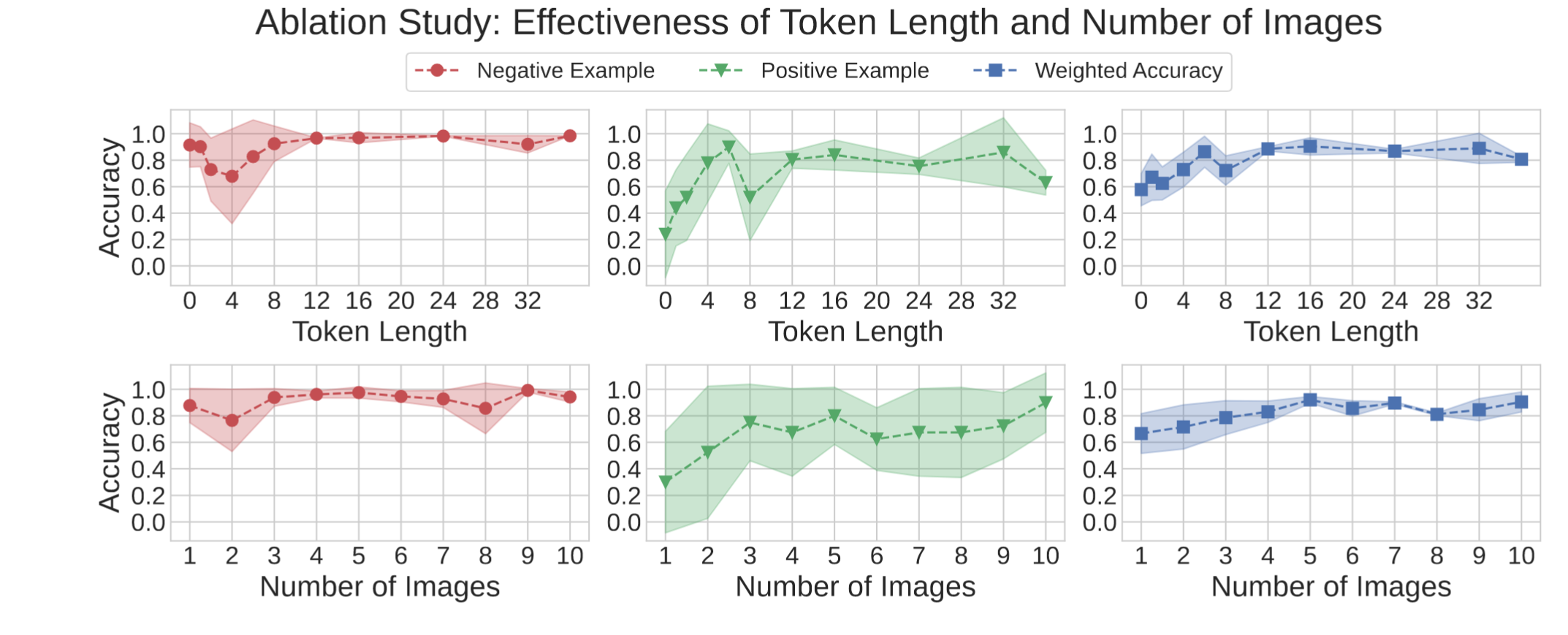
-
对Prompt的可学习token长度的消融:越长越好,为了均衡性能,选择16
-
对subject传入的图像数的消融:越多越好,选择5
-
数据集构建消融
- 纯LLaVA:
- 识别能力随机
- 描述能力完全不行
- 构造识别数据:
<sks>是否在图中?- 识别能力提升
- 描述能力完全不行
- 构造文本对话数据
- 识别能力略微提升
- 描述能力具备
- 构造Hard Negative样本
- 识别能力显著提升
- 描述能力具备
- 纯LLaVA:
